
Last updated on 09th Dec 2021| 2559
Ridge Regression, which penalizes sum of squared coefficients (L2 penalty). Lasso Regression, which penalizes the sum of absolute values of the coefficients (L1 penalty).
- Introduction of Ridge and lasso regression
- Tools of Ridge and lasso regression
- Breaking Opportunities and Impact of Ridge and lasso regression
- Features / Characteristics
- Types/methods of Ridge and lasso regression
- Synatx of Ridge and lasso regression
- How it works
- Why it is needed and important?
- Trends of Ridge and lasso regression
- Benefits of Ridge and lasso regression
- Conclusion
- Ridge Descent:
- Perform L2 measurements,i.e. add a fine up to the sq. of the scale of the coefficients
- Purpose of reduction = LS Obj + α * (square range of coefficients)
- Lasso Regression:
- Perform L1 measure, i.e. add a penalty up to the overall quantity of coefficients
- Purpose of reduction = LS Obj + α * (total range of coefficients)
Introduction to Ridge and lasso regression
When we point out Regression, we regularly point out Linear and provision Regression. But, that’s not the tip. Linearity and order are the foremost fashionable members of the retreat family. Last week, I saw a recorded speech at the NYC Knowledge Science Academy from Owen Zhang, Chief Product Officer at DataRobot. He said, ‘if you employ reciprocity, you ought to be terribly special!’. I hope you discover what your personal body is pertaining to. I understood it okay and determined to explore the acquainted techniques intimately. In this article, I actually have delineated the complicated science behind ‘Ridge Regression’ and ‘Lasso Regression’ that are at the foremost common ways used in knowledge science, sadly still not employed by several.
The whole read of retreat remains identical. It means the model coefficients are determined to build the distinction. I strongly suggest that you simply bear a natural event many times before reading this. you’ll get assistance on this subject or the other item you decide on. Ridge and Lasso regression are powerful techniques that typically want to produce straightforward models wherever there are a ‘large’ range of options. Here the word ‘big’ will mean any of 2 things:
It is massive enough to boost the model’s tendency to overcrowding (a low of ten variables will cause overcrowding) Big enough to cause countless challenges. With fashionable systems, this case could arise if there are millions or lots of factors While Ridge and Lasso could appear to serve identical goals, the natural structures and cases of sensible use vary greatly. If you’ve detected them before, you ought to understand that they work by weighing the magnitude of the coefficients of the options and minimising the error between certain and actual recognition. These are referred to as ‘normal’ techniques. the most distinction is however they atone for the coefficients:
- Ridge regression shrinks the coefficients and it helps to scale back the model complexness and multicollinearity.
- Lasso regression not solely facilitates in reducing over-fitting however it will help U.S. in feature choice both strategies confirm coefficients by finding the primary purpose wherever the elliptical contours hit the region of constraints. The diamond (Lasso) has corners on the axes, in contrast to the disk, and whenever the elliptical region hits such a purpose, one in all the options fully vanishes!
- Cost performance of Ridge and Lasso regression and importance of regularisation term.
- Went through some examples exploiting straightforward data-sets to know regression toward the mean as a limiting case for each Lasso and Ridge regression.
- Understood why Lasso regression will result in feature choice whereas Ridge will solely shrink coefficients on the brink of zero.
Characteristics of Ridge and lasso regression
- Solver to use within the procedure routines:
- ‘auto’ chooses the problem solver mechanically supporting the kind of information.
- ‘svd’ uses a Singular price Decomposition of X to work out the Ridge coefficients. additional stable for singular matrices than ‘cholesky’.
- ‘cholesky’ uses the quality scipy.linalg.solve to get a closed-form resolution.
- ‘sparse_cg’ uses the conjugate gradient problem solver as found in scipy.sparse.linalg.cg. As an associate degree reiterative algorithmic rule, this problem solver is additional acceptable than ‘cholesky’ for large-scale information (possibility to line tol and max_iter).
- ‘lsqr’ uses the dedicated regularised least-squares routine scipy.sparse.linalg.lsqr. It’s the quickest associate degreed uses an reiterative procedure.
