
Last updated on 26th May 2025| 10188
- Introduction to Data Mining and Data Science
- Definition and Key Differences
- Data Mining Techniques and Algorithms
- Data Science Process and Methodologies
- Tools Used in Data Mining vs Data Science
- Applications of Data Mining
- Applications of Data Science
- Required Skills for Data Mining and Data Science
- Career Opportunities and Job Roles
- Salary Comparison: Data Mining vs. Data Science
- Real-World Use Cases
- Choosing the Right Path: Data Mining or Data Science
Introduction to Data Mining and Data Science
In today’s fast-paced digital age, the volume of data generated is immense. This data explosion has given rise to two significant disciplines: data Mining and Data Science, each aimed at harnessing the power of data to extract insights, predict trends, and enhance decision-making. While they often overlap in purpose and tools, the two fields serve different functions and follow distinct approaches.
Data Miningrefers to the process of identifying patterns, relationships, and anomalies within large datasets. It uses a combination of statistical, mathematical, and computational methods to uncover meaningful trends hidden in raw data. The goal is to extract relevant information that can inform strategic choices, often without a prior hypothesis. Techniques such as clustering, association rules, and classification are commonly used in this process.
Data ScienceIn contrast, it is a broader, multidisciplinary field. It integrates knowledge from statistics, machine learning, data analysis, and computer science to analyze and interpret both structured and unstructured data. Data Science Training plays a crucial role in equipping professionals with the skills to perform data cleaning, visualization, predictive modeling, and algorithm deployment for real-world applications. It enables organizations to make data-driven decisions by turning raw data into actionable insights. In essence, data mining can be viewed as a subset of data science, focused more narrowly on pattern discovery. Data science, with its expansive toolkit and focus on end-to-end data workflows, plays a more comprehensive role in solving complex problems across industries. Both are crucial in unlocking the full potential of data in the modern world.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Definition and Key Differences
Data MiningData mining is a process of analyzing large datasets to identify patterns, trends, and relationships that might not be immediately obvious. It’s heavily focused on exploring and summarizing data.
Key characteristics of data mining:- Involves algorithms to classify, cluster, and predict based on data.
- Focuses on uncovering patterns in existing data.
- Relies on historical data for predictive analysis. Data Science
- Encompasses a range of activities, from data collection to deployment.
- Includes tasks like data cleaning, analysis, and modeling.
- Uses machine learning and statistical models for decision-making. Key Differences:
- Scope: Data mining is more focused on finding patterns and relationships, while data science covers the entire data pipeline from data collection to predictive analytics and decision-making.
