
Last updated on 28th May 2025| 10412
- Introduction to SQL
- Importance of SQL in Data Science
- Key SQL Commands for Data Ops
- Advanced SQL Queries
- Data Cleaning Using SQL
- Data Manipulation Techniques
- SQL for Exploratory Data Analysis
- Best Practices for SQL in Data Science
- Common Interview Questions
- SQL vs NoSQL in Data Science
- Hands-on Project Ideas
- Conclusion
Introduction to SQL
SQL (Structured Query Language) is a powerful programming language for managing and manipulating relational databases. It allows users to interact with databases by querying, updating, and managing data stored in tables. SQL is fundamental for anyone working with databases, whether it’s for retrieving specific data, inserting new records, or performing complex operations across large datasets.At its core, SQL provides commands for data definition and manipulation Data Science Training often incorporates these concepts, along with control mechanisms, making SQL essential for tasks such as creating and modifying database structures, adding or deleting data, and ensuring data security and integrity. Common SQL commands include SELECT (to retrieve data), INSERT (to add new data), UPDATE (to modify existing data), and DELETE (to remove data). SQL also supports filtering and sorting of results, joining multiple tables for more complex queries, and performing aggregation operations like counting, summing, or averaging data. Its standardized syntax is supported by most relational database management systems (RDBMS), such as MySQL, PostgreSQL, Microsoft SQL Server, and Oracle, making SQL a versatile tool in both small- and large-scale database environments. As databases continue to grow in size and complexity, SQL remains a critical skill for developers, analysts, and anyone involved in data management.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Importance of SQL in Data Science
SQL (Structured Query Language) is a critical skill in data science, enabling data professionals to efficiently access, manage, and analyze large datasets stored in relational databases. Its importance in the data science workflow cannot be overstated. Here are the key reasons why SQL is essential in data science:
- Efficient Data Retrieval: SQL allows data scientists to quickly extract and retrieve large datasets from relational databases, which is often the first step in any data analysis or machine learning project an essential process when exploring the fundamentals of What is Data Science.
- Data Cleaning and Transformation: SQL is used to clean, filter, and transform raw data by handling missing values, aggregating data, and preparing it for further analysis, streamlining the data preprocessing phase.
- Combining Data from Multiple Sources: SQL’s ability to perform joins across different tables enables data scientists to merge datasets, providing a more comprehensive view for analysis.
- Data Aggregation: SQL makes it easy to perform aggregation functions like sum, average, and count, helping data scientists derive insights and summary statistics from large datasets.
- Optimized Performance: SQL is optimized for querying large volumes of data efficiently, making it an essential tool for handling big data stored in relational databases.
- Integration with Analytics Tools: SQL seamlessly integrates with data science tools like Python, R, and Tableau, enabling data scientists to extract, analyze, and visualize data directly within their preferred environment.
Key SQL Commands for Data Ops
The foundation of SQL lies in its basic commands, which include SELECT and INSERT. SQL (Structured Query Language) is the foundation for interacting with relational databases, and mastering its basic commands is essential for anyone working with data. The three most commonly used SQL commands SELECT, INSERT, and UPDATE allow users to retrieve, add, and modify data in databases, respectively, forming a foundational skill set relevant to the Future Scope of Artificial Intelligence. The SELECT statement is used to query and retrieve specific data from one or more tables. It can be used with clauses such as WHERE to filter records, ORDER BY to sort results, and JOIN to combine data from multiple tables. For example, SELECT name, age FROM employees WHERE department = ‘Sales’; retrieves the names and ages of employees in the Sales department. The INSERT statement is used to add new records to a table. For instance, INSERT INTO employees (name, age, department) VALUES (‘John Doe’, 30, ‘Marketing’); adds a new employee to the database. This command allows for the insertion of multiple rows at once, improving efficiency when dealing with bulk data. The UPDATE statement is used to modify existing records in a table. It allows users to change the values of specific columns based on a condition, such as UPDATE employees SET age = 31 WHERE name = ‘John Doe’; which would update the age of John Doe to 31. The UPDATE command can also be used with multiple conditions to perform more complex data modifications. These basic commands form the core of SQL and are frequently used in data manipulation and database management. By mastering SELECT, INSERT, and UPDATE, users can efficiently interact with and manipulate relational databases, making SQL a crucial tool for data analysis, application development, and business intelligence.
