
Last updated on 11th Aug 2025| 11625
- Introduction to Machine Learning Engineering
- Required Skills and Qualifications
- Tools and Technologies Used
- Machine Learning Lifecycle
- Data Preprocessing Techniques
- Model Development and Training
- Evaluation and Metrics
- Deployment of ML Models
- Conclusion
Introduction to Machine Learning Engineering
Machine Learning Engineering is a specialized discipline that bridges the gap between data science and software engineering. It involves designing, building, and deploying machine learning (ML) models into real-world, production-ready systems. The ultimate goal is to create reliable, Analysis, scalable, and maintainable ML-powered applications that deliver actionable insights and automation to various domains such as healthcare, finance, retail, and transportation. Unlike data scientists who often focus on research and experimentation, ML engineers operationalize models and ensure they integrate seamlessly with existing infrastructure. This field has gained enormous traction due to the surge in data availability, computational power, and advancements in algorithms. As a result, the demand for proficient ML engineers continues to grow rapidly, making it one of the most sought-after roles in the tech industry today. Machine Learning Engineering is a specialized discipline that combines software engineering principles with machine learning (ML), Machine Learning Lifecycle techniques to build scalable, reliable, and production-ready ML systems. While traditional data scientists focus on building and experimenting with models, ML engineers are responsible for deploying those models into real-world applications. An ML engineer bridges the gap between data science and software development. They handle tasks such as data preprocessing, model training, versioning, testing, Python, deployment, monitoring, and optimization. This role requires a solid understanding of machine learning algorithms, programming (especially in Python), data pipelines, Data Preprocessing Techniques, APIs, and cloud platforms. Unlike experimental ML work, machine learning engineering emphasizes reproducibility, scalability, automation, and system performance. Engineers often work with tools like TensorFlow, PyTorch, Docker, Kubernetes, and MLOps frameworks to streamline the ML lifecycle. As businesses increasingly adopt AI-driven solutions, the role of ML engineers has become critical in transforming proof-of-concept models into stable, maintainable products that deliver real value at scale.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Required Skills and Qualifications
To excel as a Machine Learning Engineer, one needs a multidisciplinary skill set combining mathematics, programming, software engineering, and domain-specific knowledge. Below are the primary skills and qualifications expected:
Technical Skills
- Programming Proficiency: Expertise in Python is essential due to its rich ecosystem of ML libraries like TensorFlow, PyTorch, and Scikit-learn. Knowledge of Java, Scala, or C++ can also be beneficial for production-level performance.
- Mathematics and Statistics: A deep understanding of linear algebra, calculus, probability, and statistics is crucial. These are the building blocks of most ML algorithms.
- Machine Learning Fundamentals: Knowledge of various ML paradigms including supervised learning (e.g., regression, classification), unsupervised learning (e.g., clustering, dimensionality reduction), and reinforcement learning.
- Data Structures and Algorithms: A strong grasp of algorithms, complexity analysis, and data structures to write optimized code.
- Version Control Systems: Mastery of tools like Git and platforms like GitHub or GitLab.
- Testing and Debugging: Writing unit and integration tests to ensure the reliability of ML pipelines.
- Continuous Integration/Continuous Deployment (CI/CD): Automating workflows for consistent code deployment.
- Data Manipulation: Using tools like Pandas, NumPy, or SQL to handle large and complex datasets.
- Big Data Frameworks: Familiarity with Apache Spark, Hadoop, and Kafka for distributed data processing.
- Cloud Computing: Experience with AWS, Google Cloud Platform (GCP), or Microsoft Azure for scalable infrastructure.
- Communication: The ability to convey complex technical ideas to non-technical stakeholders.
- Teamwork and Collaboration: Working effectively with cross-functional teams.
Software Engineering Practices
Data Handling and Analysis
Additional Skills
Tools and Technologies Used
The ML engineering toolkit is vast and diverse, encompassing tools for every phase of the ML lifecycle:
- Python: Most widely used due to its simplicity and vast library support.
- R: Popular for statistical analysis and research.
- Java/Scala: Often used in big data applications.
- TensorFlow and PyTorch: Deep learning libraries for model building and training.
- Scikit-learn: For traditional ML algorithms.
- XGBoost and LightGBM: For gradient boosting models.
- Keras: A high-level API for building deep learning models on top of TensorFlow.
- Pandas and NumPy: Data manipulation and numerical computing.
