
Last updated on 23rd May 2025| 9661
- Introduction to Data Engineering Tools
- Data Processing Tools: Apache Spark and Hadoop
- ETL Tools
- Data Warehousing Tools
- Cloud Platforms: AWS, Azure, and GCP
- Version Control: Git and GitHub
- Containerization: Docker and Kubernetes
- Monitoring and Logging Tools
Introduction to Data Engineering Tools
Data engineering tools are essential for the collection, transformation, storage, and processing of large volumes of data, enabling businesses to derive valuable insights and support data-driven decision-making. These tools play a critical role in building robust data pipelines and managing complex data architectures. One of the most widely used tools is Apache Hadoop, an open-source framework for processing and storing massive datasets across distributed clusters. It is built around the HDFS (Hadoop Distributed File System) for storage and the MapReduce programming model for batch processing. Another key tool in Data Science Training is Apache Spark, known for its speed and versatility in processing both batch and real-time data. Unlike Hadoop, Spark performs in-memory processing, significantly speeding up data analysis tasks, and is often preferred for machine learning and advanced analytics. SQL-based databases such as MySQL, PostgreSQL, and Microsoft SQL Server are also crucial for managing structured data. For big data storage, NoSQL databases like MongoDB and Cassandra provide flexibility with unstructured data. Cloud-based platforms like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) offer scalable, managed services that simplify data engineering tasks by providing computing, storage, and analytics tools in a unified platform. These tools empower data engineers to build efficient data pipelines, process large datasets, and maintain data integrity across an organization’s infrastructure.
Interested in Obtaining Your Data Science Certificate? View The Data Science Course Training Offered By ACTE Right Now!
Data Processing Tools: Apache Spark and Hadoop
Apache Spark and Hadoop are two of the most popular data processing frameworks used for handling large-scale datasets. Both are designed to process vast amounts of data efficiently, but they operate differently and serve distinct purposes. Apache Spark is an open-source, distributed computing system known for its speed and ease of use. Spark processes data in-memory, making it significantly faster than Hadoop’s MapReduce, especially for iterative algorithms and real-time data processing, which is a key focus in Analytics Course Certifications. It supports a wide variety of workloads, including batch processing, stream processing, machine learning, and graph processing, making it a versatile tool in big data analytics. Spark’s ability to process data in real-time, through Spark Streaming, and its integration with other big data tools like Hadoop HDFS and Apache Kafka, make it ideal for modern data processing needs. Hadoop, on the other hand, is a more mature framework that processes large datasets using the MapReduce programming model.
It relies heavily on disk storage, which makes it slower than Spark but is still effective for large-scale batch processing. Hadoop also includes the HDFS (Hadoop Distributed File System), which is optimized for storing massive datasets across distributed clusters. While Spark is faster and more flexible, Hadoop remains an essential tool for batch processing and large-scale data storage. Many organizations use both technologies in tandem to leverage their respective strengths.
ETL Tools
- Definition: ETL tools are software solutions used to extract data from various sources, transform it into a suitable format, and load it into a target system such as a data warehouse or data lake.
- Data Integration: They help in integrating data from disparate sources like databases, flat files, APIs, and cloud services ensuring a unified view for analysis and reporting.
- Automation: ETL tools automate data workflows, reducing manual effort and minimizing human error. This improves efficiency and ensures data is processed consistently.
- Data Quality and Cleaning: During transformation, ETL tools apply rules to clean and validate data. This step ensures only accurate, high-quality data enters the target system, emphasizing the importance of Time Management and Productivity.
- Scalability: Modern ETL tools can handle large volumes of data and scale easily to meet growing business needs, making them suitable for enterprise-level operations.
- Real-Time Processing: Some tools support real-time or near-real-time ETL, enabling up-to-date data availability for business intelligence and analytics.
- Popular Tools: Common ETL tools include Apache NiFi, Talend, Informatica, Microsoft SSIS, and cloud-native solutions like AWS Glue and Google Dataflow.
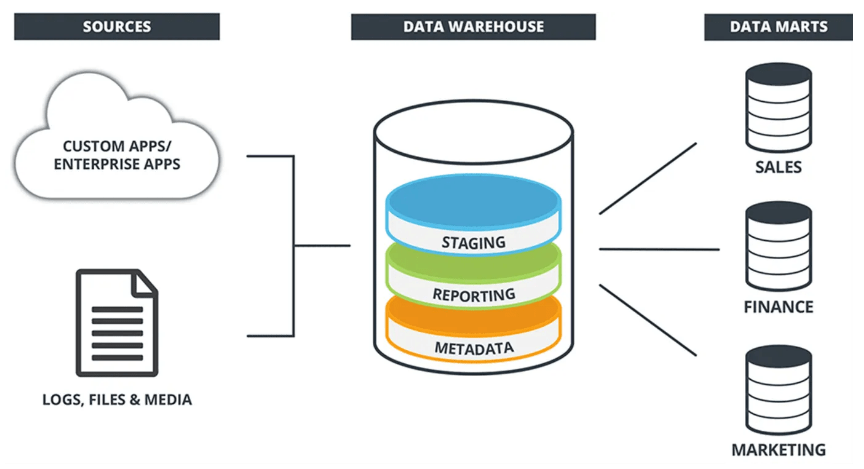
- Definition: Data warehousing tools are software solutions designed to collect, store, manage, and analyze large volumes of structured data from various sources in a centralized repository called a data warehouse.
