
Last updated on 25th Apr 2025| 10186
- Introduction to U-Net
- History and Development of U-Net
- U-Net Architecture Explained
- Applications in Medical Image Segmentation
- U-Net Variants and Improvements
- Training a U-Net Model
- Loss Functions for U-Net
- Data Augmentation in U-Net
- Performance Evaluation Metrics
- U-Net for Satellite and Aerial Image Analysis
- Comparison of U-Net with Other Architectures
- Future Trends in U-Net Research
Introduction to U-Net
U-Net is a convolutional neural network (CNN) architecture for image segmentation tasks. It was introduced by Olaf Ronneberger, Philipp Fischer, and Thomas Brox in 2015 for biomedical image segmentation. U-Net has since become widely adopted in medical imaging, satellite image analysis, and autonomous driving fields. The architecture is characterized by its U-shaped design, Data Science Course Training of a contracting path (encoder) and an expanding path (decoder). The encoder captures the contextual features, while the decoder reconstructs the output with precise localization. U-Net’s key strength lies in its ability to generate accurate segmentations with limited training data, making it highly effective in image-based AI applications.
History and Development of U-Net
The U-Net architecture was introduced in a 2015 paper titled “U-Net: Convolutional Networks for Biomedical Image Segmentation” at the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). Key motivations behind U-Net’s development, Traditional CNNs require Basics of Data Science datasets, but U-Net was designed to work efficiently with small datasets, which is standard in the medical domain. Its skip connections improved localization accuracy, addressing the limitations of earlier architectures like FCN (Fully Convolutional Networks). U-Net became the go-to architecture for biomedical image segmentation and later expanded into other computer vision tasks.
Gain in-depth knowledge of Data Science by joining this Data Science Online Course now.
U-Net Architecture Explained
The U-Net architecture is a powerful deep learning model designed for image segmentation tasks, particularly in the field of biomedical imaging. It consists of two primary components: the Contracting Path (Encoder) and the Expanding Path (Decoder). The encoder is made up of multiple convolutional layers followed by ReLU activations and max pooling, which progressively reduce the spatial dimensions of the input while increasing the depth of the feature maps. This path is responsible for extracting contextual information from the image, allowing the model to understand the overall structure. The decoder, or expanding path, mirrors the encoder’s structure and uses upsampling layers along with convolutional operations to gradually reconstruct the image’s spatial resolution. Crucially, it integrates low-level features from the encoder via skip connections, which link corresponding layers across the two paths. These skip connections are the hallmark of the U-Net model, Data Science Career Path the network to combine high-level contextual understanding with fine-grained localization. By merging deep semantic information with precise spatial details, U-Net achieves highly accurate segmentation results, even with limited training data.
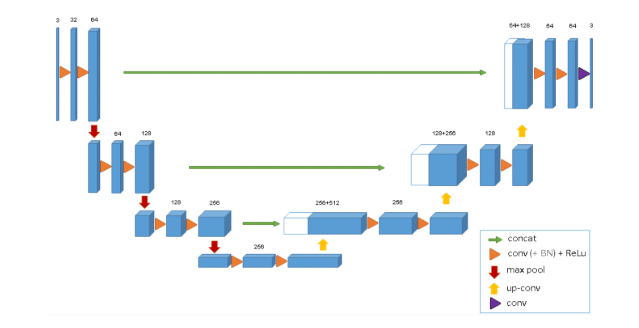
Applications in Medical Image Segmentation
U-Net Research revolutionized medical image analysis with its exceptional performance in segmentation tasks. Some of the key applications include:
- Tumor and Lesion Segmentation: Accurately segments brain Data Science Course Training , lung nodules, and liver lesions from MRI/CT scans.
- Organ and Tissue Segmentation: Used for automated organ segmentation in radiology and pathology.
- Cell Nuclei and Histology Image Analysis: Detects and segments individual cells in microscopy images..
- Disease Detection: It helps in identifying retinal abnormalities in ophthalmology..
- Key Advantage: U-Net can achieve high segmentation accuracy even with limited labeled data, making convolutional neural network ideal for biomedical applications..
- U-Net++: Introduces dense connections between encoder and decoder layers. It enhances feature propagation and reduces the semantic gap.
- Attention U-Net: Incorporates attention gates to focus on relevant regions. Improves segmentation accuracy by reducing false positives.
- 3D U-Net: Designed for volumetric image segmentation (3D MRI, CT scans). Uses 3D convolutions for better spatial context representation.
- ResUNet: Combines U-Net Research with ResNet blocks for improved feature extraction. Enhances the model’s model’s ability to capture complex patterns.
- Geometric Transformations: Rotation, flipping, and scaling help the model learn positional invariance.
- Elastic Deformations: Mimic real-world variations in medical images.
- Intensity Transformations: Brightness and contrast adjustments improve robustness.
- Noise Injection: Adds Gaussian noise to simulate different conditions.
- Impact: Data augmentation reduces overfitting and boosts generalization capabilities.
- Land Cover Classification: Classifies regions into categories (e.g., forest, water, urban).
- Road and Building Extraction: Identifies infrastructure features from satellite images.
- Disaster Impact Analysis: Detects damage from earthquakes, floods, or fires.
- Agricultural Monitoring: Segments fields and detects crop patterns.
