
Last updated on 23rd Apr 2025| 11103
- Introduction to the AI Project Cycle
- Step 1: Problem Definition
- Step 2: Data Collection and Preparation
- Step 3: Model Selection
- Step 4: Model Training
- Step 5: Model Evaluation
- Step 6: Deployment and Monitoring
- Conclusion
Artificial Intelligence (AI) revolutionizes industries by equipping machines to perform tasks that previously needed human intelligence. Artificial intelligence is reshaping business activities and providing services in healthcare to finance. Still, to utilize its complete capabilities, it is essential to work through a predetermined process called the “AI Project Cycle.” Such a cycle entails several phases with specific tools, techniques, and expertise required at each stage. Data Science Course Training blog will guide you through the cycle of an AI project, dividing each step into achievable steps. The cycle starts with problem definition, data collection, preprocessing, and model selection. Then, the model is trained, tested, and implemented for real-world application. Monitoring and continuous improvement are also required to keep the model running well. Whether you’re just starting or an experienced data scientist, this guide will provide valuable insights into effectively planning, implementing, and deploying AI solutions, helping you build efficient and impactful AI models.
Introduction to the AI Project Cycle
The AI project lifecycle is a formalized process that directs the creation of AI solutions so that the models are practical and helpful in solving real-world issues. The lifecycle offers a step-by-step process of working through the intricacies of AI development, usually encompassing domains like machine learning, natural language processing (NLP), and computer vision. Data Cleaning is iterative, with ongoing refinement and enhancement based on feedback and outcomes from the previous steps. This loop enables the developer to improve the accuracy and efficiency of the model over time. Although different processes are applicable depending on the type of project or technology employed, the overall steps of the AI project cycle remain uniform. Significant steps generally involve problem formulation, data collection, preprocessing, choosing the right algorithms, training the model, performance evaluation, and deployment in real-world scenarios. Models may also need monitoring and machine learning after deployment to cope with new data or changing circumstances. By taking a simple, structured approach to AI development, teams can better ensure that they develop successful, scalable, and reliable AI solutions, positioning them well to solve complex problems in multiple industries.
Learn the fundamentals of Data Science with this Data Science Online Course .
Step 1: Problem Definition
As a precursor to data gathering or model creation, defining the problem is the most essential and initial step. Problem understanding enables teams to, Determine the scope of the project. Define the desired outcomes. Choose the proper AI techniques
Key Considerations:
- Business Goals: What are the business objectives behind solving this problem? AI solutions should align with these goals.
- Specificity:State the problem as clearly as Calculator Using Javascript . A poorly defined problem will result in ambiguous requirements and mediocre solutions.
- Feasibility: Determine if the problem is solvable with AI. Not every situation is appropriate for AI-based solutions.
- Data Sourcing: Identify data sources to be utilized to resolve the problem. This can include internal company data, public data sets, or third-party data vendors.
- Data Cleaning: Raw data is usually not usable. Compare Two Columns in Excel must be cleaned to remove errors, outliers, or irrelevant data.
- Data Transformation: Data needs to be transformed into a format suitable for modeling, such as normalization or encoding categorical variables.
- Feature Engineering: The job here is to invent new features or modify existing ones to enhance model performance.
- Supervised Learning: Here, the model is trained on labeled data, and input-output pairs guide the model in understanding Checkbox in Excel relationship.
- Unsupervised Learning:The model trains without labels and identifies patterns or groupings of data. The model is generally used for clustering or identifying outliers.
- Reinforcement Learning:In this method, an agent learns by interacting with an environment and receiving rewards or penalties for actions.
- Training Data: Split the data into training and test sets. The training set is used to train the model, while the test set is used to evaluate it.
- Hyperparameter Tuning: Models contain parameters that control how they behave. Adjusting their hyperparameters can significantly improve performance.
- Overfitting and Underfitting: Be careful not to overfit (where the model is very accurate on training data but is low-precise on new data) and underfit (where the model is too simple to learn the complexity of the Data Science Course Training).
- Optimization: Optimization methods, such as gradient descent, minimize errors during training, making the model more accurate.
- Accuracy: The percentage of correct predictions made by the model.
- Precision and Recall: These metrics are beneficial in imbalanced datasets where one class is more prevalent than the other.
- F1 Score: The harmonic mean of precision and recall, often used when Remove Duplicates in Excel a need to balance both.
- AUC-ROC Curve: A graphical representation of a model’s ability to distinguish between classes.