- ‘sag’ uses a random Average Gradient descent, and ‘saga’ uses its improved, unbiased version named heroic tale. Each way additionally uses an associate degree reiterative procedure, and is usually quicker than alternative solvers once each n_samples and n_features are giant. Note that ‘sag’ and ‘saga’ quick convergence is barely warranted on options with around a similar scale. you’ll preprocess the info with a pulse counter from sklearn.preprocessing.
- ‘lbfgs’ uses L-BFGS-B algorithmic rule enforced in scipy.optimize.minimize. It will be used only if positive is True.
- All last six solvers support each dense and thin information. However, only ‘sag’, ‘sparse_cg’, and ‘lbfgs’ support thin input once fit_intercept is True
Parameters of ridge
alphaform (n_targets,)}, default=1.0
Regularisation strength; should be a positive float. Regularisation improves the learning of the matter and reduces the variance of the estimates. Larger values specify stronger regularisation. Alpha corresponds to one / (2C) in alternative linear models like LogisticRegression or LinearSVC. If an associate degree array is passed, penalties are assumed to be specific to the targets. therefore they have to correspond in range.
fit_interceptbool, default=True
Whether to suit the intercept for this model. If set to false, no intercept are utilised in calculations (i.e. X and y are expected to be centred).
normalizebool, default=False
This parameter is neglected once fit_intercept is ready to False. If True, the regressors X are normalised before regression by subtracting the mean and dividing by the l2-norm. If you would like to standardise, please use StandardScaler before career work on associate degree calculator with normalise=False.
copy_Xbool, default=True
If True, X are copied; else, it’s going to be overwritten.
max_iterint, default=None
Maximum range of iterations for conjugate gradient problem solver. For ‘sparse_cg’ and ‘lsqr’ solvers, the default price is decided by scipy.sparse.linalg. For ‘sag’ problem solvers, the default price is a thousand. For ‘lbfgs’ problem solvers, the default price is 15000.to float, default=1e-3
Precision of the answer.
solver, default=’auto’
Regularisation techniques
There square measure principally 2 forms of regularisation techniques, specifically Ridge Regression and Lasso Regression. The manner they assign a penalty to β (coefficients) is what differentiates them from one another.
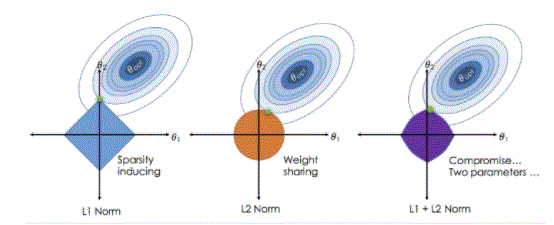
Ridge Regression (L2 Regularisation)
This technique performs L2 regularisation. The most algorithmic program behind this is often to change the RSS by adding the penalty that admires the sq. of the magnitude of coefficients. However, it’s thought of to be a way used once the data suffers from multiple regression (independent variables are extremely correlated). In multiple regression, albeit the tiniest quantity squares estimates (OLS) are unbiased, their variances are giant that deviates the ascertained worth far from truth value. By adding a degree of bias to the regression estimates, ridge regression reduces the standard errors. It tends to resolve the multiple regression drawback through shrinkage parameter λ.
Lasso Regression (L1 Regularisation)
This regularisation technique performs L1 regularisation. In contrast to Ridge Regression, it modifies the RSS by adding the penalty (shrinkage quantity) resembling the add of absolutely the price of coefficients. Looking at the equation below, we are able to observe that just like Ridge Regression, Lasso (Least Absolute Shrinkage and Choice Operator) conjointly penalises absolutely the size of the regression coefficients. in addition to the present, it’s quite capable of reducing the variability and raising the accuracy of statistical regression models.