- SQL and NoSQL Databases: For structured and semi-structured data.
- Apache Spark: Large-scale data processing.
- Docker and Kubernetes: For containerization and orchestration.
- Flask, FastAPI: Lightweight APIs for serving models.
- MLflow, Prometheus, Grafana: Tools for model monitoring and lifecycle management.
- Problem Definition: Clearly articulating the business objective and expected outcomes.
- Data Collection: Acquiring data from internal databases, APIs, or external datasets.
- Data Exploration and Preprocessing: Understanding data distribution and applying cleaning techniques.
- Feature Engineering: Creating meaningful features to improve model performance.
- Model Selection: Choosing the right algorithm based on the problem type and data characteristics.
- Model Training: Training the model using suitable loss functions and optimization techniques.
- Model Evaluation: Assessing performance using appropriate metrics.
- Model Deployment: Integrating the model into production environments.
- Monitoring and Maintenance: Ensuring sustained performance and addressing data/model drift.
- Linear Models: Logistic regression, linear regression.
- Tree-Based Models: Decision Trees, Random Forests, Gradient Boosting.
- Neural Networks: CNNs, RNNs, Transformers for complex tasks like vision and NLP.
- Hyperparameter Tuning: Using techniques like grid search, random search, and Bayesian optimization.
- Regularization: L1, L2 penalties to prevent overfitting.
- Early Stopping: Halt training when performance degrades on validation data.
- Batch Training vs. Online Learning: Depending on data availability.
- Accuracy: Overall correctness.
- Precision, Recall, F1-Score: Balance between false positives and false negatives.
- ROC-AUC: Area under the receiver operating characteristic curve.
- Mean Absolute Error (MAE): Average magnitude of errors.
- Mean Squared Error (MSE): Emphasizes larger errors.
- R-squared: Proportion of variance explained by the model.
- Confusion Matrix: Detailed breakdown of classification results.
- SHAP and LIME: Explainable AI tools for model transparency.
- Pickle, Joblib, ONNX: Formats for saving and reloading trained models.
- REST APIs: Using Flask, FastAPI to create endpoints.
- gRPC: For high-performance, low-latency services.
- Docker: To package models with dependencies.
- Kubernetes: For scaling and managing containers.
- CI/CD Pipelines: Automating testing and deployment.
- A/B Testing and Canary Releases: Gradual deployment and performance tracking.
- Model Performance: Track accuracy, latency, and error rates.
- Data Drift: Detecting changes in data distribution.
- Logging and Alerts: For debugging and maintenance.
Programming Languages
Libraries and Frameworks
