
Last updated on 24th Apr 2025| 9309
- Introduction to Data Science Subjects
- Programming for Data Science
- Machine Learning Fundamentals
- Deep Learning and Neural Networks
- Data Visualization Techniques
- Big Data Technologies
- Cloud Computing for Data Science
- Business Intelligence and Analytics
Introduction to Data Science Subjects
Data Science is a multidisciplinary field that combines various subjects, techniques, and tools to extract meaningful insights from large datasets. The role of a data scientist is crucial in helping businesses and organizations make informed decisions by collecting, analyzing, and interpreting data. To excel in data science, individuals must master several core subjects, each of which plays a vital role in the overall process. One of the most important subjects is mathematics, particularly linear algebra, calculus, and probability theory, which provide the foundational understanding for many machine learning algorithms and statistical methods, and Data Science Training reinforces these concepts through practical application and real-world problem-solving. Statistics is also critical, allowing data scientists to draw valid conclusions from data, estimate uncertainty, and test hypotheses. Programming skills are indispensable for a data scientist, with languages like Python and R widely used for data manipulation, visualization, and model building. In addition, familiarity with machine learning techniques enables data scientists to build predictive models and algorithms that can automate decision-making processes. Other relevant subjects include data visualization, which helps present insights understandably, and big data technologies like Hadoop and Spark, which are necessary for processing large-scale datasets. A solid understanding of these subjects empowers data scientists to uncover valuable insights and drive strategic decisions.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Course Training To Gain Insights From Our Experts!
Programming for Data Science
Programming is a core skill for Data Scientists, as it allows them to implement algorithms, manipulate data, and create models. Python and R are the most widely used programming languages in Data Science.
- Python: Known for its versatility and extensive library support, Python is the preferred language for many Data Scientists. Libraries such as Pandas, NumPy, Matplotlib, and Scikit-learn are commonly used for data manipulation, analysis, visualization, and machine learning.
- R: R is another popular language, particularly in academia and research. It is highly effective for statistical analysis and visualizing complex data sets, and resources like a Streamlit Tutorial for Data Science Projects can help integrate interactive data apps into your workflow for enhanced data presentation.
- Java: Java is widely used in large-scale applications and enterprise-level systems. It offers robust libraries like Apache Spark and Weka for big data processing, machine learning, and data analysis. Java is favored for its speed, scalability, and strong object-oriented principles.
- Julia: Julia is a high-performance programming language designed for numerical and scientific computing. It is particularly useful for tasks that require heavy computational power, like machine learning, data analysis, and simulation. Julia’s speed makes it an attractive choice for researchers working with large datasets.
- SQL: SQL (Structured Query Language) is a foundational tool for managing and querying relational databases. Data scientists and analysts use SQL to extract, manipulate, and aggregate data from databases. It’s essential for working with large-scale structured datasets in most business applications.
- Scala: Scala, often used with Apache Spark, is popular in the big data ecosystem. It combines object-oriented and functional programming paradigms, making it ideal for working with large-scale data processing and analytics, especially in distributed computing environments.
- Supervised Learning: The model is trained on labeled data and can predict outcomes for new, unseen data (e.g., classification and regression tasks).
- Unsupervised Learning: The model uses unlabeled data to identify patterns, clusters, or associations (e.g., clustering and dimensionality reduction).
- Reinforcement Learning: The model learns to make decisions through trial and error by receiving feedback as rewards or penalties, a process that is a key component of the AI Project Cycle in developing intelligent systems.
- Semi-Supervised Learning: The model is trained on a small amount of labeled data and a large amount of unlabeled data, improving performance when labeling large datasets is expensive or time-consuming.
- Self-Supervised Learning: In self-supervised learning, the model generates labels from the input data itself.
- Transfer Learning: In transfer learning, a model trained on one task is reused or fine-tuned for a related task.
- Hadoop: A distributed storage and processing framework that allows the storage and analysis of massive datasets across many computers. Hadoop uses the MapReduce programming model for data processing.
- Apache Spark: A fast, in-memory processing engine that is more efficient than Hadoop for many types of data analytics. Spark is often used for real-time data processing and iterative machine-learning tasks.
- Apache Hive: A data warehousing and SQL-like query language that runs on top of Hadoop. Hive simplifies the process of querying large datasets stored in Hadoop by providing a more accessible interface for data analysis and reporting, making it a valuable tool for Website Analytics where large volumes of user data need to be processed efficiently.
- Apache HBase: A distributed, scalable NoSQL database built on top of Hadoop, designed for real-time read and write access to large datasets. HBase is suitable for applications that require fast, random access to massive amounts of structured data.
- Apache Flink: A stream processing framework that excels in real-time data processing. It allows the processing of both batch and stream data, making it ideal for applications that require low-latency processing, such as fraud detection or sensor data analysis.
- Kafka: A distributed event streaming platform designed to handle real-time data feeds. Kafka is widely used for building real-time data pipelines and streaming applications, enabling the integration of various data sources for immediate processing and analysis.
Machine Learning Fundamentals
Machine learning (ML) is one of the most exciting areas of Data Science, where algorithms are designed to learn from data and make predictions. The fundamental concepts of machine learning include:
Interested in Obtaining Your Data Science Certificate? View The Data Science Course Training Offered By ACTE Right Now!