- Techniques: Data mining heavily relies on algorithms like clustering, classification, and association. Data science uses a broader array of techniques, including machine learning, data wrangling, and statistical modeling.
- Outcome: Data mining’s goal is to find hidden patterns, while data science aims to build predictive models and inform strategic decisions.
Data science is a field that involves using various tools, techniques, and algorithms to extract meaningful insights from data. It combines multiple disciplines such as statistics, computer science, and domain knowledge.
Key characteristics of data science: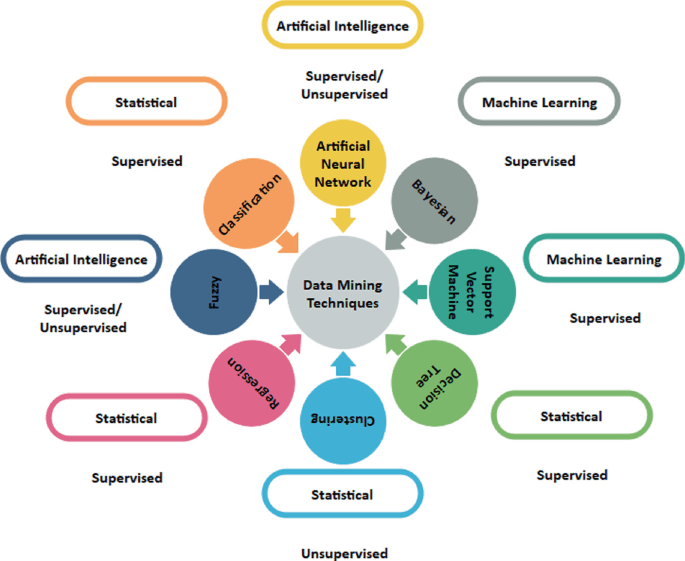
Data Mining Techniques and Algorithms
Data mining techniques are essential for extracting valuable insights from large datasets, and several well-established methods are widely used across various industries. Classification is a technique that assigns data into predefined categories, making it useful for tasks like spam detection or medical diagnoses. Common algorithms used in classification include Decision Trees, Random Forest, Naive Bayes, and Support Vector Machines (SVM). Clustering, another key technique, groups similar data points together and is often applied in customer segmentation and market research; popular clustering algorithms include K-Means, DBSCAN, and Hierarchical Clustering. Learn Data Science to better understand how these techniques fit into broader data strategies and gain the skills to apply them effectively. Association Rule Learning focuses on identifying interesting relationships between variables in large datasets, often used in market basket analysis to uncover items frequently purchased together, with Apriori and Eclat being the primary algorithms. Regression techniques are employed to model the relationship between dependent and independent variables, playing a significant role in forecasting and predicting numeric values such as sales figures; commonly used algorithms include Linear Regression, Logistic Regression, and Lasso Regression. Lastly, Anomaly Detection is used to identify data points that significantly deviate from the norm, making it crucial in areas like fraud detection; Isolation Forest and One-Class SVM are among the popular algorithms for this purpose. Collectively, these data mining techniques enable businesses and researchers to transform raw data into meaningful patterns and predictions, enhancing data-driven decision-making processes.
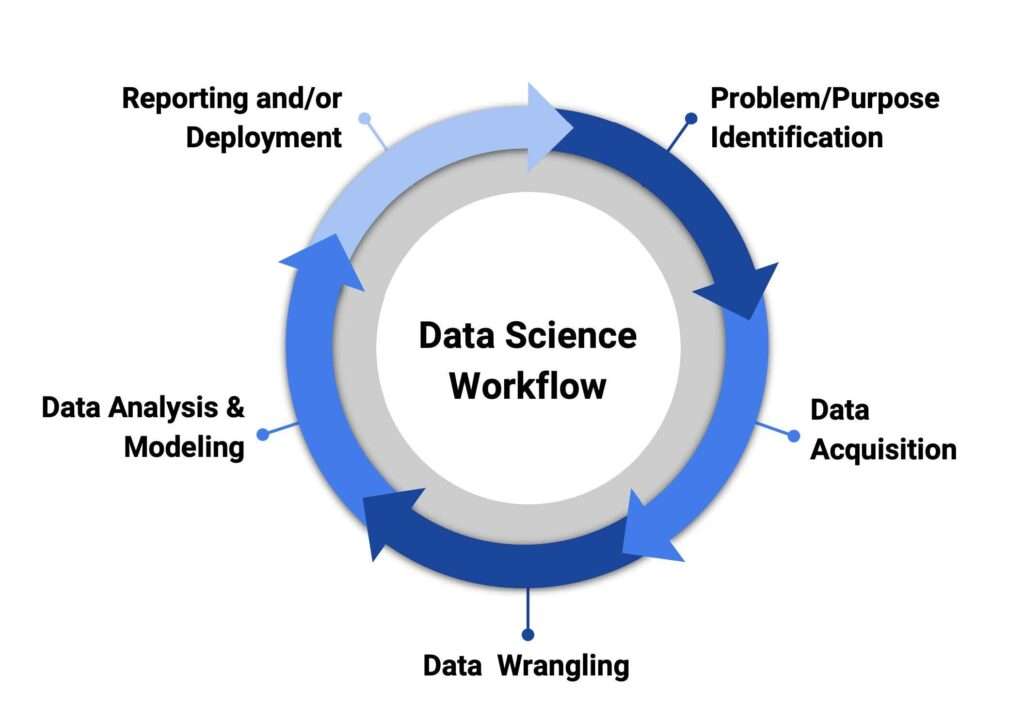
Data Science Process and Methodologies
The data science process is a structured approach to solving data problems, which typically involves the following steps:
- Problem Definition: Understanding the problem you need to solve and what data can help solve it. This is the first step to guide the entire project.
- Data Collection: Gathering data from various sources, including databases, external APIs, and web scraping.
- Data Cleaning and Preprocessing: This step involves dealing with missing values, duplicate data, and incorrect data formats to ensure the dataset is clean and usable.
- Exploratory Data Analysis (EDA): Analyzing the data using statistical tools and visualizations to understand the structure of the data and uncover trends, patterns, and correlations.