- Scalability: Ensure that the model can handle increasing volumes of data and requests without degradation in performance.
- Real-time vs. Batch Processing: Depending on the use case, AI models may need to operate in real time or Boyer Moore Algorithm in batches at regular intervals.
- Model Monitoring: AI models are not static; they need to be monitored and updated regularly. Continuous monitoring helps identify performance issues and allows for adjustments as needed.
A well-defined problem provides the basis for the remainder of the AI project, guaranteeing the solution fulfills stakeholders’ requirements.
Step 2: Data Collection and Preparation
The second task following the problem definition is data collection and preparation. Data is the basis of any AI solution, and the quality of your model depends heavily on data quality and quantity.
Key Tasks in Data Collection and Preparation:
Data preparation is most important since data quality is so essential that it can create imprecise or inefficient AI models.
Dive into Data Science by enrolling in this Data Science Online Course today.
Step 3: Model Selection
Once one has data, the second step is selecting the right AI model. Different problems must be solved differently, and the right model selection is crucial to the project’s success.
Types of AI Models:
The appropriate model is selected based on the type of problem, data provided, and kind of solution needed. The relevant model selection ensures that the solution effectively solves the problem.

Step 4: Model Training
After selecting a model, the subsequent step is training it on the prepared data. Training is the phase where the model learns data patterns to predict or make decisions.
Key Considerations in Model Training:
Model training can be computationally intensive and time-consuming, especially for complex models like machine learning networks.
Take charge of your Data Science career by enrolling in ACTE’s Data Science Master Program Training Course today!
Step 5: Model Evaluation
Once the model has been trained, it is time to evaluate its performance. This step is crucial to understanding how well the model can generalize to new, unseen data.
Common Evaluation Metrics:
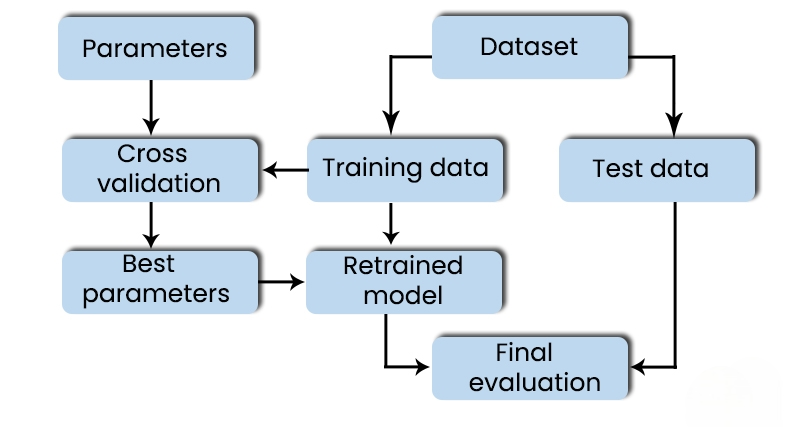
Evaluation is an ongoing process that continues even after deployment. Continuous monitoring and re-evaluation are necessary to maintain model accuracy over time.
Want to ace your Data Science interview? Read our blog on Data Science Interview Questions and Answers now!
Step 6: Deployment and Monitoring
After a successful evaluation, the AI model is ready for deployment. Deployment involves integrating the AI model into the business process or product so that end users or other systems can access it.
Key Aspects of Deployment:
Once deployed, the AI model should be continuously tested in the real world to ensure it meets the intended objectives and performs well in live environments.
Conclusion
It takes rigorous planning, execution, and continuous management to build AI solutions. Teams can navigate each step with the support of the AI project cycle’s defined framework, which keeps the project on schedule. A good problem definition is essential because any successful AI project starts with a thorough understanding of the challenge. Without a well-defined goal, the entire process may be aimless. Data is then essential. Any AI model is built on top of relevant and high-quality data. To ensure the model can learn from the data efficiently, adequate time must be dedicated to data collection, machine learning , and preparation. Model selection is another key aspect; choosing the right model based on the specific problem and available data is vital, and remember that experimentation with different models is often necessary to find the best fit. Once the model is selected, Data Science Course Training essential to evaluate and optimize it by thoroughly testing and refining it using appropriate performance metrics. Finally, post-deployment, continuous monitoring is necessary to ensure the AI model remains effective and continues to provide value as it encounters new data and challenges. By following the AI project cycle, organizations can improve their chances of developing AI solutions that are not only technically robust but also aligned with business goals and user needs.