Data Handling Tools
Deployment and Monitoring
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Machine Learning Lifecycle
Machine Learning lifecycle to ensure the successful deployment of models:
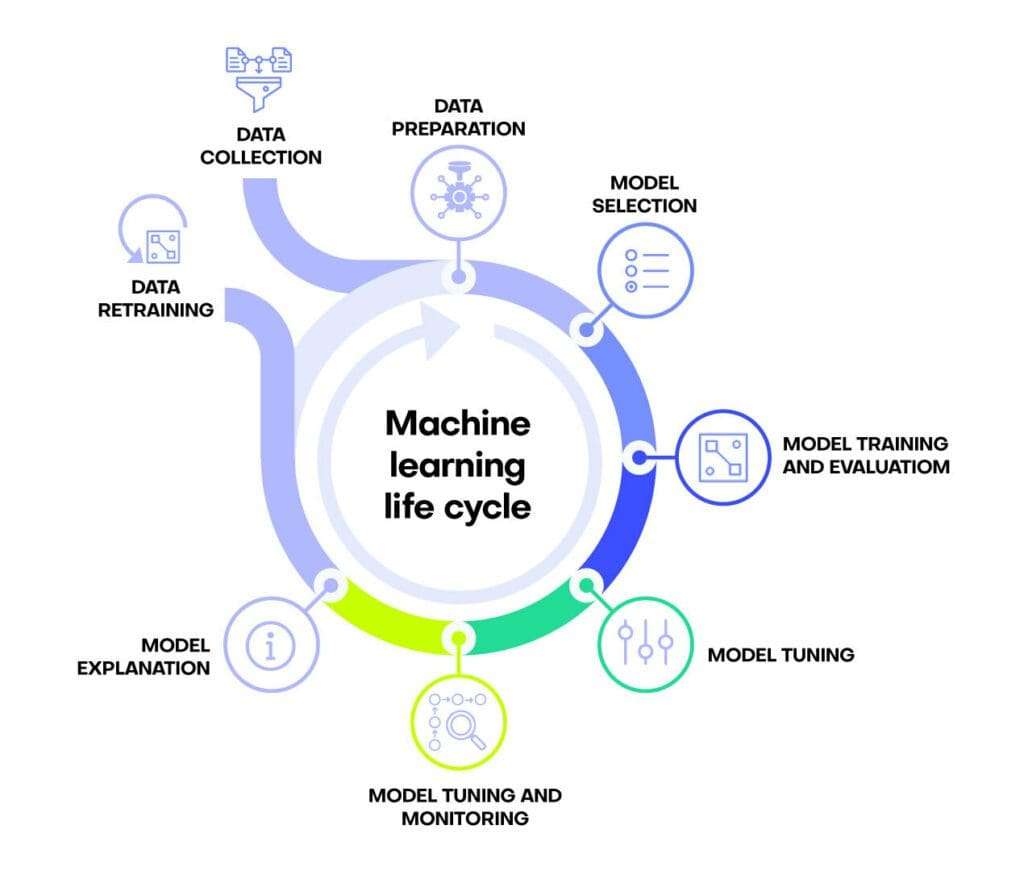
Each of these stages often involves cross-functional collaboration and iterative refinement.

Data Preprocessing Techniques
Data preprocessing is a critical step in the machine learning pipeline, as the quality and structure of data directly impact model performance. It involves preparing raw data into a clean and usable format before feeding it into a model. Common preprocessing techniques include data cleaning, where missing values are handled and outliers are removed; data transformation, which may involve normalization or standardization to bring features onto a similar scale; and encoding categorical variables using techniques like one-hot encoding or label encoding. Feature selection and extraction help identify the most relevant attributes for the model, reducing noise and improving efficiency. Additionally, data splitting divides the dataset into training, validation, and test sets to evaluate model performance fairly. In some cases, data augmentation is used, especially in domains like image or text processing, to artificially expand the dataset. Effective data preprocessing not only improves accuracy but also ensures the model generalizes well to new, unseen data.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Model Development and Training
The core task of an ML engineer is to develop models that are both accurate and generalizable. Key considerations:
Model Selection
Training Strategies
Evaluation and Metrics
Model evaluation is not one-size-fits-all and varies depending on the problem type:
Classification
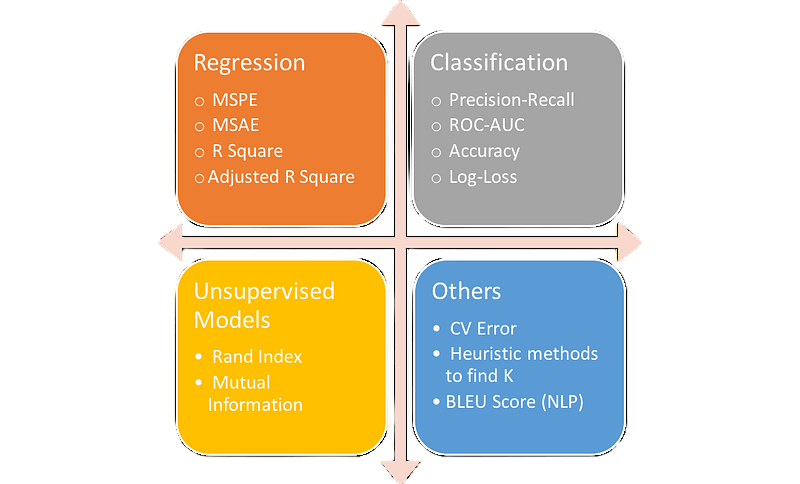
Regression
Model Interpretability
Deployment of ML Models
Getting models into production requires careful planning and execution:
Model Serialization
Model Serving
Containerization and Orchestration
Continuous Delivery
Monitoring
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Conclusion
Machine Learning Engineering plays a pivotal role in transforming theoretical models into real-world solutions. By combining deep knowledge of machine learning algorithms , Machine Learning Lifecycle with strong software engineering skills, Python, TensorFlow ,ML engineers ensure that models are scalable, reliable, and ready for production. As AI continues to shape industries, data analysis the demand for skilled ML engineers will only grow. Mastering this field not only involves understanding Data Preprocessing Techniques and models but also building robust systems that deliver consistent performance in dynamic environments.



