
Last updated on 17th Jun 2025| 9763
- Overview of Data Scientist Role
- Skills Required (Technical + Soft Skills)
- Typical Day of a Data Scientist
- Tools and Languages Used
- Data Collection and Cleaning
- Exploratory Data Analysis
- Model Building and Evaluation
- Business Communication and Reporting
Overview of Data Scientist Role
A Data Scientist is a professional who uses advanced analytical techniques, machine learning algorithms, and statistical models to extract valuable insights from complex data sets. Their primary role involves collecting, cleaning, and organizing large volumes of structured and unstructured data, then applying mathematical and computational tools to analyze it. Data Scientists develop predictive models and data-driven solutions to solve business problems, optimize processes, and improve decision-making. They are skilled in programming languages such as Python, R, and SQL, and have a deep understanding of statistical methods and data visualization techniques. The role also requires familiarity with big data technologies and cloud computing platforms, as well as Data Science training and the ability to collaborate with other teams, including engineers and business analysts. A successful Data Scientist is not only proficient in technical skills but also possesses strong problem-solving capabilities, critical thinking, and communication skills to present their findings clearly and effectively to non-technical stakeholders. Data Scientists are in high demand across various industries, including finance, healthcare, e-commerce, and technology, as organizations increasingly rely on data-driven insights to stay competitive and innovate in an ever-evolving marketplace.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Skills Required (Technical + Soft Skills)
- Programming Proficiency: Strong knowledge of programming languages such as Python, R, and SQL is essential for data manipulation, analysis, and building machine learning models.
- Statistical and Mathematical Skills:A solid foundation in statistics, probability, linear algebra, and calculus is necessary for designing models, hypothesis testing, and data interpretation, all of which are essential to understanding What is Data Analytics is and how it drives informed decision-making.
- Data Wrangling and Cleaning: The ability to preprocess, clean, and transform raw data is vital, as real-world data is often messy and incomplete.
To excel as a Data Scientist, a combination of strong technical expertise and essential soft skills is crucial. While technical skills enable the development and application of data models, soft skills ensure effective communication, problem-solving, and collaboration. Together, these competencies allow Data Scientists to turn raw data into actionable insights that drive meaningful business outcomes.
Key Skills: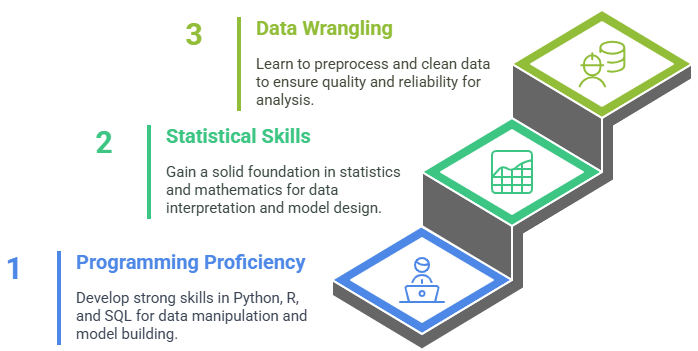
- Machine Learning and Modeling: Experience with machine learning algorithms, model selection, training, and evaluation is a key technical requirement for predictive analytics.
- Data Visualization and Communication: Skills in tools like Tableau, Power BI, or libraries like Matplotlib and Seaborn help in presenting data insights clearly to stakeholders.
- Critical Thinking and Collaboration: Strong analytical thinking, curiosity, and the ability to work well in cross-functional teams are essential for solving problems and delivering impactful results.
