
Last updated on 17th Jun 2025| 10079
- Introduction to Python for Data Science
- Setting Up Python Environment
- Jupyter Notebooks for Data Science
- Python Basics: Syntax, Variables, Loops
- NumPy for Numerical Operations
- Pandas for Data Manipulation
- Data Visualization with Matplotlib and Seaborn
- Conclusion
Introduction to Python for Data Science
Python has rapidly established itself as one of the most popular programming languages in the field of data science due to its simplicity, readability, and extensive ecosystem. Its clear and intuitive syntax lowers the learning curve, making it accessible to beginners while remaining powerful enough for experienced data scientists. Python’s vast collection of libraries and frameworks is a major factor behind its widespread adoption. Tools like Pandas and NumPy simplify data preprocessing and manipulation, Matplotlib and Seaborn support rich data visualization, and powerful libraries such as Scikit-learn, TensorFlow, and PyTorch enable the development of sophisticated machine learning and deep learning models. Python’s flexibility allows data scientists to work seamlessly across different stages of the data science workflow, from data collection and cleaning to exploration, modeling, and deployment, making it a key focus in Data Science Training. It integrates well with various data sources, including databases, APIs, and big data platforms, enabling efficient data ingestion and management. Automation of repetitive tasks is another advantage, freeing data professionals to focus on deeper analysis and model development. Moreover, Python supports collaboration and reproducibility through tools like Jupyter Notebooks, which combine code, visualizations, and documentation in one place. Its ability to handle complex mathematical computations and statistical analyses helps uncover hidden patterns and generate actionable insights from large datasets. As the demand for data-driven decision-making grows, Python continues to be an indispensable tool for data scientists, powering innovations in industries ranging from finance and healthcare to marketing and beyond.
Are You Interested in Learning More About Data Science? Sign Up For Our Data Science Course Training Today!
Setting Up Python Environment
To begin working with Python for data science, it is highly recommended to install the Anaconda distribution. Anaconda is a free, open-source platform that simplifies package management and deployment for both Python and R languages. It comes pre-installed with many essential data science libraries such as NumPy for numerical computations, Pandas for data manipulation, and Matplotlib for data visualization, along with powerful tools like Jupyter Notebook and Spyder. This all-in-one setup helps beginners avoid the complexities of manually installing and configuring individual packages, allowing them to focus on learning and experimentation, particularly with Top Python Libraries For Data Science. To get started, download Anaconda from the official website, ensuring you select the version compatible with your operating system whether Windows, macOS, or Linux. The installation process is straightforward, guided by clear instructions that make setup accessible even for those new to programming. After installation, you can launch Anaconda Navigator, a user-friendly interface that provides access to Jupyter Notebooks, Spyder, and other useful tools that streamline coding, testing, and debugging. Once your Anaconda environment is ready, you can begin writing and executing Python code immediately.
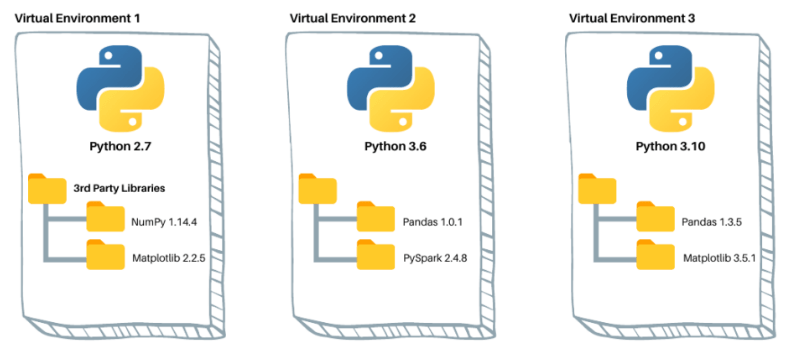
Anaconda also allows you to manage packages efficiently and create isolated virtual environments. These virtual environments are crucial for handling different projects, preventing package version conflicts, and maintaining a clean development setup. By leveraging Anaconda’s comprehensive toolkit, aspiring data scientists can build, test, and deploy projects with greater ease and confidence.
