
Last updated on 13th Jul 2020| 2666
R:
A good data scientist is the one who is a passionate coder along with an intelligent statistician and for statistics, there is nothing as good as R. Because of its power of statistics, R is also called as the golden child of data science. The data scientists skilled with R are being looked upon by the biggest brands like Facebook, New York Times and Google, etc.
Some of the major reasons why you should learn R are as follows:
- R is freely available: Unlike other languages like SAS or Matlab, R is free to install and use. You need not buy any premium license to use it.
- R is an open-source programming language: Using R is free and it is available to update, modify and redistribute as well. You can get your own version of R and resell in the market.
- Easily up-gradable: R allows for easy upgrades which are essential for any statistical language.
- Cross-platform compatible: You can run R on any platforms including Mac OS, Windows, and Linux, etc. the data can easily be imported from other components like Microsoft Access, Microsoft excel and Oracle etc.
- Powerful scripting language: R is capable of handling complex and large data sets. It can be perfectly used for heavy simulations. Also, you can use it for high-performance clusters of the computer.
- Widespread use: R is one of the top programming languages of 2019 and an estimate of 2.5 million users use R.
- R is highly flexible: R is flexible enough to use and most of the new developments in statistics are in R.
- Publishers like using R: R can be easily integrated with systems like Latex which are used for document preparation.
- Huge R community: R has a vibrant community with many users who interact on a daily basis.
If you are interested in learning R, Compufield is the recommended institute to take up the offline classes in Mumbai.
Python:
Python is another programming language recommended to people who want to enter the Big Data or data science fields. It is easier to learn than R, yet it is a high-level programming language that is the preferred choice among web and game developers.Read on for more reasons why Python should be on your learning list for 2017.
Python is Easy to Learn
Like Java, C, and Perl, the basics of Python are more accessible for newbies to grasp. A programmer coding in Python writes less code owing to the language’s user-friendly features like code readability, simple syntax, and ease-of-implementation.
Python is Easier to Debug.
Bugs are every programmer’s worst nightmare, which is why Python’s unique design lends itself well to programmers starting in data science. Writing less code means it is easier to debug. Programs compiled in Python are less prone to issues than those written in some other languages.
Python is Widely Used
Like R, the Python programming language is used in a variety of software packages and industries. Python powers Google’s search engine, YouTube, Dropbox, Reddit, Quora, Disqus, and FriendFeed. NASA, IBM, and Mozilla rely heavily on Python. As a skilled Python specialist, you might land a job at one of these big-name companies.Looking forward to a career as a Data Scientist? Check out the Data Science with Python Training Course and get certified today.
Python is an Object-oriented Language
A strong grasp of the fundamentals will help you migrate to any other object-oriented language because you’ll only need to learn the syntax of the new language.
Python is Open-source
As an open-source programming language, Python is free, which makes it appealing to startups and smaller companies. It’s simplicity also makes it appealing to smaller teams.
Python is a High-performance Language
Python has long been the language of choice for building business-critical yet fast applications.
Python Works with Raspberry Pi
If you want to do some amazing things with Raspberry Pi, then you must learn Python. From amateurs to expert programmers, anyone can now build real-world applications using Python.
Hadoop:
“Hadoop Market is expected to reach $99.31B by 2022 at a CAGR of 42.1%” – Forbes
- Slowly companies are realizing the advantage big data can bring to their business. The big data analytics sector in India will grow eight fold. As per NASSCOM, it will reach USD 16 billion by 2025 from USD 2 billion. As India progresses, there is penetration of smart devices in cities and in villages. This will scale up the big data market.
- As we can see there is a growth in the Hadoop market.
- There is a prediction that the Hadoop market will grow at a CAGR of 58.02% in the time period of 2013 – 2020. It will reach $50.2 billion by 2020 from $1.5 billion in 2012.
