
Last updated on 21st May 2025| 10149
- Introduction to Information Retrieval (IR)
- Importance of IR in Search Engines
- Key Concepts of IR: Indexing and Ranking
- TF-IDF and Vector Space Models
- Boolean Retrieval Model in IR
- Latent Semantic Indexing (LSI)
- Web Crawlers and Search Engine Optimization
- Implementing Information Retrieval in Python
- Role of AI and Machine Learning in IR
- Information Retrieval in Recommendation Systems
- Challenges in Modern Information Retrieval
- Future of Information Retrieval Technologies
Introduction to Information Retrieval (IR)
Information Retrieval (IR) refers to the process of obtaining relevant data or content from large datasets or information repositories in response to a user’s query. It is a cornerstone of technologies such as search engines, digital libraries, databases, and recommendation systems. As the volume of digital information continues to grow exponentially, IR systems have become indispensable tools for helping users efficiently locate the specific content they need, whether it’s text, images, audio, or video. At its core, IR is about connecting people with the most pertinent and meaningful information available, minimizing the noise of irrelevant data. It achieves this through sophisticated algorithms and techniques that rank, filter, and index content to match it with user intent. The development and optimization of these algorithms are vital to ensuring users can retrieve accurate and useful results in minimal time. Effective IR systems not only improve access to information but also enhance the user experience by delivering results that closely align with their search goals. Precision, recall, speed, and relevance are among the key metrics used to evaluate IR performance, and ongoing research in the field continues to refine these aspects. Moreover, IR technologies are increasingly integrated into AI-driven platforms that anticipate user needs and offer contextual recommendations based on usage patterns, preferences, and previous interactions. This integration makes IR even more dynamic and proactive. Whether it’s a scholar seeking academic articles, a consumer searching for product reviews, or a user exploring multimedia content, IR empowers users to make informed decisions by delivering targeted results. If you’re interested in learning more about the foundations and applications of IR and related techniques, consider exploring our Data Science Training program. In today’s information-rich environment, the importance of effective Information Retrieval cannot be overstated, as it plays a vital role in managing, accessing, and leveraging the digital information landscape in real time, helping individuals and organizations make sense of complex and voluminous data.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Importance of IR in Search Engines
Search engines like Google, Bing, and Yahoo rely heavily on Information Retrieval techniques to fetch relevant results for users. The key importance of IR in search engines includes:
- Efficient Searching: IR helps process billions of web pages within milliseconds to deliver the most relevant results.
- User Satisfaction: Well-optimized IR systems enhance user experience by ensuring query relevance.
- Scalability: Modern search engines use distributed computing and indexing techniques to handle vast amounts of data.
- Multimedia Retrieval: IR extends beyond text to images, videos, and audio search.
Search engines use IR methodologies such as indexing, ranking, and natural language processing to optimize search results based on user queries.
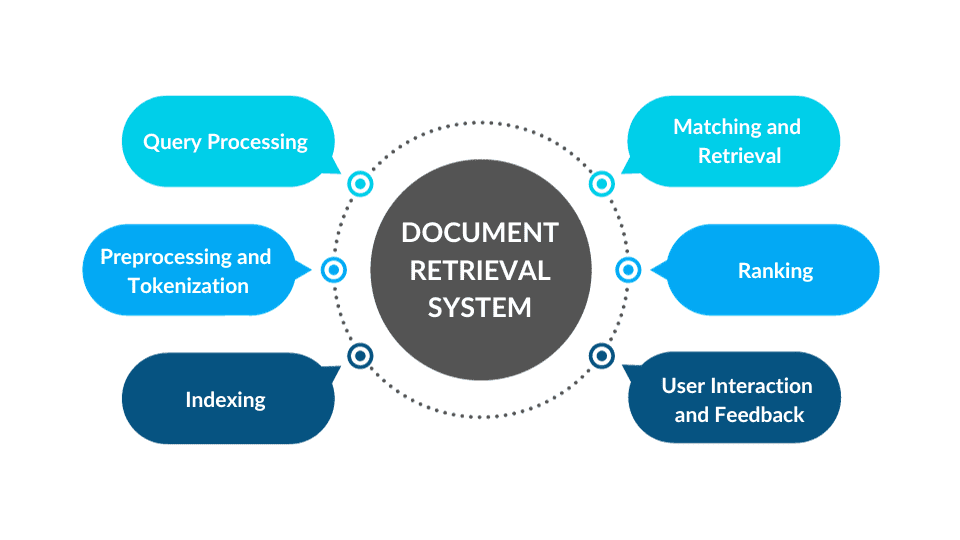
Key Concepts of IR: Indexing and Ranking
Two critical components of IR are indexing and ranking:
- Indexing: The process of organizing data to facilitate quick searches. It involves preprocessing the text, tokenizing words, and creating an inverted index.