- Modeling: Building models using machine learning algorithms, which could involve classification, regression, or clustering, depending on the goal of the project.
- Evaluation: Assessing the performance of the model using appropriate metrics such as accuracy, precision, recall, or F1-score.
- Deployment and Monitoring: Deploying the model into production and continuously monitoring its performance to ensure it performs well over time.
Tools Used in Data Mining vs Data Science
There are various powerful tools available for both data mining and data science, each serving specific roles in the data analysis process. In the realm of data mining, tools such as RapidMiner provide an open-source platform that supports tasks like data preparation, modeling, and evaluation, making it accessible to both beginners and professionals. KNIME is another versatile platform used for analytics, reporting, and integrating different data mining processes, offering a user-friendly, visual workflow interface. Weka, a well-known suite of machine learning algorithms, is particularly effective for tasks such as classification and clustering and is widely used in academic and research environments for its simplicity and powerful features. On the other hand, data science tools cover a broader spectrum of tasks involving data manipulation, analysis, modeling, and visualization. Data Science Training can help professionals gain hands-on experience with these tools, enabling them to apply techniques effectively in real-world scenarios. Python is one of the most dominant languages in this field, supported by a rich ecosystem of libraries such as Pandas for data manipulation, NumPy for numerical computing, Scikit-learn for machine learning, and TensorFlow for deep learning applications. R is another key language, particularly favored for statistical analysis and creating high-quality data visualizations. Jupyter Notebooks play a critical role in data science workflows, offering an interactive environment for writing and running live code, visualizing results, and documenting the analysis. Tableau is a powerful data visualization tool often used in business intelligence to build interactive and shareable dashboards, helping users to gain insights from complex data. Together, these tools empower users to extract, process, analyze, and visualize data efficiently, supporting informed decision-making and problem-solving across various industries.

Applications of Data Mining
- Market Basket Analysis: Retailers use data mining to analyze customer purchase patterns and suggest products that are frequently bought together.
- Fraud Detection: Data mining is widely used in financial industries to detect fraudulent activities like credit card fraud by analyzing transaction patterns.
- Customer Segmentation: Companies use clustering algorithms to segment their customer base into different categories, enabling more personalized marketing strategies.
- Healthcare: Medical researchers use data mining to analyze patient data for disease predictions, treatment plans, and clinical decision-making.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Applications of Data Science
Data science plays a critical role in numerous real-world applications by leveraging advanced algorithms and data-driven techniques to solve complex problems across industries. One of the key areas is predictive analytics, where data science is used to forecast future outcomes such as stock market trends or consumer purchasing behavior by training machine learning models on historical data. This helps organizations make proactive, informed decisions. Another important application is Natural Language Processing (NLP), which enables machines to understand and interpret human language. NLP is widely used in speech recognition systems, sentiment analysis tools, and intelligent chatbots that enhance user interaction and automate customer service. In the domain of image and video analysis, data science is revolutionizing fields like security and healthcare by enabling systems to process and interpret visual data from cameras and medical imaging devices. Learning Data Science from Scratch can provide the foundational knowledge and practical skills needed to engage with these technologies effectively and contribute to their development. This supports activities such as facial recognition, anomaly detection, and diagnostic imaging. Additionally, recommendation systems are one of the most visible uses of data science in everyday life. Streaming services like Netflix and shopping platforms like Amazon rely heavily on data science to analyze user behavior and preferences, delivering personalized content and product suggestions that enhance user experience and drive engagement. Through these diverse applications, data science continues to transform the way businesses operate and how individuals interact with technology, turning raw data into actionable insights and intelligent systems.
Required Skills for Data Mining and Data Science
Skills for Data Mining:- Statistical Analysis: Ability to apply statistical techniques to identify patterns and trends.
- Knowledge of Algorithms: Familiarity with classification, clustering, and association algorithms.
- Data Visualization: Proficiency in presenting data in an easily digestible format using tools like Tableau or Power BI.
- Data Preprocessing: Skills in cleaning and transforming data for analysis.
- Programming: Knowledge of programming languages like Python or R for implementing algorithms. Skills for Data Science:
- Machine Learning: Understanding machine learning techniques like supervised and unsupervised learning, deep learning, and reinforcement learning.
- Data Wrangling: Ability to clean, transform, and prepare raw data for analysis.
- Statistical Knowledge: Strong foundation in statistical methods for hypothesis testing, probability, and regression.
