Last updated on 22nd May 2025| 9978
- Introduction to Data Engineering
- Role of a Data Engineer in Tech Companies
- Programming Languages for Data Engineers
- Databases and Data Warehousing Concepts
- Big Data Technologies
- Cloud Platforms for Data Engineering
- Data Pipelines and ETL Processes
- Conclusion
Introduction to Data Engineering
Data engineering is a foundational discipline within the broader field of data science and analytics. It focuses on the design, construction, and maintenance of robust systems and infrastructure that allow organizations to collect, store, process, and access large volumes of data efficiently and reliably. Data engineers are responsible for building scalable data pipelines, developing data models, and ensuring the quality, consistency, and integrity of data across various platforms. Their work is essential in transforming raw data into clean, organized formats that can be used effectively by data scientists, analysts, and business intelligence tools, especially through Data Science Training. With the rapid growth of data in today’s digital world, the role of data engineering has become more critical than ever. Industries such as finance, healthcare, retail, and technology are investing heavily in modern data infrastructure to support real-time analytics, reporting, and machine learning initiatives. Data engineers often work with big data technologies like Hadoop, Apache Spark, and cloud platforms like AWS, Google Cloud, or Azure to manage data at scale. By enabling seamless data flow and accessibility, data engineering empowers organizations to make informed, data-driven decisions and drive innovation across all levels of operation.
Are You Interested in Learning More About Data Science? Sign Up For Our Data Science Course Training Today!
Role of a Data Engineer in Tech Companies
In tech companies, the role of a Data Engineer is vital to the success of data-driven strategies and operations. Data engineers are responsible for designing, building, and maintaining scalable data architectures that support analytics, machine learning, and real-time applications. They create and manage data pipelines that extract data from various sources, transform it into usable formats, and load it into data warehouses or lakes, which is a key aspect of What is Data Management. These pipelines must be efficient, reliable, and capable of handling large volumes of structured and unstructured data. Tech companies rely heavily on data engineers to ensure data is accessible, accurate, and secure. They work closely with data scientists, analysts, and software engineers to understand data requirements and deliver solutions that enable timely insights and product innovations.
Data engineers also optimize data storage and retrieval using tools such as Apache Spark, Kafka, Airflow, and cloud services like AWS, GCP, or Azure. In fast-paced tech environments, data engineers must be skilled in coding (typically using Python, SQL, or Scala), automation, and database management. Their contributions are crucial in building the data foundation that powers recommendation systems, performance analytics, fraud detection, user behavior tracking, and other data-intensive applications essential to modern tech businesses.
Programming Languages for Data Engineers
- R: While more common in data analysis and statistics, R is sometimes used in data engineering when working with statistical models or complex data processing tasks.
- Go (Golang): Known for performance and efficiency, Go is used in developing high-performance data processing systems and microservices in data engineering environments.
- Shell Scripting (Bash): Essential for automating data workflows, managing files, and performing system-level operations in data engineering tasks, which are crucial for Data Analytics Companies in India.
- Python: Widely used for data processing, automation, and machine learning tasks. Its rich ecosystem of libraries like Pandas, NumPy, and PySpark makes it a top choice for data engineers.
- SQL: The backbone of database management, SQL is crucial for querying, manipulating, and analyzing large datasets stored in relational databases such as MySQL, PostgreSQL, or SQL Server.
- Java: Known for scalability and performance, Java is often used in big data frameworks like Apache Hadoop and Apache Kafka, which are key components in large-scale data engineering pipelines.
- Scala: Scala integrates seamlessly with Apache Spark, a widely used big data processing framework. It’s appreciated for its concurrency and functional programming features, making it a strong choice for data-intensive applications.
- Databases: Databases are structured systems used to store, manage, and retrieve data efficiently. They are typically optimized for transactional operations and are used in everyday applications like websites, banking systems, and customer relationship management tools.
- Relational Databases (RDBMS): These use a table-based structure and follow SQL (Structured Query Language) for data manipulation. Popular examples include MySQL, PostgreSQL, and Oracle Database. They are ideal for structured data with clearly defined relationships.
- NoSQL Databases: Designed for flexibility and scalability, NoSQL databases such as MongoDB, Cassandra, and Redis handle unstructured or semi-structured data, making them a key component in Data Science Training.
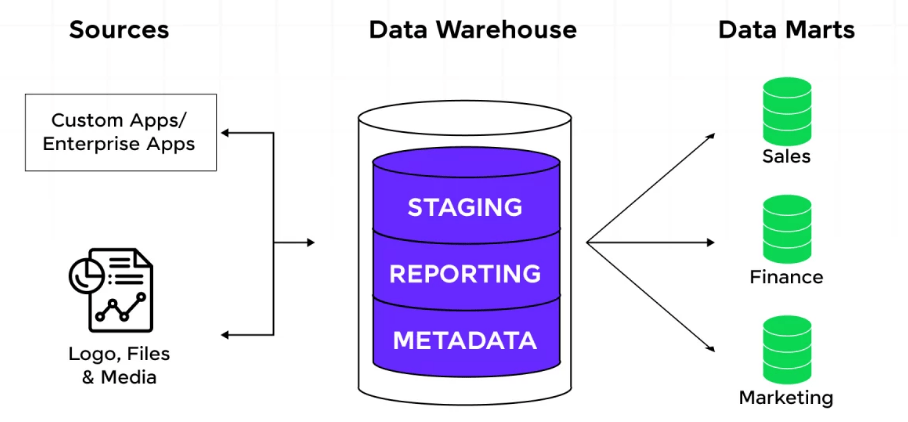
- Data Warehousing: A data warehouse is a central repository designed for analytical processing. It consolidates data from different sources to support business intelligence and reporting. Examples include Amazon Redshift, Google BigQuery, and Snowflake.
