
Last updated on 22nd Apr 2025| 10324
- Introduction to LightGBM
- How LightGBM Works
- Comparison with Other Gradient Boosting Algorithms
- Advantages of Using LightGBM
- Installing LightGBM
- Hyperparameter Tuning in LightGBM
- Implementing LightGBM in Python
- Use Cases of LightGBM in Machine Learning
- Handling Imbalanced Data with LightGBM
- Common Errors and Debugging in LightGBM
- Best Practices for Optimizing LightGBM Models
Introduction to LightGBM
LightGBM (Light Gradient Boosting Machine) is a robust, efficient, and scalable implementation of gradient boosting. Developed by Microsoft, It is designed for speed and performance and is well-suited for large datasets and high-dimensional features. Due to its ability to handle large datasets efficiently and provide fast training times, it has become a popular choice in machine learning competitions and real-world applications. Gradient boosting is a machine learning technique that builds a series of weak learners (usually decision trees) and Data Science Course Training them to form a strong predictive model. LightGBM improves upon traditional gradient boosting methods by using several innovative techniques, such as histogram-based learning and leaf-wise tree growth, to optimize training time and model performance. This article will explore LightGBM’s advantages, installation process, key parameters, hyperparameter tuning, and everyday use cases in machine learning.
How LightGBM Works
LightGBM is based on the gradient boosting framework, which builds decision trees sequentially by focusing on the residual errors of the previous tree. However, LightGBM introduces several innovations that enhance its performance:
- Histogram-based Learning: Unlike traditional gradient boosting methods, which process each feature value individually, LightGBM bins continuous features into discrete bins. This histogram-based approach reduces memory usage and speeds up the computation by operating on fewer distinct values.
- Leaf-wise Tree Growth: Traditional gradient boosting algorithms typically use level-wise tree growth, where the algorithm grows trees level by level. In contrast, LightGBM uses a leaf-wise approach, choosing the leaf with the most significant loss reduction to grow further. A Algorithm in AI often leads to deeper trees but can reduce training time and overfitting.
- Gradient-based One-Side Sampling (GOSS): LightGBM uses GOSS to select data points for building trees. It prioritizes data points with more significant gradients, which are more informative for model improvement. This reduces the number of data points needed for training, thus speeding up the process.
- Exclusive Feature Bundling (EFB): This technique reduces the dimensionality of the dataset by bundling mutually exclusive features (those that rarely take non-zero values simultaneously) into a single feature. This can lead to faster training times and improved model performance. These methods make LightGBM one of the fastest gradient-boosting frameworks available. It can handle very large datasets while maintaining high accuracy.
Gain in-depth knowledge of Data Science by joining this Data Science Online Course now.
Comparison with Other Gradient Boosting Algorithms
LightGBM is part of a family of gradient-boosting algorithms that includes XGBoost and CatBoost. While these algorithms share the basic concept of boosting, each has unique characteristics.
LightGBM vs. XGBoost:
- Speed: LightGBM tends to be faster than XGBoost, especially on larger datasets, due to its histogram-based learning and leaf-wise growth.
- Memory Efficiency: LightGBM uses less memory than XGBoost due to its binning technique and efficient handling of categorical features.
- Accuracy: LightGBM and XGBoost offer high predictive accuracy, but LightGBM often performs better on large datasets due to its faster convergence.
- Handling Categorical Features: While both LightGBM and CatBoost handle categorical features, CatBoost automatically processes categorical variables without needing to encode them manually, making more convenient in some scenarios.
- Model Interpretability: CatBoost often has more interpretable models due to its treatment of categorical variables, whereas LightGBM requires manual preprocessing.
- Performance: LightGBM typically outperforms CatBoost regarding training speed and scalability, particularly with larger datasets. LightGBM is an excellent choice for scenarios where speed and memory efficiency are crucial, and it performs excellently on large-scale datasets.
- num_leaves: The maximum number of leaves in a tree. Larger values lead to more complex models, but increasing this value may also lead to overfitting.
- learning_rate: Determines the step size at each iteration while moving toward a minimum of the loss function. Lower values improve model performance but require more trees to converge.
- n_estimators: The number of boosting iterations (trees). More estimators generally improve the model but increase computation time.
