
Last updated on 17th Jun 2025| 10946
- Definition of Data Mining
- Definition of Statistics
- Historical Background
- Key Differences
- Overlapping Areas
- Use Cases of Data Mining
- Use Cases of Statistics
- Tools Used in Each Field
- Data Handling Techniques
- Algorithms vs Theoretical Models
- Industry Relevance
- Choosing the Right Approach
- Conclusion
Definition of Data Mining
Comparing Data Mining and Statistics first Data Mining is the process of discovering hidden patterns, correlations, anomalies, and insights from large datasets using computational algorithms and techniques. It is an interdisciplinary field combining computer science, machine learning, database systems, and statistics to extract useful information from raw data. The main goal of data mining is to transform vast amounts of raw data into meaningful knowledge that can support decision-making, prediction, and pattern recognition in various domains such as marketing, finance, healthcare, and more.
Definition of Statistics
Comparing Data Mining and Statistics second Statistics. Statistics is the science of collecting, analyzing, interpreting, presenting, and organizing data.
It provides theoretical foundations and mathematical tools to describe data distributions, test hypotheses, infer relationships, and quantify uncertainty. Statistics focuses on making sense of data by summarizing it, drawing conclusions, and making predictions based on probability theory and mathematical models. It often deals with smaller or sampled datasets to infer properties about a larger population.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Historical Background
- Statistics: The roots of statistics trace back to the 17th and 18th centuries with the development of probability theory by mathematicians such as Pascal and Bernoulli. Its initial applications were primarily in government census data, insurance, and quality control. Over the centuries, statistics evolved to include hypothesis testing, regression analysis, experimental design, and multivariate techniques.
- Data Mining: Emerging in the late 20th century, data mining developed alongside advances in computing power and the explosion of digital data. It integrates concepts from machine learning, databases, and AI, enabling automated pattern discovery in massive datasets that were previously impractical to analyze using classical statistical methods.
- Market Basket Analysis: Retailers identify product purchase patterns to design promotions.
- Fraud Detection: Banks use data mining to detect unusual transaction patterns.
- Customer Segmentation: Businesses cluster customers based on buying behavior.
- Sentiment Analysis: Social media data mining uncovers public opinion.
- Predictive Maintenance: Manufacturing firms predict equipment failure to avoid downtime.
- Recommender Systems: Streaming platforms suggest content based on user preferences.
- Clinical Trials: Medical researchers use statistics to evaluate drug efficacy.
- Quality Control: Manufacturers apply statistical process control to maintain standards.
- Survey Analysis: Governments analyze census and survey data for policy making.
- Risk Assessment: Insurance companies calculate premiums based on statistical models.
- Experimental Design: Scientists use statistics to design valid experiments and interpret results.
- Economic Forecasting: Economists predict trends and impacts using statistical models.
- Data Mining: Emphasizes handling massive, often unstructured datasets. Techniques include data warehousing, ETL (Extract, Transform, Load), dimensionality reduction, feature selection, and anomaly detection.
- Statistics: Often works with smaller, well-defined datasets. Emphasizes sampling techniques, data cleaning, normalization, and ensuring data quality for valid inference.
- Data Mining Algorithms: Theoretical Models of Heuristic or optimization-based procedures designed for pattern detection and prediction without always relying on formal proofs. Examples include k-means clustering, decision trees, neural networks, and association rule mining.
- Statistical Models: Rely on well-established mathematical foundations and probability theory. Examples include linear regression, generalized linear models, ANOVA, and time series models.
- When working with large, complex, or unstructured datasets.
- When the goal is prediction, classification, or discovering unknown patterns.
- When automation and scalability are priorities.
- When hypothesis testing, estimation, and inference are primary goals.
- When working with well-defined samples or experimental data.