- Data Consolidation: These tools aggregate data from multiple sources such as transactional databases, ERP systems, and external feeds into a unified format for better accessibility and decision-making.
- Performance Optimization: They are optimized for query performance, supporting complex analytics and reporting by using techniques like indexing, partitioning, and parallel processing, which are essential topics in Data Science Training.
- Scalability and Storage: Modern data warehousing tools offer scalable storage solutions, both on-premise and in the cloud, allowing businesses to grow without compromising performance.
- Security and Compliance: They provide robust data security features such as encryption, access controls, and audit trails to ensure compliance with regulations like GDPR and HIPAA.
- Integration with BI Tools: These tools integrate seamlessly with business intelligence platforms (e.g., Tableau, Power BI), enabling data visualization and advanced analytics.
- Popular Tools: Leading data warehousing tools include Amazon Redshift, Google BigQuery, Snowflake, Microsoft Azure Synapse Analytics, and Teradata, each offering unique features suited to various business needs.
- Definition: Version control is a system that tracks and manages changes to files, allowing teams to collaborate, maintain history, and revert to earlier versions if needed.
- Types of Version Control: It includes centralized systems (CVCS) with a single server and distributed systems (DVCS) like Git, where each user has a complete repository copy.
- Collaboration: It enables multiple developers to work on the same project without overwriting each other’s work, managing changes and resolving conflicts efficiently.
- Change Tracking: Every change is recorded with metadata such as author, timestamp, and message, providing a clear history and accountability, which is essential in projects like Logistic Regression Using R.
- Branching and Merging: Developers can create separate branches to work independently and later merge them into the main codebase, enabling parallel and safe development.
- Error Recovery: Users can revert to previous versions if mistakes occur, reducing the risk of data loss or project issues.
- Popular Tools: Common tools include Git, SVN, and Mercurial, along with platforms like GitHub, GitLab, and Bitbucket for repository hosting and collaboration.
To Earn Your Data Science Certification, Gain Insights From Leading Data Science Experts And Advance Your Career With ACTE’s Data Science Course Training Today!
Data Warehousing Tools

Cloud Platforms: AWS, Azure, and GCP
Cloud platforms like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) are the backbone of modern IT infrastructure, offering scalable, flexible, and cost-effective solutions for businesses of all sizes. These platforms provide a wide range of cloud services, from computing power and storage to machine learning and analytics. AWS is the market leader, offering an extensive array of services such as EC2 (Elastic Compute Cloud), S3 (Simple Storage Service), and Lambda for serverless computing. Its global reach and robust ecosystem make it the preferred choice for many enterprises looking to scale rapidly, reflecting key concepts in Theories of Motivation. Microsoft Azure is known for its seamless integration with Microsoft products, such as Windows Server, SQL Server, and Active Directory. Azure’s hybrid cloud capabilities allow businesses to combine on-premises infrastructure with cloud services, making it a popular choice for enterprises seeking flexibility. Google Cloud Platform (GCP) excels in data analytics, machine learning, and containerization, with tools like BigQuery, TensorFlow, and Kubernetes. GCP is particularly favored for its high-performance computing capabilities and deep integration with Google’s AI and data services. Each cloud platform has its unique strengths, and businesses typically choose based on their specific needs, budget, and existing technology stack.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Version Control: Git and GitHub
Containerization: Docker and Kubernetes
Containerization is a method of packaging software and its dependencies into a standardized unit, called a container, which can run consistently across different environments. Docker and Kubernetes are two leading technologies in this field, widely used in software development and operations. Docker is a platform that allows developers to build, ship, and run applications in containers. By using Docker, developers can ensure that their applications work seamlessly across various environments, from development to production. Docker containers are lightweight, portable, and fast, making them ideal for microservices architectures and continuous integration/continuous deployment (CI/CD) pipelines, highlighting the Data Science Importance in Tech Industry. Kubernetes, on the other hand, is an open-source orchestration platform for automating the deployment, scaling, and management of containerized applications. While Docker focuses on the creation and management of individual containers, Kubernetes handles the deployment and coordination of multiple containers across clusters of machines. It provides features like load balancing, auto-scaling, and rolling updates, enabling highly available and scalable applications. Together, Docker and Kubernetes revolutionize application development and deployment, allowing businesses to build and maintain complex, distributed systems efficiently. These technologies improve collaboration, streamline workflows, and provide robust solutions for cloud-native environments.
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
Monitoring and Logging Tools
Monitoring and logging tools are essential for ensuring the health, performance, and security of systems, applications, and networks. These tools collect and analyze real-time data, allowing teams to detect issues early, troubleshoot problems, and optimize performance. Monitoring tools track system metrics such as CPU usage, memory, disk space, and network traffic. They offer real-time insights into the health of infrastructure and applications, allowing for proactive alerts and automated responses to potential issues. Popular monitoring tools include Prometheus, Nagios, and Datadog, which provide dashboards, alerting systems, and anomaly detection, often covered in Data Science Training. On the other hand, logging tools capture detailed records of events within systems, offering valuable information for debugging and forensic analysis. Logs include data on errors, transactions, and user activities. Tools like ELK Stack (Elasticsearch, Logstash, and Kibana), Splunk, and Fluentd allow for efficient log aggregation, search, and visualization, helping teams identify trends, diagnose problems, and maintain security. Together, monitoring and logging tools ensure that systems run smoothly, provide insights into system performance, and help quickly identify and resolve issues, making them vital for maintaining operational efficiency and security in modern IT environments.