- As the market for Big Data grows there will be a rising need for Big Data technologies. Hadoop forms the base of many big data technologies. The new technologies like Apache Spark and Flink work well over Hadoop. As it is an in-demand big data technology, there is a need to master Hadoop. As the requirements for Hadoop professionals are increasing, this makes it a must to learn technology.
Lack of Hadoop Professionals
As we have seen, the Hadoop market is continuously growing to create more job opportunities every day. Most of these Hadoop job opportunities remain vacant due to unavailability of the required skills. So this is the right time to show your talent in big data by mastering the technology before its too late. Become a Hadoop expert and give a boost to your career. This is where Data Flair plays an important role to make you Hadoop expert.
Hadoop for all
Professionals from various streams can easily learn Hadoop and become master of it to get high paid jobs. IT professionals can easily learn Map Reduce programming in java or python, those who know scripting can work on Hadoop ecosystem component named Pig. Hive or drill is easy for those who know to the script.
You can easily learn it if you are:
- IT Professional
- Testing professional
- Mainframe or support engineer
- DB or DBA professional
- Graduate willing to start a career in big data
- Data warehousing professional
- The project manager or lead
Robust Hadoop Ecosystem

Best On-Demand R programming Course from MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
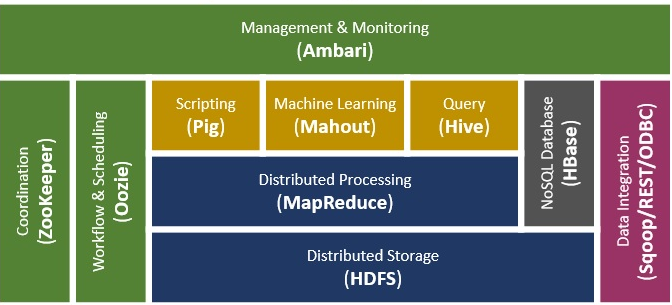
Hadoop has a very robust and rich ecosystem which serves a wide variety of organizations. Organizations like web start-ups, telecom, financial and so on are needing Hadoop to answer their business needs.
- Hadoop ecosystem contains many components like Map Reduce, Hive, HBase, Zookeeper, Apache Pig etc. These components are able to serve a broad spectrum of applications. We can use Map-Reduce to perform aggregation and summarization on Big Data.
- Hive is a data warehouse project on the top HDFS. It provides data query and analysis with SQL like interface. HBase is a NoSQL database. It provides real-time read-write to large datasets. It is naively integrated with Hadoop.
- Pig is a high-level scripting language used with Hadoop. It describes the data analysis problem as data flows. One can do all the data manipulation in it with Pig.
- Zookeeper is an open source server that coordinates between various distributed processes. Distributed applications use zookeeper to store and convey updates to important configuration information.
Research Tool
- Hadoop has come up as a powerful research tool. It allows an organization to find answers to their business questions. Hadoop helps them in research and development work. Companies use it to perform the analysis. They use this analysis to develop a rapport with the customer.
- Applying Big Data techniques improve operational effectiveness and efficiencies of generating great revenue in business. It brings a better understanding of the business value and develops business growth. Communication and distribution of information between different companies are feasible via big data analytics and IT techniques. The organizations can collect data from their customers to grow their business.
Ease of Use
Creators of Hadoop have written it in Java, which has the biggest developer community. Therefore, it is easy to adapt by programmers. You can have the flexibility of programming in other languages too like C, C++, Python, Perl, Ruby etc. If you are familiar with SQL, it is easy to use HIVE. If you are OK with scripting then PIG is for you.Hadoop framework handles all the parallel processing of the data at the back-end. We need not worry about the complexities of distributed processing while coding. We just need to write the driver program, mapper and reducer function. Hadoop framework takes care of how the data gets stored and processed in a distributed manner. With the introduction of Spark in Hadoop, ecosystem coding has become even easier. In Map Reduce, we need to write thousands of lines of code. But in Spark, it has come down to only a few lines of code to achieve the same functionality.