Advanced SQL Queries
Advanced SQL queries such as JOIN and UNION are essential tools for combining and manipulating data from multiple tables, making them indispensable for complex data analysis and reporting. The JOIN operation is used to combine rows from two or more tables based on a related column, typically a foreign key. There are different types of joins: INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL JOIN, each serving a different purpose. An INNER JOIN returns only the rows that have matching values in both tables, while a LEFT JOIN returns all rows from the left table and the matching rows from the right table, or NULL if no match is found. A RIGHT JOIN works similarly but returns all rows from the right table. A FULL JOIN combines the results of both LEFT and RIGHT joins, returning all records from both tables with NULL values where there is no match a key concept often emphasized in Data Science Training For instance, SELECT employees.name, departments.name FROM employees INNER JOIN departments ON employees.department_id = departments.id; retrieves the names of employees and their respective department names, combining data from the employees and departments tables based on a common department_id. On the other hand, the UNION operator is used to combine the results of two or more SELECT queries into a single result set. It eliminates duplicate rows by default, ensuring that only distinct records are returned. To include duplicates, you can use UNION ALL. For example, SELECT name FROM employees WHERE department = ‘Sales’ UNION SELECT name FROM employees WHERE department = ‘Marketing’; combines the names of employees from both the Sales and Marketing departments into one result set. The JOIN and UNION operators are powerful tools that help in performing complex data retrieval tasks by merging data from multiple sources, allowing for more comprehensive and insightful analysis. These advanced queries are fundamental in handling relational data efficiently, offering more flexibility and control over how data is combined and analyzed.
Data Manipulation Techniques
Data manipulation is the process of adjusting, organizing, and transforming data to make it suitable for analysis. Below are key data manipulation techniques:
- Filtering: Selecting a subset of data based on specific conditions, using tools like the WHERE clause in SQL to filter data based on attributes or ranges.
- Sorting: Arranging data in a specified order (ascending or descending), useful for organizing data and identifying trends, such as sorting sales data by date or revenue.
- Grouping and Aggregation: Grouping data into categories and using aggregation functions like SUM, AVG, COUNT, or MAX to summarize datasets, such as total sales by region or average customer spending.
- Merging and Joining: Combining data from multiple tables or sources using SQL joins (INNER JOIN, LEFT JOIN, RIGHT JOIN), merging data based on shared attributes like customer and order information.
- Data Transformation: Changing the structure or format of data, such as converting date formats or creating calculated fields to make data more consistent and usable.
- Handling Missing Values: Techniques like imputing missing values with the mean or median, or removing rows with missing data, ensuring the dataset remains complete and accurate.
- Pivoting and Unpivoting: Reorganizing data from rows to columns (pivoting) or converting columns into rows (unpivoting) to make data more readable and useful for analysis.
- Concatenation and Splitting: Combining multiple columns or strings into one (concatenation) or separating columns into smaller components (splitting), such as breaking down a full name into first and last names.

SQL for Exploratory Data Analysis
SQL is a fundamental tool in the process of Exploratory Data Analysis (EDA), allowing data analysts to efficiently explore, clean, and summarize datasets. The first step in EDA is often retrieving relevant data using SQL’s SELECT statement, which helps to focus on the necessary columns and records. Filtering data with the WHERE clause enables analysts to narrow down datasets based on specific criteria, such as dates or categories. Handling missing data is another crucial task, and SQL provides functions to identify and manage null values, ensuring a clean dataset for analysis a vital skill for landing the best data science jobs. Summarizing data through aggregation functions like COUNT(), AVG(), SUM(), MAX(), and MIN() helps to compute key statistics, while the GROUP BY clause enables analysts to segment data into meaningful groups, such as by region or product. Sorting data with ORDER BY makes it easier to spot trends or outliers, and combining data from multiple tables using JOIN operations further enriches the analysis. Although SQL doesn’t directly create visualizations, it plays a key role in preparing the raw data that can later be visualized using tools like Python, R, or Tableau. Overall, SQL is an essential part of EDA, providing the tools needed to understand the structure and key patterns of a dataset before diving into deeper analysis or predictive modeling.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Best Practices for SQL in Data Science
- Use Clear and Descriptive Aliases: When querying data, always use meaningful table and column aliases to make your SQL code more readable and understandable. Instead of generic names like t1 or t2, use descriptive aliases like sales_data or customer_info to improve clarity.