- max_depth: The maximum depth of each tree. Limiting the depth can help prevent overfitting.
- min_data_in_leaf: The minimum number of Compare two Columns in Excel points required in a leaf. This helps control overfitting by ensuring that leaves don’t become too specific.
- Subsample: The fraction of data used to build each tree. Using a smaller fraction can help prevent overfitting.
- colsample_bytree: The fraction of features to use for each tree. It can help avoid overfitting by ensuring diversity in the trees.
- boosting_type: The boosting algorithm to use. Options include “gbdt” (gradient boosting decision tree), “dart” (dropout), and “goss” (gradient-based one-side sampling).
- Classification: LightGBM is commonly used for binary and multiclass classification tasks, such as spam detection, fraud detection, and customer segmentation.
- Regression: It can be used for regression tasks, such as predicting house prices, stock prices, or demand forecasting.
- Ranking: LightGBM can be used for ranking tasks, such as recommendation systems, where the goal is to rank Mastering the Indirect Function in Excel l based on relevance.
- Anomaly Detection: In scenarios where detecting rare events is essential, such as network intrusion detection or fault detection in industrial systems, LightGBM can help identify anomalies.
- Class Weights: You can assign different weights to each class by using the is_unbalance parameter or scale_pos_weight for binary classification. This helps the model pay more attention to the minority class.
- Balanced Subsampling: You can use the subsample parameter to randomly sample data points, ensuring a balanced distribution of courses in each iteration.
- Custom Loss Functions: In some cases, creating a custom loss function that penalizes misclassifications of the minority class can improve performance.
- Memory Issues: LightGBM is memory-efficient, but memory limitations may still occur on massive datasets. Reducing the number of features or using smaller batches for training can help mitigate this.
- Overfitting: If your model overfits the training data, use smaller values for num_leaves and max_depth or increase the min_data_in_leaf parameter.
- Parameter Misconfiguration: Ensure that the parameters like learning_rate, n_estimators, and num_leaves are tuned correctly. Use techniques like cross-validation to help identify the best parameters.
- Convergence Issues: In some cases, the model may not converge. This can happen if the learning rate is too high or if the model is too complex. Reduce the learning rate or increase early stopping.
- Tune Hyperparameters: Use a grid or random search to find optimal hyperparameters such as learning_rate, num_leaves, and max_depth.
- Regularize the Model: Reduce overfitting by using regularization techniques such as min_data_in_leaf or lambda_l1 and lambda_l2.
- Handle Missing Data: LightGBM can handle missing Data Science Course Training natively by treating it as a separate value, but be sure to manage missing data carefully in the dataset.
- Leverage GPU: LightGBM’s GPU implementation can speed up training for massive datasets.
LightGBM vs. CatBoost:
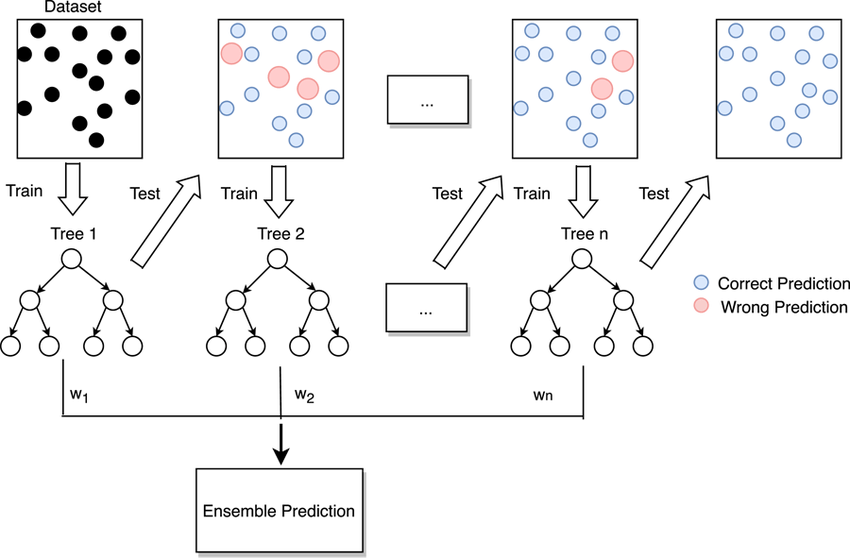
Advantages of Using LightGBM
There are several key advantages to using LightGBM for machine learning tasks, High Performance LightGBM is designed to handle large datasets efficiently, with faster training times than other gradient-boosting methods. Scalability can handle large amounts of data with high-dimensional features, making Data Science Course Training suitable for real-world big data applications. Low Memory Usage LightGBM’s histogram-based algorithm and efficient handling of categorical data reduce memory usage, making it well-suited for memory-constrained environments. Accuracy Due to the combination of techniques like leaf-wise tree growth and GOSS, LightGBM often delivers state-of-the-art performance on tasks such as classification and regression. Parallel and Distributed Learning LightGBM supports parallel and distributed computing, allowing it to scale to massive datasets and utilize multiple CPUs or machines for training.