- Big Data Technologies: Familiarity with tools like Hadoop and Spark for handling large datasets.
- Data Visualization: Expertise in creating compelling visualizations using libraries like Matplotlib, Seaborn, or visualization tools like Tableau.
Career Opportunities and Job Roles
Data Mining Career Roles:- Data Mining Engineer: Develops algorithms to analyze large datasets and uncover hidden patterns.
- Data Analyst: Analyzes data to identify trends and supports decision-making through insights.
- Business Intelligence Analyst: Uses data mining techniques to help businesses optimize operations and improve performance. Data Science Career Roles:
- Data Scientist: Develops advanced analytics models to help organizations make data-driven decisions.
- Machine Learning Engineer: Focuses on designing and implementing machine learning models.
- Data Engineer: Works on the infrastructure and tools required to collect, store, and process large datasets.
Salary Comparison: Data Mining vs. Data Science
In terms of compensation, data science roles generally offer higher salaries compared to data mining positions, largely because data science demands a broader and more advanced skill set, including expertise in statistics, programming, machine learning, and data visualization. While both fields are integral to data-driven decision-making, the comprehensive nature of data science and its application across diverse, high-impact domains such as AI, predictive analytics, and big data often justifies the increased pay. For example, the average annual salary for a Data Mining Engineer typically ranges from $70,000 to $120,000, depending on factors like job responsibilities, experience level, and industry demand. In contrast, a Data Scientist can expect to earn between $90,000 and $150,000 per year, with top-tier professionals in high-cost areas or specialized roles potentially earning even more. Data Analyst Career Path offers a strong foundation for individuals starting in the field, with career progression possibilities into data science or specialized areas. These figures are not fixed and can vary significantly based on geographic location, the size and type of the organization, specific technical expertise, and years of professional experience. Overall, as organizations increasingly seek to harness the power of data for strategic growth, both roles remain in demand, with data science continuing to offer strong career growth and attractive financial rewards.
Real-World Use Cases
- E-commerce: Companies like Amazon make extensive use of both data mining and data science to enhance customer experience and drive sales. Data mining is used to analyze user behavior, such as browsing patterns, purchase history, and product preferences, to discover meaningful trends and associations. For example, identifying items that are frequently bought together helps improve product bundling and cross-selling strategies. Data science builds on this by applying machine learning algorithms to develop personalized recommendation systems, dynamic pricing models, and inventory forecasting. These tools enable platforms to tailor product suggestions to individual users, increasing the likelihood of purchases while improving overall user satisfaction. Through the combined use of data mining for pattern recognition and data science for predictive modeling, e-commerce platforms can operate more efficiently and deliver highly personalized shopping experiences.
- Banking: The banking industry also benefits significantly from the integration of data mining and data science in its operations. Data mining techniques are commonly employed for fraud detection, where unusual transaction patterns or account behaviors are flagged for further investigation. By continuously monitoring and analyzing transactional data, banks can identify suspicious activity in real time and reduce the risk of financial fraud. Meanwhile, data science plays a critical role in predictive modeling, especially in assessing creditworthiness and predicting loan defaults. By analyzing variables such as income, credit score, repayment history, and spending behavior, data science models help financial institutions make informed lending decisions. Data Engineer Job Description highlights the role of data engineers in building and maintaining the data infrastructure that supports these processes. This reduces financial risk and enhances customer targeting for loans and other banking products. Together, these technologies strengthen security, improve customer service, and support smarter decision-making in the financial sector.
Choosing the Right Path: Data Mining or Data Science
Deciding between a career in data mining or data science ultimately comes down to your interests, strengths, and career goals. If you have a passion for exploring datasets, uncovering hidden patterns, and identifying correlations within large sets of raw data, data mining could be an ideal path, often involving statistical, mathematical, and computational techniques to discover trends that guide decision-making. On the other hand, if you’re drawn to building complex predictive models, working with machine learning algorithms, and solving multifaceted problems, data science provides a broader and more dynamic field. Engaging in Data Science Training can help you develop essential skills in programming, statistics, and real-world data applications needed to succeed in this interdisciplinary role. While data mining is more specialized and focused on extracting insights, data science offers a more expansive career path with opportunities to address diverse and complex challenges across industries, making your choice dependent on whether you prefer a narrower or more multidisciplinary approach to data analysis.