- When interpretability and rigorous validation are critical.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Key Differences
| Aspect | Data Mining | Statistics |
|---|---|---|
| Primary Focus | Extracting patterns and knowledge from large, complex datasets | Summarizing, modeling, and inferring from data |
| Data Size | Typically large, often big data or databases | Smaller, sampled datasets or structured data |
| Methodology | Automated algorithms, machine learning, heuristics | Formal mathematical models, inference, probability |
| Goal | Prediction, classification, pattern discovery | Explanation, hypothesis testing, estimation |
| Data Type | Structured and unstructured (text, images, etc.) | Mostly structured numerical or categorical data |
| Tools & Techniques | Decision trees, clustering, association rules, neural networks | Regression, ANOVA, hypothesis tests, confidence intervals |
Overlapping Areas
Despite being distinct disciplines, data mining and statistics share several characteristics. Both focus on analyzing data to extract meaningful insights, and data mining often employs a variety of statistical techniques, such as regression, clustering, and Bayesian inference. They also employ models similarly for prediction and classification tasks. Additionally, data preparation which includes preprocessing, cleaning, and transformation is an essential step in both fields. Furthermore, visualization is essential; charts and graphs effectively interpret and convey results. Because of these overlaps, experts in both domains typically collaborate and employ complementary strategies to enhance data-driven decision-making.

Use Cases of Data Mining
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Use Cases of Statistics
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Tools Used in Each Field
Data mining and statistical analysis make use of a wide array of powerful tools and platforms. When it comes to data mining, RapidMiner really shines as a visual platform for creating data mining workflows, while WEKA provides an open-source collection of machine learning algorithms. KNIME offers a well-rounded environment for data analytics, reporting, and integration, and Apache Mahout is great for scalable machine learning applications. Popular Python libraries like scikit-learn, TensorFlow, Keras, and PyTorch are commonly used for advanced modeling, while R packages such as caret, randomForest, and e1071 deliver strong capabilities for predictive tasks. In the world of statistical tools, R stands out as a comprehensive environment for statistical computing, and SAS provides advanced commercial analytics solutions. SPSS is often preferred for its user-friendly interface, particularly in the social sciences, while Stata excels in supporting data analysis and statistical modeling. Lastly, MATLAB, with its statistics toolbox, offers a robust numeric computing environment that’s perfect for a variety of statistical applications.
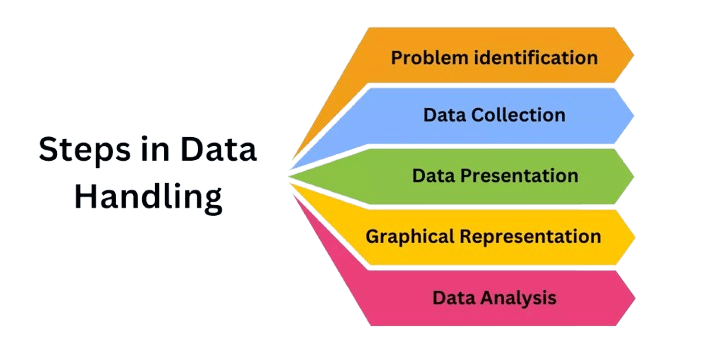
Data Handling Techniques
Algorithms vs Theoretical Models
Data mining algorithms may sacrifice interpretability for predictive power, while statistical models often prioritize inference and understanding relationships.
Industry Relevance
Data mining is essential to sectors like technology, e-commerce, telecom, finance, and healthcare analytics that handle enormous volumes of data. It is commonly used to get customer insights, detect fraud, and provide personalized experiences. Nonetheless, statistics are crucial in domains that demand precise inference and meticulous experimental design, such as government research, industry, public health, and pharmaceuticals. As data-driven decision-making becomes increasingly important across industries, statistics and data mining are becoming increasingly integrated. For more reliable and perceptive results for Comparing Data Mining and Statistics, organizations are using hybrid approaches that blend statistical rigor with predictive abilities.
Choosing the Right Approach
When to use Data Mining:
When to use Statistics:
In practice, organizations benefit most from integrating both approaches depending on the problem context.
Conclusion
Comparing Data Mining and Statistics are complementary disciplines that together enable a holistic approach to data analysis. Data mining excels at uncovering hidden patterns in vast datasets with algorithmic efficiency, while statistics provides a solid theoretical framework for making reliable inferences and understanding data relationships. Professionals equipped with skills from Comparing Data Mining and Statistics are well-positioned to harness data for strategic advantage across industries.