- Write Efficient Queries: Avoid unnecessary complexity in SQL queries. Use JOIN operations wisely to combine tables and filter data early in the query process with the WHERE clause to reduce the amount of data being processed, improving performance.
- Use Indexes Properly: Ensure that the most commonly queried columns are indexed to improve query performance. However, avoid over-indexing, as it can slow down INSERT and UPDATE operations.
- Leverage Aggregation Functions: Make use of SQL aggregation functions like SUM(), AVG(), COUNT(), and GROUP BY to derive meaningful insights from data during exploratory analysis. This helps to quickly summarize large datasets.
- Normalize and Clean Data Before Analysis: Ensure the data is cleaned and structured before performing any analysis. Use SQL queries to identify and handle missing values, duplicates, or inconsistencies. Data normalization, where appropriate, helps in comparing variables effectively an essential preparatory step before exploring advanced topics like How does TensorFlow work.
- Limit the Results in Development: During query development or testing, use the LIMIT or TOP clause to limit the number of rows returned. This speeds up query execution and helps you to debug more efficiently before running large queries on production databases.
- Avoid Subqueries When Possible: While subqueries are useful, they can often be inefficient and slow down performance. Whenever possible, try to use JOIN operations instead of subqueries for better performance.
- Document Your Queries: Always add comments to your SQL code, especially when dealing with complex queries. This makes it easier to understand the logic and intent behind the code, especially when revisiting it after some time or sharing it with others.
- This assesses your understanding of the different types of joins and their use cases in combining data from multiple tables.
- This question checks your knowledge of organizing data to minimize redundancy and improve data integrity within relational databases.
- Evaluates your ability to identify and handle NULL values in datasets, and how to deal with them in queries using functions like IS NULL, COALESCE(), or IFNULL().
- This tests your understanding of grouping data for aggregation versus sorting data based on specific columns.
- This question checks your knowledge of optimizing query performance using indexes and understanding their trade-offs in terms of speed and storage.
- Assesses your understanding of subqueries (nested queries) vs. joins, and when to use each approach in SQL queries.
- This evaluates your problem-solving skills in performance optimization, such as simplifying queries, using indexes, and analyzing query execution plans.
- Tests your understanding of combining multiple result sets, with UNION removing duplicates and UNION ALL including all records without removing duplicates.
- Analyze sales data from an e-commerce or retail database. Use SQL queries to extract insights like total sales by region, top-selling products, and sales trends over time. Customer Segmentation:
- Segment customers based on purchasing behavior, demographics, or account activity using SQL. Use GROUP BY, HAVING, and JOIN to identify key customer groups and their behaviors. Employee Performance Analysis:
- Query HR data such as salary, performance reviews, and promotions to analyze employee performance. Identify top performers and patterns in employee progression over time. Financial Analysis and Reporting:
- Analyze financial data to generate reports on profits, expenses, and financial ratios. Use SQL to create monthly financial reports and perform budget analysis. Inventory Management System:
- Build an inventory management system using SQL to track product stock levels, calculate reorder points, and analyze inventory turnover rates to optimize stock management incorporating Essential Data Analyst Skills for effective decision-making. Social Media Analysis:
- Query social media data to analyze engagement rates, sentiment trends, and user interactions. Use SQL to group data by hashtags, user demographics, and time periods for deeper insights. Customer Churn Prediction:
- Analyze customer churn by querying customer data like subscription usage and activity. Identify churn patterns and segment customers for targeted retention strategies. Web Traffic Analysis:
- Analyze web log data to track user behavior on a website. Use SQL to determine the most visited pages, session durations, and traffic sources to improve site performance and user engagement.
By following these best practices, data scientists can write efficient, readable, and scalable SQL queries, ensuring they get the most out of their data while improving performance and maintainability in the long term.
Common Interview Questions
1.What is the difference between INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL OUTER JOIN?
2.What is normalization, and why is it important in SQL?
3.How do you handle missing or NULL values in SQL?
4.What is the difference between GROUP BY and ORDER BY in SQL?
5.Explain the purpose of INDEXES in SQL and how they affect query performance.
6.What is a subquery, and how does it differ from a JOIN?
