
Last updated on 13th May 2025| 10080
- What is K Means Clustering
- What is Data Science Clustering ?
- What is Python
- Understanding K-Means Clustering
- Working on K-Means Clustering
- Implementation of K-Means Clustering in Python
- Elbow Method in K-Means Clustering
- Applications of K-Means Clustering
- Advantages and Limitations of K-Means Clustering
- Conclusion
What is K means by Clustering
K-Means Clustering is an unmonitored device for gaining knowledge of rules for grouping facts into clusters primarily based on similarity. The aim is to partition a dataset into K distinct, non-overlapping clusters, where every fact factor belongs to the cluster with the closest mean (centroid). Data Science Course Training works iteratively to decrease the variance inside every cluster and maximize the variance among clusters. The set of rules begins off evolving through randomly initializing K centroids, then assigns every fact factor to the closest centroid primarily based totally on distance (normally Euclidean). After that, it recalculates the centroids because the common of all aspects in every cluster repeats the venture and replaces steps until the centroids do not alternate appreciably or a wide variety of iterations is reached.
What is Data Science Clustering ?
Data technology is an interdisciplinary area that mixes statistics, mathematics, programming, and area knowledge to extract significant insights from dependent and unstructured statistics. Most Effective Data Collection Methods includes strategies, statistics mining, device learning, synthetic intelligence, and massive statistics analytics to discover patterns, expect outcomes, and help decision-making. Data technology is broadly used throughout industries like healthcare, finance, retail services, manufacturing, and targeted marketing, assisting groups to enhance efficiency, optimize operations, and decorate purchaser experiences. With the developing availability of statistics and improvements in technology, statistics technology continues to evolve, gambling a critical function in fixing complicated issues and using innovation in the virtual age. scope and significance of data science applications will only expand further.
Learn how to manage and deploy cloud services by joining this Data Science Online Course today.
What is Python?
Python is a high-level, interpreted programming language regarded for its simplicity, clarity, and versatility. Created through Guido van Rossum and primarily launched in 1991, Python emphasizes code clarity with its smooth and easy-to-recognize syntax. It is a famous desire for novices and skilled builders alike. It helps a couple of programming paradigms, consisting of procedural, object-oriented, and practical programming. Python is extensively utilized in numerous fields, including internet development, facts science, device-gaining knowledge, synthetic intelligence, automation, and clinical computing. Python`s cross-platform nature and integration abilities make it an effective device for constructing easy scripts and large-scale applications.
Unlock your potential in Data Science with this Data Science Online Course .
Understanding K-Means Clustering
It operates by dividing the facts into K-specific clusters. Here, every cluster ought to have a primary factor called a centroid. Most Effective Data Collection Methods centroid is used to symbolize the commonality of all of the factors found in that group. Transferring the centroids until they forestall changing allows this set of rules to adjust the clusters. The principal intention of K-Means Clustering is to arrange comparable facts and factors inside the identical group/clusters.
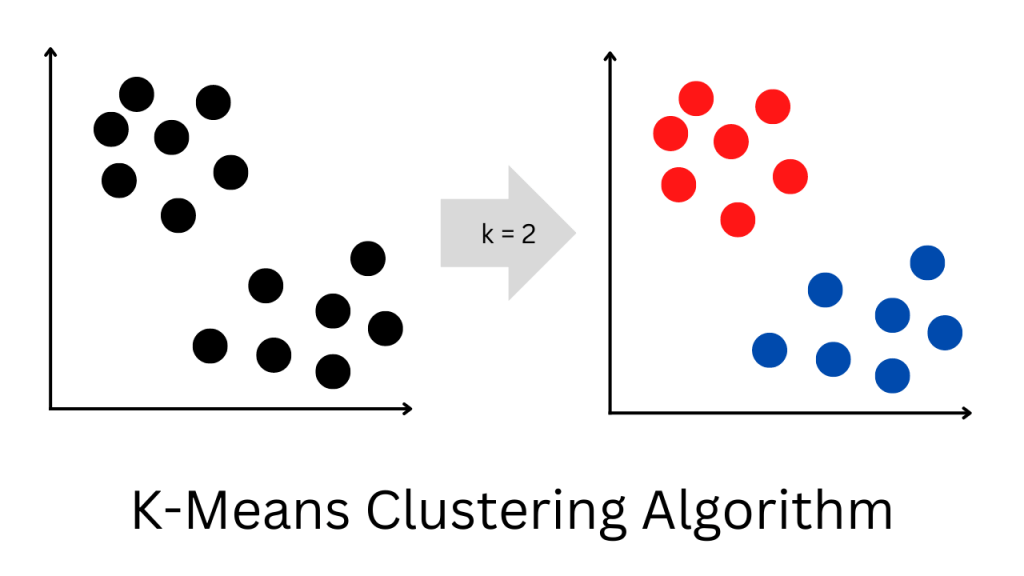
Working on K-Means Clustering
- Suppose we’re given a facts set of diverse objects with precise features, which incorporate corresponding values (much like vectors). Here, the project is to categorize the objects into organizations. To do this, we can use the K-Means clustering set of rules.
