
Last updated on 26th Apr 2025| 10296
- What is a Vector Database?
- Role of Vector Databases in AI
- Indexing Methods in Vector Databases
- Popular Vector Databases
- Using Vector Databases for Image Search
- Text-Based Search with Vector Databases
- Scaling and Optimizing Vector Databases
- Future of Vector Databases
What is a Vector Database?
A Vector Database is a specialized system designed to store and retrieve high-dimensional vector embeddings. Unlike traditional databases that manage structured data in rows and columns, vector databases handle numerical representations of unstructured data such as text, images, audio, and video. These embeddings are generated by AI models and capture the semantic meaning of the data, enabling advanced search capabilities based on similarity rather than exact matches. This makes vector databases essential for AI-powered applications, particularly in semantic search, where they can quickly identify related content even when specific words or phrases differ an important topic explored in Data Science Training for improving search and recommendation systems. For example, a search for “smartphone” might return results including “iPhone” or “Android device” due to the semantic similarity captured in the embeddings. Designed for speed and scalability, vector databases excel in handling massive datasets and complex queries in real time. They are widely used in recommendation systems, anomaly detection, natural language processing, and multimedia search. As AI continues to evolve, vector databases are becoming a core infrastructure for modern data applications, bridging the gap between unstructured data and intelligent insights.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Role of Vector Databases in AI
Vector databases play a crucial role in modern AI applications by enabling fast, accurate, and scalable similarity searches. Unlike traditional databases that rely on SQL queries to filter and match structured data, vector databases are designed to identify semantic relationships within unstructured data something conventional systems struggle with. They achieve this by storing vector embeddings, which are high-dimensional numerical representations of data generated by AI models an approach closely related to How to Build and Annotate an NLP Corpus Easily, as both involve working with structured data representations for improved model performance. These embeddings allow for nearest-neighbor searches, enabling the system to quickly retrieve results that are contextually and semantically relevant. In Natural Language Processing (NLP), vector databases store and query text embeddings, powering semantic search engines that understand the meaning behind words and phrases, not just exact matches.
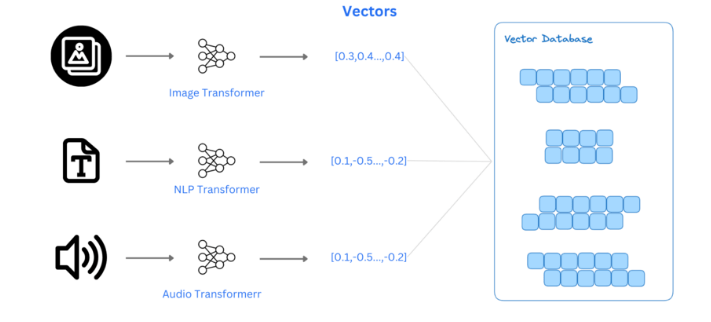
In computer vision, they store image vectors, supporting fast and efficient similarity-based image retrieval. Recommendation systems leverage vector databases to identify and suggest similar products, services, or content, enhancing user experience through personalization. By enabling real-time, context-aware data retrieval across diverse media types, vector databases are a foundational technology for advancing AI-driven search, discovery, and personalization.
Indexing Methods in Vector Databases
- Flat (Brute-Force) Index: Performs an exhaustive comparison between query and all stored vectors. It’s accurate but computationally expensive, best for small datasets.
- IVF (Inverted File Index): Divides vectors into clusters and searches within the most relevant clusters. This reduces computation while maintaining good accuracy.
- HNSW (Hierarchical Navigable Small World): Builds a graph-based index for efficient nearest-neighbor search. It offers a great balance of speed and accuracy, especially for high-dimensional data.
- PQ (Product Quantization): Compresses vectors into smaller representations, reducing memory usage and speeding up search an essential technique in Data Cleaning in Data Science for efficient data handling.
- Annoy (Approximate Nearest Neighbors Oh Yeah): Uses random projection trees for fast approximate search. Good for read-heavy applications and large datasets.
- Faiss Indexes: Facebook’s Faiss library supports multiple indexing strategies (Flat, IVF, PQ, HNSW), optimized for performance and GPU acceleration.
- ScaNN (Scalable Nearest Neighbors): Developed by Google, it combines tree structures and quantization for fast, accurate approximate search.
- Auto-tuned Indexes: Some systems dynamically select or adjust indexing methods based on data characteristics and query patterns for optimal performance.
- FAISS (Facebook AI Similarity Search): Developed by Meta, FAISS is an open-source library for fast similarity search. It uses HNSW and IVF algorithms to index and retrieve high-dimensional vectors efficiently. FAISS is popular for large-scale batch processing and NLP applications.
- Pinecone: A fully managed vector database service that offers real-time ANN search with low latency. Pinecone handles auto-scaling and optimization, making it ideal for production environments similar to how an AI Checker Tool helps streamline and optimize AI workflows for better performance.