- Data Modeling: Proper data modeling using techniques like star and snowflake schemas ensures efficient query performance and logical data organization in data warehouses.
- ETL Process: Extract, Transform, Load (ETL) is the backbone of data warehousing. It involves extracting data from source systems, transforming it into a usable format, and loading it into the warehouse.
- OLTP vs. OLAP: Online Transaction Processing (OLTP) systems support day-to-day transactions, while Online Analytical Processing (OLAP) systems are optimized for complex queries and data analysis.
- Managed Services: Cloud providers offer fully-managed services, reducing infrastructure maintenance and allowing engineers to focus on development and optimization.
- Security and Compliance: These platforms provide strong security features, including encryption, access control, and compliance with industry standards like GDPR and HIPAA.
- Amazon Web Services (AWS): AWS offers a wide range of services tailored for data engineering, including AWS Glue for ETL, Amazon Redshift for data warehousing, and Amazon S3 for scalable storage.
- Google Cloud Platform (GCP): GCP offers powerful data services like BigQuery and Dataflow, key to unlocking The Power and Promise of Generative AI.
- Microsoft Azure: Azure’s key data engineering tools include Azure Data Factory for ETL workflows, Azure Synapse Analytics for data warehousing, and Blob Storage for scalable data storage.
- Scalability and Flexibility: All major cloud platforms offer auto-scaling, high availability, and flexible pricing, making it easier to handle growing data volumes and changing workloads.
- Integration and Ecosystem: Cloud platforms support seamless integration with open-source tools, third-party services, and machine learning frameworks, enabling full-stack data solutions.
To Earn Your Data Science Certification, Gain Insights From Leading Data Science Experts And Advance Your Career With ACTE’s Data Science Course Training Today!
Databases and Data Warehousing Concepts

Big Data Technologies
Big Data technologies are essential tools and platforms designed to process, manage, and analyze massive volumes of data that traditional systems cannot handle efficiently. These technologies enable organizations to extract valuable insights from structured, semi-structured, and unstructured data generated at high velocity and volume. One of the most widely used big data frameworks is Apache Hadoop, which uses distributed storage (HDFS) and processing (MapReduce) to manage large datasets. Apache Spark offers a faster, in-memory data processing alternative and supports advanced analytics like machine learning, stream processing, and graph computation, making it essential for Data Mining and Data Warehousing. Data storage and management are handled by systems such as Apache Hive, HBase, and Cassandra, which provide scalable solutions for querying and organizing big data. For real-time data processing, Apache Kafka and Flink are commonly used to handle continuous data streams. Cloud platforms like AWS, Google Cloud, and Azure offer scalable infrastructure and services like Amazon EMR, BigQuery, and Azure Synapse to support big data workflows. These technologies collectively enable businesses to analyze customer behavior, detect fraud, personalize services, and optimize operations. As data continues to grow exponentially, big data technologies remain at the core of innovation and competitive advantage across industries.
Are You Considering Pursuing a Master’s Degree in Data Science? Enroll in the Data Science Masters Course Today!
Cloud Platforms for Data Engineering
Data Pipelines and ETL Processes
Data pipelines and ETL (Extract, Transform, Load) processes are critical components in modern data engineering, enabling the seamless movement and transformation of data from various sources to centralized storage systems like data warehouses or data lakes. A data pipeline is a series of automated steps that transport data from source systems such as databases, APIs, or streaming services through various transformation stages before delivering it to a destination where it can be analyzed or used for business intelligence and machine learning. The ETL process begins with extraction, where raw data is collected from different sources, which is crucial for understanding the Median in Statistics. Next is transformation, where the data is cleaned, filtered, aggregated, or reformatted to meet specific analytical or business requirements. Finally, the loading stage moves the transformed data into a target system for storage or further use. Modern pipelines often use ELT (Extract, Load, Transform) approaches, especially in cloud environments where transformation can occur after data is loaded. Tools such as Apache Airflow, Talend, Informatica, and AWS Glue are widely used to build and manage ETL workflows. These systems support automation, monitoring, and scalability. Efficient data pipelines ensure data is accurate, up-to-date, and ready for real-time or batch processing, driving better decision-making across organizations.
Go Through These Data Science Interview Questions & Answer to Excel in Your Upcoming Interview.
Conclusion
In conclusion, the fields of data science, data engineering, and big data analytics play an increasingly vital role in today’s data-driven world. As organizations generate and collect massive amounts of data, the ability to process, manage, and derive insights from this information has become a key competitive advantage. Data science enables advanced analytics, predictive modeling, and intelligent decision-making, while data engineering ensures that the infrastructure and pipelines are in place to support reliable, scalable, and efficient data operations. Tools and technologies such as Python, Apache Spark, Hadoop, and cloud platforms empower professionals to build robust systems that handle data across various domains and use cases, making them essential in Data Science Training. From exploratory data analysis and data visualization to building machine learning models and designing ETL workflows, each component of the data lifecycle is essential. Effective collaboration between data engineers, data scientists, and analysts ensures the successful transformation of raw data into meaningful outcomes. As the demand for real-time insights and automated solutions continues to grow, the importance of skilled data professionals and modern data infrastructure will only increase. Embracing these technologies and best practices allows organizations to unlock the full value of their data and drive innovation, efficiency, and growth.