Deep Learning and Neural Networks
Deep Learning is a powerful subfield of machine learning that focuses on using neural networks with multiple layers, often referred to as deep neural networks. These models excel in handling large volumes of unstructured data, such as images, speech, and text. Key components of deep learning include neural networks, which are artificial neurons designed to mimic the human brain’s structure, enabling them to process and analyze complex data, and understanding What is Parsing in NLP is essential for breaking down and interpreting textual data within this framework. Convolutional Neural Networks (CNNs) are particularly effective for image-related tasks, such as image classification, object detection, and facial recognition, by automatically learning spatial hierarchies in data. Recurrent Neural Networks (RNNs), on the other hand, are ideal for sequential data like time series or natural language, as they have an inherent ability to retain and process past information in the sequence.
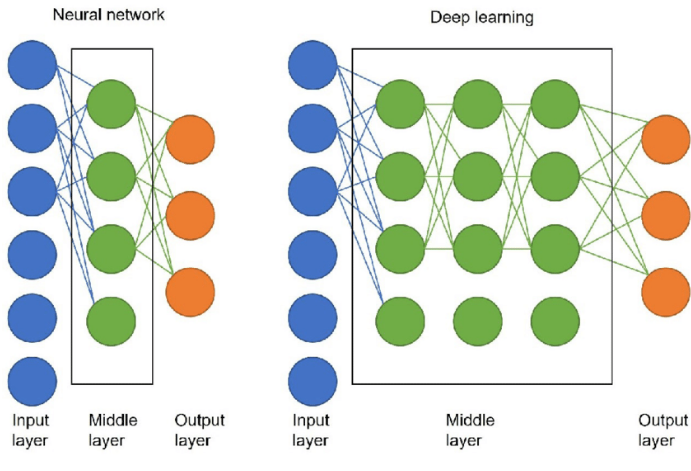
Training deep learning models typically involves backpropagation and stochastic gradient descent to adjust network weights and minimize errors. The impact of deep learning has been transformative across various industries, from autonomous driving and medical diagnostics to entertainment and recommendation systems, driving innovations that improve efficiency, accuracy, and user experience.

Data Visualization Techniques
Data visualization is a powerful technique for representing data visually, allowing users to uncover patterns, trends, and insights that might be difficult to discern from raw data alone. Among the most common methods are charts and graphs, such as bar charts, histograms, scatter plots, and line graphs, which effectively display numerical data and relationships between variables. Heatmaps are particularly useful for visualizing correlations, showing data density, or highlighting areas of interest in large datasets, making it easier to identify significant trends, and Data Science Training provides the expertise to create and interpret these visualizations effectively. Geographical maps, like choropleth maps, help visualize data in a spatial context, providing insights into regional trends or distributions. Dashboards are another valuable tool, offering interactive, real-time visualizations that allow users to explore and analyze data dynamically. By enabling an intuitive understanding of complex information, data visualization plays a crucial role not only in data analysis but also in communicating findings to stakeholders. Well-designed visualizations can simplify decision-making, making them an essential tool in both business and research, where clarity and quick insights are vital.
Gain Your Master’s Certification in Data Science by Enrolling in Our Data Science Masters Course.
Big Data Technologies
Big Data technologies are crucial for dealing with massive datasets that cannot be processed with traditional data analysis tools. Hadoop and Spark are the most widely used frameworks in this field.
Cloud Computing for Data Science
Cloud computing has revolutionized data science by offering scalable and flexible computing resources, enabling data scientists to efficiently store, process, and analyze large datasets without the need to manage infrastructure. Key cloud platforms like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) provide a wide range of tools tailored for data science tasks. AWS offers services such as Amazon S3 for scalable storage and Amazon EC2 for computational power, making it a go-to choice for many data scientists. Similarly, Microsoft Azure provides Azure Machine Learning for model development and Azure Databricks for collaborative analytics, supporting a deeper understanding of What are the Functions of Statistics by enabling advanced data exploration, analysis, and model building. GCP, known for its robust tools, includes BigQuery for fast and scalable data analytics and TensorFlow for machine learning, which is highly popular in AI research and application. Cloud computing not only facilitates the execution of complex algorithms but also enables access to big data and global collaboration across teams. By leveraging the cloud, organizations can significantly reduce the costs and complexities associated with maintaining local infrastructure, ultimately driving innovation and efficiency in data-driven projects.
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
Business Intelligence and Analytics
Business Intelligence (BI) is the process of analyzing data to support informed decision-making within organizations. Data Science plays a crucial role in BI by leveraging advanced statistical methods and machine learning techniques to extract deeper insights from data. Predictive Analytics is one of the key contributions of data science to BI, using historical data to forecast future trends, such as customer behavior, sales performance, or market shifts. Prescriptive Analytics, another vital aspect, goes a step further by recommending specific actions based on data analysis, such as the best strategies for marketing or resource allocation, and Data Science Training equips professionals with the skills needed to implement these analytical techniques effectively. Data scientists utilize BI tools to transform raw data into actionable insights, enabling businesses to optimize operations, improve customer satisfaction, and foster growth. These data-driven insights support organizations in making smarter, more efficient decisions across a range of functions, from marketing and finance to operations and supply chain management, ultimately helping businesses stay competitive in an increasingly data-driven world.




