
Last updated on 17th Jun 2025| 9645
- Definition of Neural Networks
- History and Evolution
- Components: Neurons, Weights, Layers
- Activation Functions Explained
- Types of Neural Networks
- Backpropagation Algorithm
- Training a Neural Network
- Real-world Applications
Definition of Neural Networks
Neural networks are a class of machine learning models inspired by the human brain’s interconnected neuron structure, designed to process and analyze complex data patterns. These networks consist of layers of nodes also called neurons, organized into an input layer, one or more hidden layers, and an output layer. Each node receives input, applies a mathematical transformation using an activation function, and passes the result to the next layer through weighted connections. The learning process involves adjusting these weights using algorithms such as backpropagation and gradient descent to minimize errors between predicted and actual outputs. Neural networks are capable of learning both linear and non-linear relationships, making them highly effective for tasks like image recognition, language translation, speech processing, and data prediction. Data Science training equips individuals with the necessary skills to understand and apply these powerful models, enabling them to tackle complex real-world problems with advanced machine learning techniques. Deep neural networks, or deep learning models, extend this concept by incorporating many hidden layers, allowing the network to extract high-level features and perform more abstract reasoning. Their adaptability and accuracy have made them a cornerstone of modern artificial intelligence, powering technologies from virtual assistants to autonomous vehicles. In essence, neural networks enable machines to learn from experience, identify patterns, and make data-driven decisions in a way that mimics human cognitive processes.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
History and Evolution
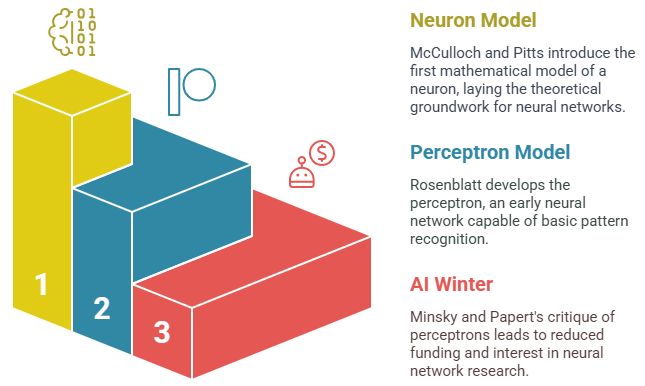
- 1943 – Birth of the Concept: Warren McCulloch and Walter Pitts introduced the first mathematical model of a neuron, laying the theoretical groundwork for neural networks.
- 1958 – Perceptron Model: Frank Rosenblatt developed the perceptron, an early type of neural network capable of basic pattern recognition, sparking interest in machine learning.
- 1969 – AI Winter Begins: Marvin Minsky and Seymour Papert highlighted the limitations of perceptrons, especially their inability to solve non-linear problems, leading to reduced funding and interest. Data Analytics Training Top Reasons to Learn Now include understanding such foundational challenges to grasp today’s AI advancements.
The development of neural networks has spanned decades, rooted in early attempts to model how the human brain processes information. Initially inspired by biological neurons, neural networks have evolved through multiple waves of innovation, each driven by advances in theory, computing power, and real-world applications. From simple models in the 1940s to today’s deep learning systems, their history reflects the broader journey of artificial intelligence.
- 1980s – Backpropagation Breakthrough: The reintroduction of multilayer networks and the backpropagation algorithm allowed neural networks to learn more complex tasks, reviving interest.
- 1990s–2000s – Gradual Progress: Research continued with moderate success in applications like handwriting recognition and speech processing, supported by improved algorithms and datasets.
- 2010s–Present – Deep Learning Revolution: With increased computational power and big data, deep neural networks emerged, enabling breakthroughs in image recognition, language processing, and AI-driven technologies.