- Ranking: Assigns relevance scores to documents based on factors like term frequency, query matching, and link analysis (e.g., Google’s PageRank algorithm).
By employing these techniques, search engines improve efficiency and accuracy in retrieving relevant information.
TF-IDF and Vector Space Models
Term Frequency-Inverse Document Frequency (TF-IDF) is a widely used statistical measure in information retrieval and text mining that evaluates the importance of a word within a specific document relative to a larger collection or corpus of documents. It combines two metrics: Term Frequency (TF), which quantifies how often a particular term appears in a document, highlighting its significance within that document, and Inverse Document Frequency (IDF), which reduces the weight of terms that occur frequently across many documents, thereby emphasizing terms that are more unique or informative. The TF-IDF score is calculated by multiplying TF and IDF, resulting in a value that reflects the importance of a term within a document in the context of the entire collection. This approach helps in identifying keywords that best represent the content of a document while filtering out commonly used words that carry less meaningful information. If you’re interested in learning more about data collection methods and techniques, check out What is Data Collection. Alongside TF-IDF, the Vector Space Model (VSM) is employed to represent both documents and user queries as vectors in an n-dimensional space, where each dimension corresponds to a term from the document corpus. The similarity between a query and documents is typically measured using cosine similarity, which computes the cosine of the angle between the document and query vectors. A higher cosine similarity value indicates a smaller angle and greater relevance, allowing the system to rank search results effectively. Together, TF-IDF and VSM form the backbone of many search and recommendation engines by enabling efficient and accurate retrieval of relevant information based on the statistical significance of terms and the geometric relationship between documents and queries.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Boolean Retrieval Model in IR
The Boolean Retrieval Model is one of the earliest IR models. It retrieves documents based on exact matches using Boolean logic:
- AND: Retrieves documents containing all search terms.
- OR: Retrieves documents containing at least one search term.
- NOT: Excludes documents containing a specific term.
Although simple, the Boolean model lacks ranking capabilities and does not consider term importance, making it less effective for large-scale search engines.
Latent Semantic Indexing (LSI)
Latent Semantic Indexing (LSI) is an advanced information retrieval (IR) technique that aims to capture the underlying relationships between words and concepts within documents, thereby improving the accuracy and relevance of search results. Traditional keyword-based search systems often rely on exact matches of terms, which can be limiting, especially when searching for synonyms or contextually related terms. LSI addresses this challenge by using Singular Value Decomposition (SVD) to reduce the dimensionality of term-document matrices, effectively uncovering latent semantic structures in the data. Through this process, LSI identifies synonyms and related terms that might not appear as exact matches in the text but are conceptually linked, expanding the search capabilities beyond mere keyword occurrences. Additionally, LSI helps improve document ranking by evaluating the conceptual meaning of terms, ensuring that documents are ranked based on their thematic relevance rather than just keyword frequency. If you’re looking for ways to challenge yourself and further develop your data science skills, consider participating in Top Data Science Hackathons. One of the key advantages of LSI is its ability to handle polysemy, which occurs when a word has multiple meanings depending on the context. By analyzing patterns in the term-document matrix, LSI can disambiguate such words and retrieve documents that match the intended meaning. This results in more accurate and contextually relevant search outcomes. Overall, LSI enhances traditional keyword-based search systems by incorporating semantic relationships between terms, making it a powerful tool in modern information retrieval. By focusing on the deeper, conceptual connections within documents, LSI allows for more intelligent and effective search capabilities that go beyond the limitations of simple keyword matching.

Web Crawlers and Search Engine Optimization (SEO)
Web crawlers (or spiders) are automated bots that scan and index web pages for search engines. Their functions include:
- Crawling: Visiting web pages and collecting data.
- Indexing: Storing extracted content for retrieval.
- Ranking: Determining relevance based on algorithms.