Dive into Data Science by enrolling in this Data Science Online Course today.
Installing LightGBM
To install LightGBM, you can use the following command, assuming you are using Python and Pip installs light gum, If you are using Anaconda, you can install LightGBM via the conda package manager, Conda install -c conda-forge light gum. Instructions for building LightGBM from the source can be found on the official LightGBM GitHub repository.
Key Parameters in LightGBM:
LightGBM has several important parameters that allow users to fine-tune the model for better performance:

Hyperparameter Tuning in LightGBM
Hyperparameter tuning is a critical part of building a machine-learning model. In LightGBM, standard techniques for hyperparameter tuning include, Grid Search through a manually specified subset of the hyperparameter space. Random Search: Randomly sampling from a larger hyperparameter space. Autoencoders in Deep Learning Optimization Using probabilistic models to select hyperparameters based on previous performance. Using cross-validation (e.g., K-fold) to assess the model’s performance on different parameter combinations. We can optimize hyperparameters like num_leaves, learning_rate, and n_estimators to build an effective LightGBM model using these methods.
Take charge of your Data Science career by enrolling in ACTE’s Data Science Master Program Training Course today!
Implementing LightGBM in Python
Implementing LightGBM in Python is a straightforward process that begins with preparing your dataset, typically using pandas for data manipulation and scikit-learn for train-test splitting. LightGBM requires the features to be numeric, so categorical values should be label encoded or handled with LightGBM’s built-in categorical support. After installing the lightgbm package via pip, you can import it and create a dataset using lgb.Dataset(). Then, define your model parameters—such as objective, learning_rate, and num_leaves—and train the model using lgb.train() or LGBMClassifier() if you’re using the scikit-learn API. Finally, use the trained model to make predictions and evaluate performance with metrics like accuracy, AUC, or RMSE, depending on your task. LightGBM is known for its speed and accuracy, especially on large datasets and high-dimensional features.
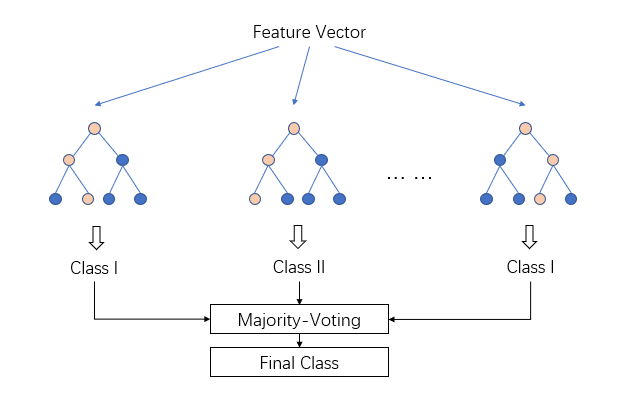
Use Cases of LightGBM in Machine Learning
LightGBM is widely used in various machine-learning applications, including:
Handling Imbalanced Data with LightGBM
Imbalanced data is a common problem in many machine-learning tasks. LightGBM provides several ways to address this issue:
Want to ace your Data Science interview? Read our blog on Data Science Interview Questions and Answers now!
Common Errors and Debugging in LightGBM
Best Practices for Optimizing LightGBM Models
Use Early Stopping: Monitor the validation loss and stop training when the model starts to overfit.