Components: Neurons, Weights, Layers
Neural networks are composed of three fundamental components: neurons, weights, and layers, each playing a crucial role in processing data. Neurons, the basic units of a neural network, are modeled after the neurons in the human brain. Each neuron receives input, processes it using a mathematical function, and passes the result to other neurons in subsequent layers. Neurons are organized into layers: the input layer, hidden layers, and the output layer. The input layer receives the initial data, which is then passed through one or more hidden layers, where complex transformations and pattern recognition occur before reaching the output layer, which delivers the final result or prediction. This process is a key concept in understanding what is data analytics as it demonstrates how data is transformed into actionable insights using machine learning models. Weights are the connections between neurons, determining the strength of the signal passed from one neuron to the next. These weights are initially set randomly but are adjusted during training to minimize the difference between the network’s predictions and the actual outputs. The adjustment process occurs through backpropagation, a learning algorithm that fine-tunes the weights over time. Together, neurons, weights, and layers enable a neural network to learn from data, detect patterns, and make informed predictions, forming the foundation for tasks such as classification, regression, and pattern recognition in artificial intelligence.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Activation Functions Explained
- Purpose of Activation Functions: The primary role of activation functions is to decide whether a neuron should be activated or not, based on its input. This non-linearity allows the network to learn complex patterns in data.
- Sigmoid Function: The sigmoid function outputs values between 0 and 1, making it useful for binary classification problems. However, it suffers from the vanishing gradient problem, which can slow down training.
- ReLU (Rectified Linear Unit): ReLU is a popular activation function that outputs the input if positive, otherwise zero. It’s efficient, helps avoid vanishing gradients, and speeds up training. It’s also relevant in Expert Systems in Artificial Intelligence which rely on such functions for smart decision-making.
- Leaky ReLU: A variation of ReLU, Leaky ReLU allows a small, non-zero slope for negative input values, addressing the issue of “dying neurons” where ReLU might output zero for all inputs.
- Tanh (Hyperbolic Tangent): The tanh function outputs values between -1 and 1, making it suitable for problems requiring outputs in this range. It has a steeper gradient than the sigmoid but still faces vanishing gradient issues.
- Softmax Function: Typically used in the output layer for multi-class classification problems, softmax normalizes the output values into a probability distribution, ensuring all output values sum to 1, representing the probability of each class.
- Error Calculation: Backpropagation begins by calculating the error at the output layer, which is the difference between the predicted output and the actual output.
- Propagation of Error: This error is then propagated backward through the network, layer by layer, starting from the output layer and moving toward the input layer.
- Gradient Calculation:At each layer, the algorithm computes the gradient of the error with respect to the weights by applying the chain rule of calculus. This tells us how much the weights contributed to the error. Understanding this process is key to grasping Data Science vs Artificial Intelligence, as data science focuses on data analysis and modeling, while AI involves building intelligent systems that learn from data.
- Weight Update: Once the gradients are computed, the weights are updated using an optimization algorithm, typically gradient descent, to minimize the error. The weights are adjusted in the opposite direction of the gradient.
- Learning Rate: A learning rate determines the size of the weight adjustments. If the learning rate is too high, the model might overshoot the optimal solution, and if it’s too low, training can be slow.
- Iterative Process: Backpropagation is performed iteratively over multiple epochs. With each iteration, the weights are refined, leading to increasingly accurate predictions by the network.
Activation functions are critical components of neural networks, determining the output of each neuron and helping the network learn complex patterns. These functions introduce nonlinearity into the model, enabling neural networks to handle more sophisticated tasks beyond simple linear relationships. Without activation functions, neural networks would only be capable of solving linear problems, limiting their effectiveness.