- Keyword optimization
- Page load speed
- Backlinks and domain authority
- Mobile responsiveness
Search Engine Optimization (SEO) techniques help improve website visibility by optimizing factors such as:
Proper SEO ensures higher rankings in search engine results, driving more traffic to websites.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Implementing Information Retrieval in Python
Python offers a wide range of robust libraries that make it easier to implement information retrieval (IR) systems. One of the most popular libraries is NLTK (Natural Language Toolkit), which is primarily used for text preprocessing and tokenization, enabling efficient handling of text data. Scikit-learn, another powerful library, provides tools for implementing TF-IDF (Term Frequency-Inverse Document Frequency) and vector space models, which are essential for evaluating the relevance of terms in documents. Whoosh is a lightweight search engine library designed for indexing and querying text, making it an ideal choice for building efficient search systems. For more advanced tasks like topic modeling and Latent Semantic Indexing (LSI), Gensim is highly recommended, as it specializes in these areas and can help uncover deeper semantic relationships within large text corpora. If you’re interested in gaining more expertise in Python and information retrieval, consider exploring our Data Science Training program. For example, implementing a simple TF-IDF model in Python using Scikit-learn can be done as follows: First, import the necessary module from Scikit-learn, TfidfVectorizer, and create a corpus of text data. Then, the TfidfVectorizer is used to transform the corpus into a TF-IDF matrix, which quantifies the importance of words in each document relative to the entire corpus. The resulting matrix can be printed, along with the feature names (terms) that were extracted from the corpus. Here’s the code: from sklearn.feature_extraction.text import TfidfVectorizer followed by defining the corpus and transforming it into a TF-IDF matrix. This process highlights how Python libraries facilitate the development of IR models by making text analysis and retrieval more efficient and accessible, especially for tasks like indexing and ranking based on word frequency.
Role of AI and Machine Learning in IR
Artificial Intelligence (AI) and Machine Learning (ML) have transformed IR by introducing intelligent search and recommendation algorithms:
- Natural Language Processing (NLP): Helps understand user intent.
- Neural Networks: Enhance ranking accuracy through deep learning models.
- Reinforcement Learning: Optimizes search algorithms based on user interactions.
AI-driven IR systems can personalize search experiences and provide more relevant results.
Information Retrieval in Recommendation Systems
Recommendation systems leverage information retrieval (IR) techniques to suggest relevant items to users based on their preferences and behaviors. One common approach is content-based filtering, which recommends items similar to those the user has previously interacted with, focusing on the features of the items themselves. Another widely used method is collaborative filtering, which analyzes the preferences and behavior of users to recommend items that similar users have enjoyed, capitalizing on the collective behavior of the user base. Hybrid models combine multiple approaches, such as content-based and collaborative filtering, to enhance the accuracy and effectiveness of recommendations by mitigating the limitations of individual methods. If you’re interested in learning more about how data structures and systems underpin recommendation models, check out What is Data Architecture. IR-powered recommendation systems are integral to various industries, including e-commerce, where they suggest products based on past purchases or browsing history, streaming platforms, which recommend movies or music based on user preferences, and social media platforms, where they suggest friends, posts, or groups based on user interactions. These systems play a critical role in personalizing user experiences, helping individuals discover content that aligns with their interests and needs.
Challenges in Modern Information Retrieval
Modern IR systems face several challenges:
- Scalability: Handling billions of documents efficiently.
- Relevance: Improving accuracy of search results.
- Ambiguity: Understanding user queries with multiple meanings.
- Privacy Concerns: Managing sensitive information securely.
- Spam and Misinformation: Filtering out low-quality or fake content.
Overcoming these challenges requires continuous advancements in IR algorithms and AI technologies.
Future of Information Retrieval Technologies
The future of information retrieval (IR) is being shaped by significant advancements in artificial intelligence (AI), natural language processing (NLP), and deep learning technologies. One of the emerging trends is voice and conversational search, where IR systems are evolving to process spoken queries more effectively, providing a more intuitive and hands-free search experience. Another key development is semantic search, which focuses on improving the system’s understanding of user intent and context, enabling more accurate and relevant search results beyond simple keyword matching. As the field progresses, professionals may want to consider acquiring advanced skills in data science to stay ahead of the curve. Programs like Data Science Training offer valuable insights into these emerging technologies. Augmented Reality (AR) search is also making waves, enhancing the IR experience by integrating AR interfaces that allow users to interact with and retrieve information in a more immersive and intuitive way. Additionally, quantum computing holds the potential to revolutionize search algorithms by providing faster and more efficient methods for processing large datasets, thus accelerating retrieval times. As technology continues to evolve, IR systems are expected to become increasingly sophisticated, providing smarter, context-aware, and more personalized search experiences. These advancements will transform how people access and utilize information, making searches not only more efficient but also more aligned with the needs and intents of users in real-time.