Jupyter Notebooks for Data Science
- What is Jupyter Notebook: Jupyter Notebook is an open-source web-based tool that allows users to create and share documents containing live code, visualizations, and narrative text. It is widely used in data science for exploration, analysis, and reporting.
- Easy Installation via Anaconda: Jupyter is included in the Anaconda distribution, which is a preferred setup for data scientists. Installing Anaconda gives immediate access to Jupyter along with essential packages like NumPy, Pandas, and Matplotlib.
- Interactive Coding Environment: Jupyter supports cell-based execution, letting users run code one block at a time. This interactive environment is ideal for testing small code snippets, debugging, and iterating quickly through data workflows, which is especially useful when learning What is Logistic Regression.
- Support for Multiple Languages: While Jupyter primarily supports Python, it also works with other languages like R, Julia, and Scala through the use of language-specific kernels. This flexibility makes it a powerful tool for multidisciplinary projects.
- Rich Text and Visualizations: Users can combine code with Markdown for annotations, headings, and explanations. Charts and graphs from libraries like Matplotlib, Seaborn, and Plotly render inline, making data storytelling seamless.
- Ideal for Data Science Workflow: Jupyter is perfect for the full data science cycle data cleaning, exploration, visualization, modeling, and presentation. It allows keeping code, output, and interpretation in one place.
- Export and Share Easily: Notebooks can be exported to formats like HTML or PDF, making it easy to share work with colleagues or present results to stakeholders. They can also be shared online via GitHub or nbviewer.
- Simple and Clean Syntax: Python uses indentation instead of braces to define code blocks. This makes the language highly readable and easy to understand, especially for beginners transitioning into programming.
- Printing Output: Displaying messages or outputs is done using a built-in print function. It’s commonly used to test code, debug, or show final results during script execution.
- Dynamic Variable Assignment: In Python, you don’t need to declare the type of a variable. The interpreter automatically assigns the appropriate type based on the value, making variable handling quick and flexible, which is a fundamental concept taught in Data Science Training.
- Common Data Types: Python supports essential data types like integers, floats, strings, and booleans. These are used to represent numeric values, text, and logical conditions, forming the foundation of most programs.
- Decision Making with Conditionals: Using conditional statements like if, elif, and else, Python lets you control the flow of your program based on specific conditions. This enables more dynamic and responsive code behavior.
- Looping and Repetition: Python offers for and while loops to repeat actions multiple times. Loops are useful for iterating over data collections, automating tasks, and handling bulk operations efficiently.
- Importance of Indentation: Indentation in Python is not just for readability it defines the structure of your code. Incorrect indentation can cause errors, so consistent formatting is essential for writing clean and functional programs.
- Introduction to Pandas: Pandas is a powerful open-source Python library used for data manipulation and analysis. It offers high-performance, easy-to-use data structures like Series and DataFrame that are essential for handling structured data.
- Working with DataFrames: The core component of Pandas is the DataFrame, a 2-dimensional labeled data structure similar to a spreadsheet or SQL table. DataFrames make it easy to organize, view, and manipulate tabular data efficiently.
- Reading and Writing Data: Pandas supports reading from and writing to various file formats, including CSV, Excel, JSON, and SQL databases, complementing concepts like Python Generators for efficient data processing. This allows users to import real-world datasets easily and export processed data for further use.
- Data Selection and Filtering: You can access specific rows and columns in a DataFrame using labels or index positions. Pandas also provides powerful filtering capabilities to extract data that meets specific conditions, which is essential for focused analysis.
- Handling Missing Data: Real-world data often contains missing or null values. Pandas provides tools to detect, fill, or drop missing values, helping maintain the integrity and quality of the dataset during analysis.
- Data Aggregation and Grouping: With methods like groupby(), Pandas allows users to group data by one or more columns and apply summary functions such as mean, sum, or count. This is useful for gaining insights from large datasets.
- Data Transformation: Pandas makes it simple to clean and transform data through operations like renaming columns, changing data types, merging datasets, and applying functions to rows or columns for customized processing.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Course Training To Gain Insights From Our Experts!