Typical Day of a Data Scientist
A typical day for a Data Scientist involves a balanced mix of data exploration, model development, collaboration, and communication. The day often begins by reviewing emails and project updates and setting priorities. Next, they dive into data preprocessing tasks, cleaning, transforming, and validating datasets to ensure accuracy and relevance. This is followed by exploratory data analysis (EDA), where they identify patterns, trends, or anomalies using statistical tools and visualizations. Once the data is understood, they move on to building or refining predictive models using machine learning algorithms. This may involve tuning hyperparameters, evaluating model performance, and selecting the best approach. Collaboration is also a key part of their day, with meetings alongside data engineers, analysts, product managers, or stakeholders to discuss project goals, share findings, and align on business objectives. In between, they document their work, update dashboards, and may even prepare presentations or reports to communicate insights clearly to non-technical audiences, often incorporating knowledge from an R Certification overview to enhance their analytical and reporting skills. Additionally, a portion of their time is dedicated to learning whether it’s exploring new tools, reading research papers, or experimenting with innovative techniques. While no two days are exactly alike, the core focus remains on using data to generate value and support informed decision-making within the organization.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Tools and Languages Used
- Python: Widely used for its simplicity and powerful libraries like Pandas, NumPy, Scikit-learn, TensorFlow, and PyTorch for data analysis and machine learning.
- R: Preferred for statistical analysis and data visualization, with strong packages like ggplot2, dplyr, and caret.
- SQL: Essential for querying and managing structured data stored in relational databases such as MySQL, PostgreSQL, and SQL Server, which also supports understanding what Predictive Analytics involves when working with historical data to forecast future trends.
- Tableau/Power BI: Popular data visualization tools that help present insights through interactive dashboards and reports for non-technical stakeholders.
- Jupyter Notebooks: An interactive development environment used for writing and sharing code, visualizations, and documentation all in one place.
- Apache Spark/Hadoop: Used for big data processing and analysis, enabling Data Scientists to handle large-scale datasets efficiently across distributed systems.
- Understanding Data Structure: Reviewing data types, dimensions, and column names to gain a basic overview of the dataset.
- Summary Statistics: Generating measures such as mean, median, mode, standard deviation, and percentiles to understand data distribution.
- Missing Value Analysis: Identifying and handling missing or null values to ensure the dataset is complete and consistent is a fundamental step in understanding What is Data Engineering entails in the data preparation process.
- Outlier Detection: Spotting unusual data points using box plots, z-scores, or interquartile range (IQR) methods to determine if they need to be removed or treated.
- Correlation Analysis: Evaluating relationships between variables using correlation matrices or heatmaps to identify strong or weak associations.
- Data Visualization: Creating charts such as histograms, scatter plots, and bar graphs to visually explore data trends and distributions, making complex patterns easier to interpret.
Data Scientists rely on a variety of tools and programming languages to efficiently gather, analyze, visualize, and model data. These technologies help streamline workflows, handle large datasets, and produce actionable insights. Mastery of these tools is essential for performing tasks such as data cleaning, statistical analysis, and deploying machine learning models.
Common Tools and Languages:
Data Collection and Cleaning
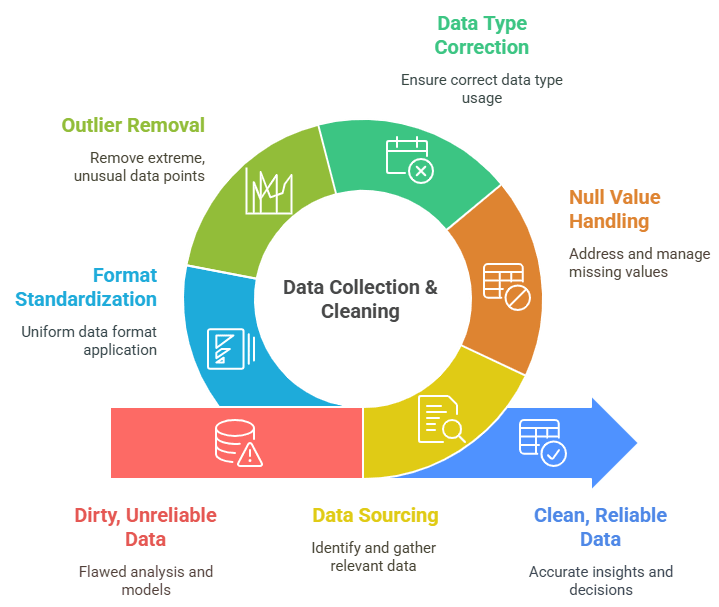