Types of Neural Networks
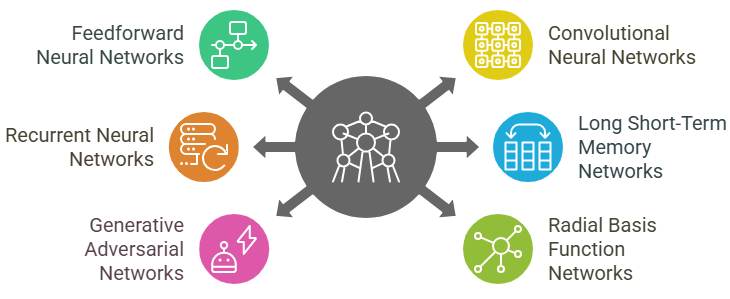
Neural networks come in various types, each designed for specific tasks and applications. The most basic type is the Feedforward Neural Network (FNN), where data moves in one direction from input to output without looping back. It’s ideal for tasks like classification and regression. The Convolutional Neural Network (CNN), widely used in image and video recognition, specializes in processing grid-like data, such as images, by applying convolutional layers to capture spatial hierarchies in data. Data Science training helps learners understand and implement CNNs effectively, enabling them to develop advanced solutions in computer vision and related fields. Recurrent Neural Networks (RNNs), on the other hand, are designed for sequential data, such as time series or language, where the output from previous steps influences future steps, making them perfect for tasks like speech recognition or natural language processing. Long Short-Term Memory (LSTM) networks are a special kind of RNN that addresses the issue of long-term dependency, enabling them to retain information over longer periods, making them useful for tasks like language translation. Generative Adversarial Networks (GANs) consist of two competing networks, a generator and a discriminator, that work together to generate realistic data, such as images or videos. Finally, Radial Basis Function Networks (RBFNs) are used for pattern recognition and classification tasks, utilizing radial basis functions as activation functions. Each of these neural network types is suited to specific problems, showcasing the flexibility and power of deep learning models in various domains.
Backpropagation Algorithm
The backpropagation algorithm is a fundamental technique used to train neural networks by minimizing the error between predicted and actual outputs. It is a supervised learning method that updates the weights of the network based on the gradients of the loss function concerning each weight. Through backpropagation, the network learns by adjusting weights in a way that reduces prediction error over time.
Training a Neural Network
Training a neural network involves adjusting the network’s weights and biases to minimize the error between its predictions and the actual outcomes. The process begins with initializing the weights randomly and passing input data through the network to generate an initial output. The difference between the predicted output and the actual target values is measured using a loss function, such as mean squared error or cross-entropy loss. Understanding how to compute and minimize this loss is crucial in SQL for Data Science as SQL is often used to manage and manipulate the data that feeds into machine learning models. Once the error is calculated, the backpropagation algorithm is employed to compute the gradients of the loss function concerning each weight in the network. These gradients indicate how much each weight contributed to the error, allowing the network to adjust the weights in the right direction. Optimization algorithms like gradient descent are used to update the weights, typically by moving them in the direction that reduces the error. The learning rate, a key hyperparameter, controls the step size for weight adjustments. Training is an iterative process, with data passed through the network multiple times (epochs) to gradually improve the model’s performance. Over time, as the weights are fine-tuned, the network learns to make more accurate predictions. The effectiveness of training is often monitored using a validation set to avoid overfitting and ensure the network generalizes well to unseen data.
Go Through These Data Science Interview Questions & Answer to Excel in Your Upcoming Interview.
Real-world Applications
Neural networks have revolutionized various industries by enabling machines to solve complex problems that were once thought to require human intelligence. In computer vision, Convolutional Neural Networks (CNNs) are used extensively in facial recognition, object detection, and medical image analysis, allowing for automated diagnoses and accurate visual recognition. In natural language processing (NLP), Recurrent Neural Networks (RNNs) and transformers like GPT-3 are employed in language translation, chatbots, sentiment analysis, and content generation, enabling machines to understand and generate human language. Data Science training provides the foundational knowledge and practical skills needed to work with these advanced NLP models, empowering professionals to build intelligent language-based applications. Speech recognition systems like virtual assistants (e.g., Siri, Alexa) rely on neural networks to convert spoken language into text and respond to user queries. Autonomous vehicles utilize neural networks for tasks such as object detection, route planning, and decision-making, enabling self-driving cars to navigate complex environments safely. In finance, neural networks are applied for stock market predictions, fraud detection, and risk management by analyzing vast amounts of financial data to make informed decisions. Healthcare is another field where neural networks play a pivotal role, from predicting patient outcomes to personalized treatment plans and drug discovery. These applications highlight the versatility and power of neural networks in tackling real-world challenges, improving efficiency, and driving innovation across multiple sectors.