- The “K” within the call of the regulations symbolizes the variety of organizations/clusters that we need to categorize our objects into.These rules will categorize the objects into okay organizations or clusters incorporating comparable objects/facts factors. To calculate the similarity, Tools of R Programming can use the Euclidean distance as a measurement. The running of the set of rules is given below:
- At first, we want to initialize okay factors randomly, which are referred to as method or cluster centroids. Next, we assign every object to its nearest suggestion, and then we need to alter the suggested coordinates with the contemporary objects falling into that cluster.
- We want to copy this manner for a given variety of iterations, and in the end, we can have our clusters

Implementation of K-Means Clustering in Python
For implementation, we can use the Mastering the Indirect Function in Excel -analyze library, which presents an honest implementation of the K-method clustering set of rules.
- Step 1: Importing the vital libraries
- Step 2: Create a custom dataset
- Step 3: Initialize the Random Centroids
- Step 4: Plotting the random initialize middle with facts factors
- Step 5: Defining Euclidean Distance
- Step 6: Creating the feature to assign and replace the cluster middle
- Step 7: Create the feature to expect the cluster for the datapoints
- Step 8: Assign, Update, and expect the cluster middle
- Step 9: Plotting the facts factors with their expected cluster middle
Aspiring to lead in Data Science? Enroll in ACTE’s Data Science Master Program Training Course and start your path to success!
Elbow Method in K-Means Clustering
It identifies the proper stability between the number of clusters and the within-cluster variance. It is essential to pick out the number of clusters because using too few clusters might also oversimplify the records while using too many clusters might result in overfitting.
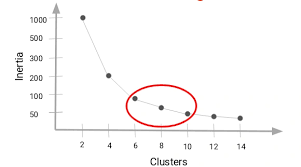
- Understanding the Elbow Method: The most important idea behind the Elbow Method is calculating the WCSS (Within-Cluster Sum of Squares). It is used for specific values of K, after which it identifies the factor in which the charge of WCSS decreases significantly. Data Science Course Training factor is called the elbow factor, which suggests the surest quantity of clusters.
- WCSS (Within-Cluster Sum of Squares): It is used to degree the compactness of the clusters.
- K increases: As the fee of K increases, WCSS decreases. This is because clusters grow to be smaller and extra compact. However, after a positive factor, the lower withinside the fee of K is minimal. This bureaucracy has an elbow-like form inside the graph. Here, including extra clusters no longer lessens the WCSS.
- Steps to Implement the Elbow Method: You ought to carry out K-Means clustering for specific values of K (e.g., K = 1 to 10). You then ought to calculate the WCSS for every fee of K. Then you’ve got to devise K vs. WCSS for visualizing the elbow factor. Lastly, pick out the fee of K on the elbow factor. Applications of K-Means Clustering
- Customer Segmentation: K-Means clustering is used to group clients based on their shopping conduct for focused marketing.
- Anomaly detection: It is likewise used to detect uncommon record factors that don’t fit into any cluster.
- Document clustering: Macros in Excel is likewise used to organize files into subjects primarily based on the similarity of the content.
Preparing for Data Science interviews? Visit our blog for the best Data Science Interview Questions and Answers!
Advantages and Limitations of K-Means Clustering
- Advantages of K-Means Clustering: K-Means is easy to understand and implement, making it a popular preference for clustering duties, especially for beginners. Efficiency and Scalability: It is computationally green and works nicely with massive datasets. The set of rules has a time complexity of O(n), making it quicker than many clustering strategies. K-Means converges exceptionally quickly, especially with K Nearest Neighbors strategies like the K-Means++ initialization. K-Means can correctly organize the statistics factors when clusters inside the statistics are round and of comparable length stability. It may be utilized in various programs, including marketplace segmentation, report clustering, photograph compression, and sample recognition. The very last cluster of centroids and the undertaking of statistics factors are easy to apprehend and visualize, assisting in statistical evaluation and decision-making.
- Limitation of K-Means Clustering: One of the most significant obstacles is that the person should specify a wide variety of clusters in advance, which is usually not recognized or optimal. Sensitive to Initial Centroid Placement The very las t clusters can vary depending on the preliminary positions of the centroids. Poor initialization can cause suboptimal Clustering or convergence to a nearby minimal. Assumes Spherical and Equal-Sized Clusters K-Means works excellent while clusters are spherical and kind of the same in length and density Sensitive to Outliers and Noise Outliers can extensively affect the placement of centroids and cause wrong Clustering, as K-Means uses suggested values that aren’t sturdy to outliers. Not Ideal for Non-Linear Data Structures can’t efficiently separate statistics that aren’t always linearly separable or include complicated geometrical shapes (e.g., concentric circles or spirals). May Converge to Local Minima K-Means no longer assures a globally most appropriate solution; initially, it can be caught in a nearby minimal reliance.
Conclusion
In conclusion, K-Means clustering is an effective and broadly used set of rules for uncovering styles and herbal groupings inside unlabeled statistics. Its simplicity, speed, and scalability make it a famous preference for clustering duties in numerous domain names, including marketing, biology, and photograph processing. However, although it plays nicely in many scenarios, K-Means has obstacles, including the desire to specify the wide variety of clusters in Data Science Course Training , sensitivity to preliminary centroid placement, and trouble managing non-round or inconsistently sized clusters. Despite those challenges, K-Means remains a powerful device for statistics exploration and sample discovery while carried out as it should be with the right preprocessing and validation (like the elbow approach or silhouette score).