- Weaviate: An open-source vector search engine with hybrid capabilities that allows vector- and keyword-based search. It offers built-in support for Hugging Face models and OpenAI embeddings, making it ideal for multimodal search (text and image).
- Milvus: A scalable, open-source vector database designed for high-performance similarity search. Milvus supports billions of vectors and integrates with multiple machine learning frameworks, making it ideal for real-time AI applications.
- Qdrant: A high-performance, open-source vector database built for neural search. Qdrant supports payload filtering, geo-search, and real-time updates, making it suitable for recommendation engines and semantic search use cases.
- Data Partitioning: Divide large datasets into smaller, manageable chunks to distribute across multiple nodes. This improves access speed and reduces bottlenecks.
- Sharding: Implement horizontal sharding, which involves splitting data across various servers or clusters, ensuring scalability and redundancy.
- Indexing: Use advanced indexing techniques like HNSW (Hierarchical Navigable Small World) graphs or IVF (Inverted File) to speed up similarity search queries.
- Efficient Storage: Compress vector data to reduce memory and disk usage while maintaining data integrity. Techniques like quantization help optimize space.
- Load Balancing: Distribute queries across multiple servers to enhance performance and scalability, similar to optimizing the Impact of Loss Functions on Deep Learning Performance.
- Caching: Implement caching mechanisms for frequently queried vectors to minimize database access times and reduce system load.
- Concurrency Control: Allow concurrent data operations without conflicts by using optimized locking mechanisms or atomic operations.
- Monitoring & Tuning: Continuously monitor system performance, adjust configurations, and fine-tune indexing parameters to maintain optimal performance.
Gain Interest in Obtaining Your Data Science Certificate? View The Data Science Course Training Offered By ACTE Right Now!
Popular Vector Databases
Several vector databases are widely used in AI and machine learning applications due to their efficiency and scalability.


Using Vector Databases for Image Search
Vector databases play a critical role in image retrieval applications by enabling fast and accurate searches based on visual similarity. Instead of matching exact metadata or filenames, these systems rely on vector similarity search, comparing images through their embeddings and numerical representations that capture the visual features of an image. The process starts with image encoding, where pre-trained vision models like CLIP or ResNet convert input images into high-dimensional embeddings a technique often utilized in AI Image Generator Tools to transform visual data for further processing and generation. These embeddings are then stored in a vector database. When a user submits a query image, it is encoded in the same way, and the database performs a nearest-neighbor search to find embeddings with the smallest distance from the query. This results in a set of images that are visually similar, even if they don’t match in terms of text or tags. In real-world use cases like e-commerce, this technology allows users to upload a photo of an item such as a pair of shoes or furniture and receive visually similar product suggestions, enhancing the shopping experience with intuitive and personalized search capabilities.
Looking to Master Data Science? Discover the Data Science Masters Course Available at ACTE Now!
Text-Based Search with Vector Databases
Text search with vector databases enables semantic search, allowing systems to understand and match the meaning of a user’s query rather than relying solely on keyword-based matching, as is the case with traditional SQL searches. This results in more accurate and context-aware retrieval, especially when users phrase queries in natural language or use different words with similar meanings. The process begins by generating text embeddings using advanced language models such as OpenAI embeddings, Sentence-BERT (SBERT), or Cohere models techniques that are often covered in Data Science Training to enhance natural language processing (NLP) tasks. These embeddings are high-dimensional vectors that capture the semantic relationships between words, sentences, or entire documents. Once generated, these vectors are stored in a vector database. When a user submits a query, the system encodes the input text into an embedding and performs a similarity search against the stored vectors, retrieving results that are contextually relevant. This allows users to find information even when their queries don’t contain the exact keywords. This technique powers a wide range of applications, including chatbots, document search engines, and knowledge management systems, making information retrieval smarter, faster, and more intuitive.
Scaling and Optimizing Vector Databases
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
Future of Vector Databases
The future of vector databases is poised to revolutionize data retrieval by integrating multimodal search capabilities. By combining text, image, and audio embeddings, vector databases will offer more comprehensive and accurate search results, enabling systems to understand and retrieve information across multiple data types seamlessly. This advancement will be particularly beneficial in applications such as content-based recommendation systems, where users interact with various forms of media. Real-time streaming vector search is another area gaining momentum. It allows for instant updates and low-latency searches, ensuring that new data is reflected immediately without affecting system performance an important concept covered in Data Science Training to optimize real-time data processing and analysis. This is especially valuable in dynamic environments where data constantly evolves, such as live content feeds, social media platforms, or financial market analytics. As AI applications continue to expand, the demand for vector databases will grow, especially for managing massive datasets while maintaining millisecond-level query response times. These capabilities will drive innovations in hyper-personalized recommendations, semantic search engines, and AI-powered analytics, enhancing user experience and decision-making processes. In this way, vector databases will become a critical component of the AI ecosystem, enabling more powerful and efficient systems.