Limitation of Lasso Regression:
If the quantity of predictors (p) is larger than the quantity of observations (n), Lasso can decide at most n predictors as non-zero, although all predictors are unit relevant (or are also employed in the check set). In such cases, Lasso typically must struggle with such varieties of information. If there are unit 2 or additional extremely linear variables, then LASSO regression chooses one in every of them every {which way} which isn’t smart for the interpretation of knowledge. Lasso regression differs from ridge regression in that it uses absolute values among the penalty performed, instead of that of squares. This ends up in penalising (or equivalently constrictive the addition of absolutely the values of the estimates) values that causes a number of the parameter estimates to show out specifically zero. The additional penalty is applied, the additional the estimates get shrunken towards temperature. This helps to variable choice out of given vary of n variables.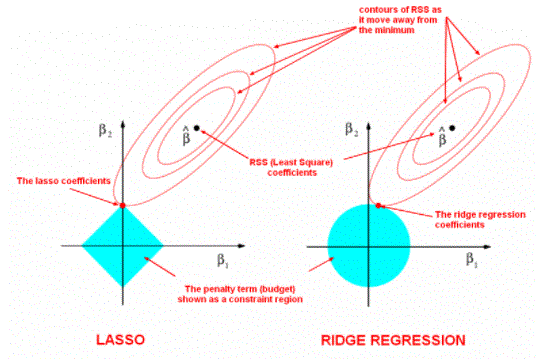
- Housing Data Set (housing.csv)
- Housing Description (housing.names)
- You do not have to be forced to move a database; we often stop live to automatically transmit it as part of our processed models.
- # upload and summarise housing database
- from pandas import read_csv
- from matplotlib import pyplot
- # upload the database
- url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv’
- dataframe = read_csv (url, header = None)
- # shorten type
- print (dataframe.shape)
- # summarise the first few lines
- print (dataframe.head ())
- # frame model
- model = Ridge (alpha = 1.0)
- We can test the Ridge Regression model on the housing database continuously to confirm 10 times and report a common mean absolute (MAE) error on the database.
- For example it examines the Ridge Regression system in the housing database and reports a standard MAE for all 3 duplicates of 10 times the opposite assurance.
- Your specific outcomes may vary depending on the random nature of the teaching law. consider running an event over and over again.
- In this case, we tend to stand still and be prepared to see that the model has achieved MAE in terms of threefold.382.
- Means MAE: three.382 (0.519)
- We may try to use Ridge Regression as our final model and build predictions on new information.
- This can be achieved by modelling all available information and active prediction () function, across the entire information line.
Syntax with examples
An example of Ridge retreat
At this stage, we often stop and go live to show how to apply the Ridge Regression rule.
First, let’s introduce a set of custom retrieval data. we tend to stand live to use the housing database.
The housing database may be a typical machine learning database consisting of 506 lines of information with thirteen input variations and target numerical variations.
Using a 10-fold double-factor-positive cross-check check harness, the unit of total sensitivity is ready to make a total error (MAE) for a reference of 0.5 adozen.6. The most efficient model area unit is ready to perform MAE in the same test instrument with reference to one.9. This provides the performance parameters for this database.
The database includes predicting the value of the home given the details of the housing community within the yankee town of Boston.

Learn Advanced IronPython Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsThe example below is downloaded and much more with a lot of databases like Pandas DataFrame and summarises the type of database and compiles the first 5 lines of information.
Establishing a model validates 506 information lines and thirteen input variables as well as a single target numerical variable (14 in total). square measurement adjusted} additionally see that every variable input unit of a number is a number.
[5 rows x fourteen columns]
Ironically, the word lambda is arranged with the argument “alpha” and the method used in the section. The default price is 1.0 or full fine.
How its works
The L1 performance provides output in binary weights from 0 to 1 in model features and was adopted to reduce the number of features in a large size database. The L2 suspension spreads error targets across all weights leading to more accurate customizable final models. The descent of Ridge and Lasso is another.
The decrease in Lasso is similar to the decline of the line, but uses a process “decrease” in which the cut-off coefficients decrease towards zero. Lower lasso allows you to reduce or make these coefficients equal to avoid overcrowding and make them work better on different databases.
Ridge Regression is a method of analysing multiple retrospective data that suffers from multicollinearity. By adding a certain degree of bias to the regression ratings, the ridge retreat reduces common errors. It is hoped that the result will be to provide more accurate measurements.

- In short, ridge and lasso retreat are advanced retraction methods to predict, rather than speculation.