Python Basics: Syntax, Variables, Loops

NumPy for Numerical Operations
NumPy is a foundational library in Python widely used for numerical operations, making it an essential tool for data science, scientific computing, and engineering applications. It provides support for large, multi-dimensional arrays and matrices, along with a vast collection of mathematical functions to operate efficiently on these data structures. Unlike Python’s built-in lists, NumPy arrays offer significant performance advantages due to their fixed data types and optimized memory usage, enabling faster computations that are crucial for processing large datasets. At its core, NumPy introduces the ndarray, a powerful n-dimensional array object that can store elements of the same data type. This uniformity allows NumPy to perform vectorized operations, which apply functions simultaneously to entire arrays without the need for explicit loops, highlighting key differences in Python vs R vs SAS. As a result, code written with NumPy is not only more concise but also runs much faster compared to traditional Python loops. NumPy also includes an extensive suite of mathematical, statistical, and linear algebra functions. These capabilities support essential tasks such as matrix multiplication, Fourier transforms, random number generation, and more. Additionally, NumPy integrates seamlessly with other scientific libraries like Pandas, SciPy, and Matplotlib, forming the backbone of the Python scientific computing ecosystem. For anyone working with numerical data, mastering NumPy is critical. It simplifies complex computations, reduces development time, and enhances code readability. Whether performing basic array manipulations or implementing sophisticated numerical algorithms, NumPy provides the tools needed to handle numerical data efficiently and accurately, making it a cornerstone of modern data analysis and machine learning workflows.
Looking to Master Data Science? Discover the Data Science Masters Course Available at ACTE Now!
Pandas for Data Manipulation
Data Visualization with Matplotlib and Seaborn
Data visualization is a crucial step in data analysis, helping to interpret complex datasets and communicate insights effectively. In Python, Matplotlib and Seaborn are two of the most popular libraries for creating visual representations of data. Matplotlib is a versatile and powerful plotting library that offers fine-grained control over every aspect of a plot. It supports a wide range of chart types including line plots, bar charts, histograms, scatter plots, and more. Matplotlib’s flexibility allows users to customize plots extensively, from colors and labels to axes and grid lines, making it suitable for both simple and highly complex visualizations. Seaborn builds on top of Matplotlib, providing a higher-level interface designed to create attractive and informative statistical graphics with less code, illustrating Why Data Science Matters & How It Powers Business Value. It simplifies the creation of complex plots such as heatmaps, violin plots, pair plots, and regression plots, and integrates well with Pandas data structures. Seaborn comes with built-in themes and color palettes that improve the aesthetics of visualizations by default, making it a favorite among data scientists for exploratory data analysis. Together, these libraries complement each other: Matplotlib offers detailed customization and control, while Seaborn focuses on statistical plotting and ease of use. Both support integration with Jupyter Notebooks, enabling interactive visualization in a research or teaching environment. Mastering Matplotlib and Seaborn empowers analysts and developers to transform raw data into clear, compelling stories, facilitating better decision-making and more effective communication of results.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions & Answer to Boost Your Preparation!
Natural Language Processing Projects
Python has emerged as a powerful, flexible, and easy-to-learn programming language that has become the preferred choice for data scientists worldwide. Its simplicity and readability make it accessible to beginners, while its extensive capabilities satisfy the needs of experienced professionals. Python’s vast ecosystem of libraries and tools supports every stage of the data science workflow, from data ingestion and cleaning to exploration, modeling, and deployment. Libraries such as Pandas and NumPy enable efficient data manipulation and numerical operations, while visualization tools like Matplotlib and Seaborn help transform raw data into meaningful graphics. For machine learning and deep learning tasks, frameworks like Scikit-learn, TensorFlow, and PyTorch offer robust, scalable solutions, which are key components of Data Science Training. One of Python’s greatest strengths is its versatility across various industries, including finance, healthcare, marketing, and technology, making it an essential skill for many data-driven roles. By mastering Python, aspiring data scientists can unlock numerous career opportunities and contribute to building impactful solutions that improve decision-making and business outcomes. Python also integrates well with other technologies and platforms, enabling seamless data workflows and automation. Whether you are developing predictive models to forecast trends or performing exploratory data analysis to uncover hidden patterns, Python provides a solid foundation to tackle complex problems efficiently. Its supportive community, comprehensive documentation, and constant evolution ensure that Python remains at the forefront of innovation in data science, empowering professionals to deliver insights that drive success in today’s data-centric world.