7.How would you optimize a slow-running SQL query?
8.What is the difference between UNION and UNION ALL?
These questions cover key aspects of SQL that are essential for data science tasks and will test your knowledge of data manipulation, optimization, and relational database management.
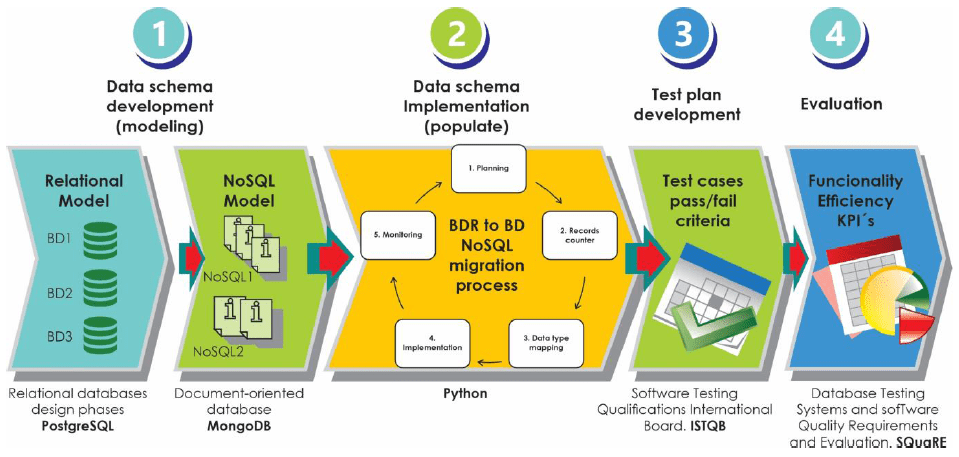
SQL vs NoSQL in Data Science
In data science, understanding the differences between SQL (Structured Query Language) and NoSQL (Not Only SQL) databases is essential, as they serve distinct purposes depending on the nature of the data and the project requirements. SQL databases are relational and structured, relying on tables, rows, and columns to store data. They are highly effective for tasks that require complex queries, data integrity, and transactions, making them ideal for structured data with predefined relationships, such as customer information or financial records. SQL databases support ACID (Atomicity, Consistency, Isolation, Durability) properties, ensuring reliable and consistent data transactions. On the other hand, NoSQL databases are non-relational and are designed to handle unstructured or semi-structured data, such as JSON, key-value pairs, or graph data. They provide flexibility in storing large volumes of diverse and rapidly changing data, making them suitable for projects like real-time analytics, big data, or applications involving high velocity data streams, like social media platforms or IoT devices topics often covered in an Artificial Intelligence Course Syllabus. NoSQL databases often scale horizontally, allowing for better performance with huge datasets. While SQL databases excel in traditional analytics and reporting, NoSQL databases offer scalability, flexibility, and speed for handling large-scale, unstructured data in data science projects, particularly those involving machine learning or data-driven applications. Thus, the choice between SQL and NoSQL depends on the type of data, the specific needs of the project, and the scalability requirements.
Hands-on Project Ideas
-
Sales Data Analysis:
These projects allow you to practice key SQL techniques while working on real-world datasets and gaining valuable insights for data-driven decision-making.
Conclusion
SQL is an indispensable skill in data science, serving as the foundation for efficient data retrieval, transformation, and analysis. Its versatility allows data scientists to handle everything from basic queries to complex data manipulations, making it an essential tool for extracting actionable insights from vast datasets. Whether it’s working with structured data in enterprise systems or preparing datasets for machine learning projects, SQL provides the necessary tools to bridge the gap between raw data and meaningful analysis. The simplicity and power of SQL make it highly accessible, and its integration into Data Science Training programs underscores its crucial role in data-driven decision-making across industries. As the field of data science continues to evolve, SQL remains a key player, adapting to new technologies and maintaining its relevance in handling data. For data scientists, mastering SQL not only enhances technical expertise but also unlocks numerous career opportunities in various sectors, from business and finance to healthcare and technology. The importance of SQL cannot be overstated, as it is a cornerstone of modern data science, enabling professionals to efficiently manage and analyze data at scale. With its enduring presence and ability to streamline data processes, SQL is an essential skill for anyone looking to build a successful career in the ever-growing field of data science.