- Normal reversal gives you a neutral deviation coefficient (large probability values ”as noted in the data set”).
- Ridge and lasso downs allow you to normally make coefficients (“shrinkage”). This means that the estimated coefficients are pushed to 0, making them work better on new data sets (“predictive predictions”). This allows you to use complex models and avoid over-installation at the same time.
- In both the ridge and the lasso you have to set what is called a “meta parameter” which describes how the aggressive adjustment is performed. Meta parameters are usually selected with the opposite confirmation. For Ridge retrieval the meta parameter is usually called “alpha” or “L2”; it simply describes the power of adaptation. In LASSO the meta parameter is usually called “lambda”, or “L1”. In contrast to Ridge, the LASSO familiarity will actually set the less important predictions to 0 and help you in choosing predictions that can be left out of the model. These two methods are integrated into the “Elastic Net” Regularisation.
- Here, both parameters can be set, with “L2” defining customization power and “L1” and the minimum of the desired results.
- Even though the line model may be relevant to the data provided for modelling, it is not really guaranteed to be the best predictable data model.
- If our basic data follows a relatively simple model, and the model we use is too complex to perform the task, what we actually do is put a lot of weight on any possible changes or variations of the data. Our model is extremely responsive and compensates for even the slightest change in our data. People in the field of maths and machine learning call this situation overfitting. If you have features in your database that are closely linked in line with other features, it turns out that linear models may be overcrowded.
- Ridge Regression, avoids overlap by adding fines to models with very large coefficients.
Why it is important?
Difference between L1 and L2 Regularisation
The main difference between these methods is that the Lasso reduces the non-essential element to zero thus, eliminating a specific feature completely. Therefore, this works best for feature selection when we have a large number of features. Common methods such as reverse verification, retrospective follow-up handling over-install and feature feature selection work well with a small set of features but these techniques are a good option when dealing with a large set of features.
- It avoids overloading the model.
- They do not require fair measurements.
- They can add enough bias to make measurements a fairly reliable estimate of real human numbers.
- They still work well in large multivariate data cases with a number of predictions § larger than the reference number (n).
- The ridge scale is excellent for improving the ratio of small squares when there is multicollinearity.
- Evil
- They include all the predictions in the final model.
- Can’t select features.
- They shrink the coefficient to zero.
- They trade the difference for bias.
Advantage and Disadvantage
Conclusion
Now that we have a good idea of how the ridge and lasso regression work, let’s try to combine our understanding by comparing it and try to appreciate their specific operating conditions. I will also compare them with other methods. Let’s analyse these under three buckets:
1. Significant Differences
Ridge: Includes all (or no) features in the model. Therefore, the main advantage of ridge retraction is the reduction of the coefficient and the reduction of the complexity of the model.
Lasso: With slower coefficients, lasso makes feature selection as well. (Remember the ‘selection’ in full lasso form?) As we have seen before, some coefficients become exactly zero, the equivalent of a certain element extracted from the model.
2. Standard conditions of use
Ridge: Used extensively to prevent overcrowding. As it incorporates all the features, it is not very useful in the case of #supported features, if they mean millions, as it will present computational challenges.
Lasso: As it offers a few solutions, it is usually an optional model (or alternative to this concept) in modelling situations where the #million features or more. In such a case, finding a small solution is of great calculation as features with zero coefficients can simply be overlooked.
It is not difficult to see why the methods that follow the steps become so difficult to apply in situations of high magnitude. Thus, lasso offers great benefits.
3. Presence of Highly Related Features
Ridge: It usually works well even when there are highly related features as it will integrate them all into the model but the coefficients will be distributed between them depending on the relative.
Lasso: Ignorantly selects any feature among the most connected and lowers the coefficients otherwise to zero. Also, the selected variables change randomly by changing the parameters of the model. This usually does not work very well compared to ridge receding.
This lasso misalignment can be seen in the example we mentioned above. As we applied polynomial regression, the variables were highly correlated. (Not sure why? Check out the data.corr () output. Therefore, we observed that even the smallest alpha values provided a significant minimum (i.e. the highest coefficients are # like zero).




