
Last updated on 08th Aug 2025| 12179
- What is Reinforcement Learning?
- Basics of Q Learning
- Q-Table and Q-Values
- Exploration vs Exploitation
- Q Learning Algorithm
- Environment and Rewards
- Applications (e.g., Game AI)
- Summary
What is Reinforcement Learning ?
Reinforcement Learning in Machine Learning Training where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards. Unlike supervised learning, where the model is trained on labeled data, Bellman or unsupervised learning,Q Learning Algorithm where patterns are discovered from input data, reinforcement learning operates based on feedback from the environment. At the core of reinforcement learning is the trial-and-error method. An agent interacts with its environment in discrete time steps. At each step, it observes a state, chooses an action, receives a reward, and transitions to a new state. The goal is to learn a policy mapping from states to actions that maximizes the expected reward over time.RL is inspired by behavioral psychology, Reinforcement Learning in machine learning mimicking how humans and animals learn through consequences.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Basics of Q-Learning
Q-Learning is a foundational reinforcement learning algorithm that focuses on learning the value of action-state pairs, known as Q-values. It is model-free, meaning it does not require knowledge of the environment’s dynamics.The Q-value, Q(s, a),Reinforcement Learning in What Is Machine Learning, supervised represents the expected cumulative reward of taking action in state s and then following the optimal policy thereafter. Q Learning Algorithm aims to learn the optimal Q-values that satisfy the Bellman Optimality Equation.
Key Characteristics:
- Off-policy: It learns the optimal policy regardless of the agent’s actions during training.
- Value-based: It estimates values rather than policies directly.
- Tabular Method: Initially implemented with a Q-table for discrete states and actions.
Q Learning has been successfully used in various applications, from playing games to controlling robots.
Q-Table and Q-Values
- Definition: Q-Values (or action-value functions) represent the expected future rewards of taking a specific action in a given state, and then following the optimal policy.
- Notation: Q(s,a)Q(s, a)Q(s,a).Where sss is the current state, and aaa is the action.
- Purpose: Helps the agent evaluate which action is better in a given state to maximize total reward over time.
- Updating Q-Values: Q(s,a)←Q(s,a)+α[r+γmaxQ(s′,a′)−Q(s,a)]Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max Q(s’, a’) – Q(s, a)]Q(s,a)←Q(s,a)+α[r+γmaxQ(s′,a′)−Q(s,a)]
Q-Table
- Definition: Bagging vs Boosting in Machine Learning data structure (typically a matrix) used to store Q-values for every state-action pair in a finite environment.
- Structure: Rows represent states, columns represent possible actions.
- Each cell stores a Q-value: Q(s,a)Q(s, a)Q(s,a)
- Purpose: Guides the agent’s decisions to choose the action with the highest Q-value in the current state.
- Limitations: Becomes impractical in environments with large or continuous state/action spaces (this is where Deep Q-Learning comes in).
- Exploration involves the agent trying new, untested actions to gather information about the environment. By exploring, the agent can discover potentially better strategies or rewards that were previously unknown. This helps prevent the agent from settling prematurely on suboptimal choices and encourages learning the best possible policy.
- Exploitation means the agent uses its current knowledge to choose actions that yield the highest known rewards. By leveraging what it has already learned, the agent aims to maximize immediate returns. However, focusing only on exploitation can limit learning if the agent misses better options available through further exploration.
- With probability ε, the agent explores (chooses a random action).
- With probability 1 – ε, it exploits (chooses the best-known action).
- Initialize The Q-table with zeros or random values.
- For each episode: Initialize the state.
- Repeat until terminal state: Choose action a using ε-greedy.Take action a, observe reward r and next state s’.
- States: All possible configurations of the system.
- Actions: What the agent can do.
- Rewards: How the agent is scored.
- States: Grid cells.
- Actions: Move up/down/left/right.
- Rewards: +10 for reaching the goal, -1 for each move, -100 for falling in a trap.
- Game AI: Teaching agents to play games like Tic-Tac-Toe, Snake, or even complex ones like Atari games.AlphaGo combined Q-learning with deep neural networks.
- Robotics: Navigation, object manipulation, and dynamic path planning.
- Recommendation Systems: Top Machine Learning Algorithms Adaptive user modeling and content recommendations.
- Traffic Signal Control: Optimizing green light timings based on traffic conditions.
- Finance: Trading strategies, portfolio management, risk-aware decision-making.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Exploration vs Exploitation
A major challenge in Reinforcement Learning in Machine Learning Training is balancing exploration and exploitation:
Exploration:
Exploitation:
ε-Greedy Strategy:
Over time, ε is often reduced (annealed), allowing the agent to exploit more while still exploring enough to avoid local optima.

Q-Learning Algorithm
The Q-Learning algorithm is simple and iterative. Q-Learning is a model-free reinforcement learning algorithm used to find the optimal action-selection policy for an agent interacting with an environment. Applications of Artificial Intelligence It learns the value of taking a specific action in a given state by updating a Q-value table based on the rewards received and the estimated future rewards. Through repeated exploration and exploitation, the algorithm converges to the best policy that maximizes cumulative rewards without needing a model of the environment’s
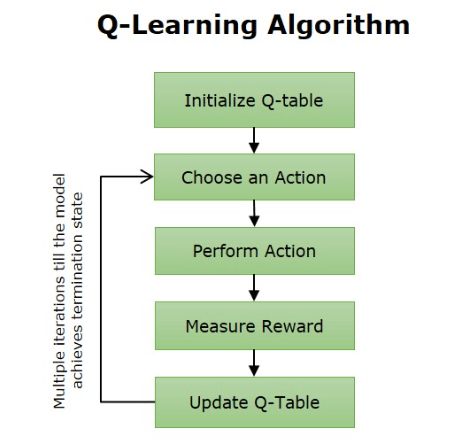
Repeat for many episodes until Q-values converge.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Environment and Rewards
Data Science Career Path The environment is the problem space where the agent operates. It defines:
Example (Maze Navigation):
A well-designed reward structure is crucial to guiding supervised learning.
Applications of Q-Learning
Q Learning Algorithm has been used in various fields:
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Summary
Reinforcement Learning in machine learning empowers agents to learn optimal behaviors through interaction with an environment. Q-Learning Exploitation, a foundational algorithm in RL, supervised Learning enables agents to discover the best actions using a value-based method and the Bellman Equation. By maintaining and updating a Q-table, agents gradually converge toward optimal policies. However, Q-Learning is best suited for small, discrete environments. For complex or continuous tasks, extensions like Deep Q-Learning or Actor-Critic methods are more appropriate. Understanding the nuances of reward structures, exploration strategies, and the trade-offs between algorithms like Q Machine Learning Training Algorithm and SARSA is essential for building intelligent agents. From simple grid-worlds to advanced game AI, the principles of Q-Learning remain a cornerstone of modern reinforcement learning.