Data collection and cleaning are foundational steps in the data science workflow, as the quality and reliability of data directly impact the accuracy of any analysis or model. The process begins with identifying and sourcing relevant data, which may come from internal databases, APIs, third-party providers, or web scraping. Once collected, the raw data often contains errors, missing values, duplicates, or inconsistencies that must be addressed. Data cleaning involves techniques such as handling null values, correcting data types, removing outliers, and standardizing formats to ensure uniformity. It also includes applying Data Science training to merge datasets, handle categorical variables, and encode data to prepare it for analysis or modeling. This step is often time-consuming, estimated to take up to 70-80% of a Data Scientist’s time, but it is critical for building trustworthy models. Without clean and well-structured data, even the most advanced algorithms will produce flawed or misleading results. In addition to technical tasks, data cleaning also requires domain knowledge to make informed decisions about what data is relevant and how to treat anomalies. Overall, effective data collection and cleaning lay the groundwork for meaningful analysis, helping Data Scientists draw accurate insights and support informed decision-making within an organization.
Exploratory Data Analysis
Exploratory Data Analysis (EDA) is a crucial phase in the data science process where Data Scientists explore datasets to uncover patterns, spot anomalies, test hypotheses, and check assumptions using visual and statistical techniques. EDA helps in understanding the structure, relationships, and quality of the data before applying any machine learning models. It provides valuable insights that guide further analysis and decision-making.
Key Steps in Exploratory Data Analysis:Model Building and Evaluation
Model building and evaluation are central to the data science process, where insights from cleaned and analyzed data are transformed into predictive or classification models. This stage begins with selecting the appropriate algorithm based on the problem type, such as regression, classification, clustering, or recommendation. Data Scientists split the dataset into training and testing (and sometimes validation) sets to train the model and assess its performance. During training, features are fed into the algorithm to learn patterns and relationships. Hyperparameter tuning, cross-validation, and feature engineering are often employed to enhance model accuracy and robustness, typically implemented using some of the explore our Best Data Science Programming Languages such as Python and R. Once the model is trained, it is evaluated using metrics like accuracy, precision, recall, F1 score, ROC-AUC (for classification), or RMSE and MAE (for regression). These metrics help determine how well the model performs and whether it can generalize to unseen data. If results are unsatisfactory, Data Scientists iterate, refining features, trying different algorithms, or addressing data imbalances. Model evaluation also includes checking for overfitting or underfitting and ensuring fairness and transparency. Ultimately, the goal is to develop a reliable, interpretable model that delivers actionable insights or predictions, aligning with business objectives and enabling informed decision-making.
Go Through These Data Science Interview Questions & Answer to Excel in Your Upcoming Interview.
Business Communication and Reporting
Business communication and reporting are vital aspects of a Data Scientist’s role, as they bridge the gap between complex data analysis and actionable business decisions. Once insights are derived from data and models are built, it’s essential to present findings in a clear, concise, and meaningful way to both technical and non-technical stakeholders. This involves applying Data Science training to translate technical results into business language, highlighting key trends, opportunities, risks, and recommendations that align with organizational goals. Effective communication often includes creating visualizations, dashboards, and written reports using tools like Tableau, Power BI, or presentation software to make the data easily digestible. Storytelling with data is also a key skill, allowing Data Scientists to construct a narrative that guides decision-makers through the insights and supports strategic planning. In meetings or briefings, Data Scientists must be prepared to answer questions, explain methodologies, and justify their conclusions with confidence and clarity. Regular communication ensures alignment across teams, helps prioritize data-driven projects, and fosters a culture of informed decision-making. In essence, strong business communication and reporting not only amplify the impact of data science work but also ensure that valuable insights lead to meaningful business outcomes.