- U-Net vs. FCN: U-Net uses skip connections, improving localization accuracy, whereas FCN lacks this feature. U-Net performs better on small datasets.
- U-Net vs. DeepLab: DeepLab uses dilated convolutions for larger receptive fields. U-Net is more straightforward and more effective for medical image segmentation.
- U-Net vs. Mask R-CNN: Mask R-convolutional neural network is better, for instance, segmentation. U-Net is superior for semantic segmentation tasks.
Start your journey in Data Science by enrolling in this Data Science Online Course .
U-Net Variants and Improvements
Over time, severalU-Net Model variants have emerged to address its limitations and improve performance:

Training a U-Net Model
Training a U-Net model for image segmentation involves a series of well-defined steps to ensure optimal performance and accuracy. The process begins with dataset preparation, where input images—such as medical scans or satellite imagery—are loaded and preprocessed. This includes normalizing pixel values and applying data augmentation techniques like flipping, rotation, or scaling to increase data diversity and reduce overfitting. Once the data is ready, the model is compiled using a suitable loss function such as binary cross-entropy or the a A Day in the Life of a Data Scientist , both of which are effective for segmentation tasks. An optimizer like Adam or SGD is then selected to handle the model’s learning process. During the training phase, a batch size of 16 to 32 is commonly used to balance memory usage and training stability. The model is typically trained for 50 to 100 epochs, with early stopping to prevent overfitting and checkpoint saving to retain the best-performing model. Once training is complete, the model’s performance is assessed on a validation and testing set, using metrics like IoU (Intersection over Union) and the Dice coefficient to evaluate segmentation accuracy. These steps collectively ensure that the U-Net model is well-trained and capable of producing precise, pixel-level predictions.
Aspiring to lead in Data Science? Enroll in ACTE’s Data Science Master Program Training Course and start your path to success!
Loss Functions for U-Net
Selecting the appropriate loss function is critical for the effectiveness of a U-Net model in image segmentation tasks, as it directly influences the model’s ability to learn accurate pixel-wise predictions. For binary segmentation, Binary Cross-Entropy Loss is a common choice, as it measures the difference between the predicted and actual pixel probabilities. However, it may struggle with class imbalance. To address this, Dice Loss is often preferred, especially in medical imaging, as it evaluates the overlap between predicted and ground truth masks, making it highly effective in scenarios where foreground and Data Scientist Salary in India classes are unevenly distributed. Another strong candidate is Jaccard Loss (also known as IoU Loss), which calculates the Intersection over Union between predicted and actual masks, further helping to reduce the impact of class imbalance. Additionally, Focal Loss is beneficial when working with highly imbalanced datasets, as it emphasizes difficult-to-classify samples by assigning them greater weight during training. Best practice in many medical image segmentation tasks involves using Dice Loss or IoU Loss, as they tend to provide better accuracy and are more aligned with the goals of convolutional neural networks designed for precise, structure-aware segmentation.
Data Augmentation in U-Net
Data augmentation enhances the model’s ability to generalize, especially when the dataset is small:
Performance Evaluation Metrics
Evaluating the performance of a U-Net model in image segmentation requires a set of specialized metrics that accurately reflect the quality of the predicted masks. One of the most commonly used metrics is the Dice Similarity Coefficient (DSC), which measures the overlap between the predicted segmentation and the ground truth mask. It is particularly favored in medical image segmentation due to its effectiveness in assessing how well two regions align, even in the presence of class imbalance. Another essential metric is Intersection over Union (IoU), which calculates the ratio of the intersection to the union of the predicted and actual masks, providing a solid indication of segmentation accuracy. Pixel Accuracy is also used, measuring the Data Collection of correctly classified pixels across the entire image, but it may be less informative in imbalanced datasets. For more spatially sensitive applications, the Hausdorff Distance is employed, which evaluates the maximum distance between the boundaries of the predicted and true masks—helpful in detecting shape and contour discrepancies. Among all, the Dice coefficient stands out as a key metric, especially in healthcare applications, due to its reliability in evaluating region-based similarity between predicted and actual segmentations.
U-Net for Satellite and Aerial Image Analysis
U-Net Research is widely used for satellite and aerial image processing:
Comparison of U-Net with Other Architectures
Preparing for Data Science interviews? Visit our blog for the best Data Science Interview Questions and Answers!
Future Trends in U-Net Research
The future of U-Net architecture is poised for exciting advancements, as researchers continue to explore ways to enhance its capabilities. One promising direction is the development of hybrid models that combine Data Science Course Training with transformers. This integration is expected to improve accuracy by leveraging transformers’ ability to capture long-range dependencies and contextual relationships, which can complement U-Net’s pixel-level localization strengths. Another key trend is the evolution of 3D and multimodal U-Net models, which are designed to handle volumetric data and multi-channel image analysis, making them suitable for more complex datasets like medical scans (e.g., CT or MRI) or satellite imagery. Self-supervised learning is also emerging as a significant area of research, as it reduces the dependency on large labeled datasets. By learning from unlabeled data, these models can improve efficiency and scalability, especially in data-scarce scenarios. Finally, Automated Architecture Search (NAS) is gaining traction, allowing for automatic optimization of U-Net’s architecture, potentially leading to more efficient and specialized models tailored for specific segmentation tasks. These innovations will continue to drive the versatility and precision of U-Net models, expanding their applications across various fields.




