
Last updated on 25th Apr 2025| 7516
- Introduction to Loss Functions
- Mean Squared Error (MSE)
- Mean Absolute Error (MAE)
- Binary Cross-Entropy
- Categorical Cross-Entropy
- Hinge Loss for SVMs
- Triplet Loss for Face Recognition
- Choosing the Right Loss Function
- Conclusion
Introduction to Loss Functions
Loss functions are a fundamental component of machine learning models, serving as a crucial mechanism for evaluating the model’s performance. They quantify the difference between the predicted values (output from the model) and the actual target values (true values from the dataset). This difference is commonly referred to as the “error” or “loss.” The role of the loss function is to guide the optimization process, providing valuable feedback that helps the model adjust its parameters during training. The goal of training a machine learning model is to minimize the loss function, thereby reducing the error between predictions and actual outcomes. By iteratively adjusting its parameters (such as weights in a neural network), the model learns to make more accurate predictions over time. In Data Science Training , this optimization process typically uses algorithms like gradient descent to minimize the loss, helping the model converge toward the best possible solution. The choice of loss function can have a significant impact on the model’s convergence speed, accuracy, and generalization capabilities. A well-chosen loss function ensures that the model learns effectively, avoids overfitting, and converges efficiently to an optimal solution. Conversely, selecting an inappropriate loss function for a given problem can hinder the model’s learning process, resulting in suboptimal performance. In summary, loss functions are integral to the training and optimization of machine learning models, as they act as the primary feedback mechanism that helps the model improve its predictions. Selecting the appropriate loss function is critical, as it directly influences the model’s ability to generalize and solve the task at hand effectively.
Eager to Acquire Your Data Science Certification? View The Data Science Course Offered By ACTE Right Now!
Mean Squared Error (MSE)
Mean Squared Error (MSE) is a standard loss function used for regression tasks. It calculates the average of the squared differences between predicted and actual values. The formula is:
- MSE=1n∑i=1n(yi−y^i)2\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2
MSE penalizes more significant errors due to squaring, making it sensitive to outliers. It is ideal for scenarios where large deviations need to be penalized but can be affected by noise.
Mean Absolute Error (MAE)
Mean Absolute Error (MAE) is another regression loss function that calculates the average absolute differences between predicted and actual values. The formula is:
- MAE=1n∑i=1n∣yi−y^i∣\text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i – \hat{y}_i|
MAE treats all errors equally, making it less sensitive to outliers than MSE. It is suitable for cases where robustness to outliers is required, such as in Deep Learning Projects, but may lead to slower convergence.
Binary Cross-Entropy
Binary Cross-Entropy is used for binary classification problems, measuring the difference between the predicted and actual probability distributions. The formula is:
- BCE=−1n∑i=1n[yilog(y^i)+(1−yi)log(1−y^i)]\text{BCE} = -\frac{1}{n} \sum_{i=1}^{n} [y_i \log(\hat{y}_i) + (1 – y_i) \log(1 – \hat{y}_i)]
BCE penalizes incorrect predictions by comparing the predicted probabilities with the true labels. It is commonly used in logistic regression and binary classifiers, particularly in Applications Deep Learning, ensuring well-calibrated probabilistic outputs.
Excited to Obtaining Your Data Science Certificate? View The Data Science Training Offered By ACTE Right Now!
Categorical Cross-Entropy
Categorical Cross-Entropy is used for multi-class classification tasks. It measures the distance between the predicted and actual class distributions. The formula is:
- CCE=−∑i=1n∑j=1cyijlog(y^ij)\text{CCE} = -\sum_{i=1}^{n} \sum_{j=1}^{c} y_{ij} \log(\hat{y}_{ij})
It assigns a higher penalty to incorrect predictions with higher confidence. CCE is commonly used with softmax activation for multi-class problems, ensuring the model optimally distinguishes between classes, and is frequently emphasized in Data science Training for its effectiveness in classification tasks.
Interested in Pursuing Data Science Master’s Program? Enroll For Data Science Master Course Today!
Hinge Loss for SVMs
Hinge Loss is used in Support Vector Machines (SVMs) for binary classification. It penalizes incorrect predictions and enforces a margin of separation. The formula is:
- Hinge Loss=∑i=1nmax(0,1−yi⋅y^i)\text{Hinge Loss} = \sum_{i=1}^{n} \max(0, 1 – y_i \cdot \hat{y}_i)
It encourages correct predictions with a margin, making the model robust against misclassifications. Hinge Loss is suitable for linear and kernel-based SVM models.

Triplet Loss for Face Recognition
In face recognition and metric learning, triplet loss is used to optimize the distance between embeddings. It compares an anchor, positive, and negative sample. The formula is:
- L=max(0,D(a,p)2−D(a,n)2+m)L = \max(0, D(a, p)^2 – D(a, n)^2 + m)
Where:
- Aa = anchor sample
- pp = positive sample
- nn = negative sample
Using Deep Learning Algorithms, it ensures that the model minimizes the distance between positive pairs and maximizes it for antagonistic pairs, improving similarity detection accuracy.
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
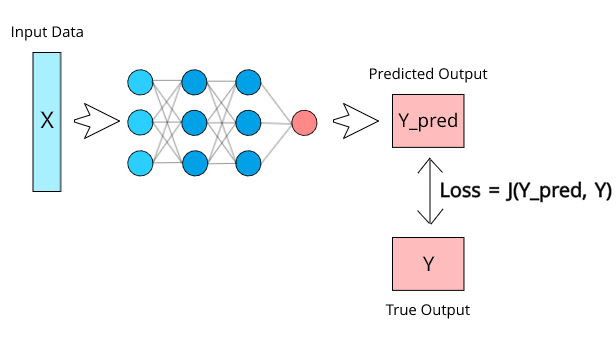
Choosing the Right Loss Function
Choosing the proper loss function depends on the problem type and model objectives, and this consideration varies significantly between traditional Machine Learning vs Deep Learning approaches.
- Regression: MSE, MAE, Huber Loss, Log-Cosh.
- Binary classification: Binary Cross-Entropy, Hinge Loss.
- Multi-class classification: Categorical Cross-Entropy, KL Divergence.
- Distance-based learning: Contrastive Loss, Triplet Loss.
- The proper loss function ensures accurate model convergence, better generalization, and improved performance.
Conclusion
In deep learning, selecting the right loss function is crucial for the model’s success and overall performance. Loss functions serve as the backbone for training, guiding the optimization process to minimize error and achieve better predictions. Each type of task whether it’s regression, classification, or specialized applications like face recognition requires a tailored loss function to ensure optimal convergence and model efficiency. From Mean Squared Error (MSE) for regression tasks to Triplet Loss in face recognition, loss functions provide the feedback necessary for adjusting the model’s parameters. In Data Science Training, they enable models to better align their predictions with the actual target values, whether predicting continuous outputs, binary class labels, or multiple categories. Ultimately, the choice of loss function has a profound impact on a model’s ability to learn effectively, avoid overfitting, and generalize well to unseen data. Understanding the intricacies of each loss function allows data scientists and machine learning engineers to choose the best-suited option for the problem at hand, ensuring the model converges efficiently and performs at its best. In summary, loss functions are an essential part of deep learning, and choosing the right one is a critical step in achieving high-performing models. The right loss function not only speeds up convergence but also helps the model understand the task more effectively, making it an indispensable tool in the machine learning process.




