
Last updated on 09th Jul 2020| 2004
Let us discuss some of the major difference between Data Mining and Machine Learning:
- To implement data mining techniques, it used two-component first one is the database and the second one is machine learning. The Database offers data management techniques while machine learning offers data analysis techniques. But to implement machine learning techniques it used algorithms.
- Data Mining uses more data to extract useful information and that particular data will help to predict some future outcomes for example in a sales company it uses last year data to predict this sale but machine learning will not rely much on data it uses algorithms, for example, OLA, UBER machine learning techniques to calculate the ETA for rides.
- Self-learning capacity is not present in data mining, it follows the rules and predefined. It will provide the solution for a particular problem but machine learning algorithms are self-defined and can change their rules as per the scenario, it will find out the solution for a particular problem and it resolves it by its own way.
- The main and foremost difference between data mining and machine learning is, without the involvement of human data mining can’t work but in machine learning human effort is involved only the time when algorithm is defined after that it will conclude everything by own means once implemented forever to use but this is not the case with data mining.
- The result produces by machine learning will be more accurate as compared to data mining since machine learning is an automated process.
- Data mining uses the database or data warehouse server, data mining engine and pattern evaluation techniques to extract the useful information whereas machine learning uses neural networks, predictive model and automated algorithms to make the decisions.
As technology continues to advance and expand, a whole new range of technical terms and concepts are born from time to time. With the advent of Big Data and Data Science, today, we have Artificial Intelligence, Machine Learning, and Deep Learning. Since these new technologies are all inter-related and connected, people often tend to technological terms interchangeably. Two such terms are “Data Mining” and “Machine Learning.”
The Data Mining vs Machine Learning debate has been doing the rounds for quite a while now. Although both these Data Science concepts have been around us since the 1930s, they’ve only recently come to the fore. Oftentimes, people tend to blur the lines of difference between Data Mining and Machine Learning due to the presence of certain similar characteristics between the two. However, both are inherently different, and that’s what we wish to bring to light in this post – the difference between Data Mining and Machine Learning.
Data Mining
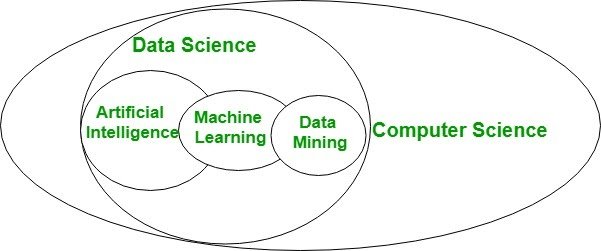
Data Mining refers to the process of discovering meaningful patterns in large and complex datasets through a combination of multiple disciplines and tools, including Computer Science, Machine Learning, Statistics, and database systems. Data Mining is a subset of Machine Learning that centers around exploratory data analysis through unsupervised learning.
The end goal of Data Mining is to extract relevant information (and not the “extraction” of raw data itself) from datasets and transform the same into business-savvy insights for further use.

Get Machine Learning Training from Industry Experts Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Machine Learning
Machine Learning is a sub-branch of Artificial Intelligence. It is the scientific study of intelligent algorithms and statistical models that can be used by machines (computers) to perform human-like tasks without being explicitly programmed or trained for it. A unique aspect of Machine Learning algorithms is that they can learn through experience.
Data mining and Machine learning Comparison Table
Below are the lists of points, describe the comparison between Data Mining and Machine Learning
| Basis for Comparison | Data Mining | Machine Learning |
|---|---|---|
| Meaning | Extracting knowledge from a large amount of data | Introduce a new algorithm from data as well as past experience |
| History | Introduced in 1930, initially referred as knowledge discovery in databases | Introduced in near 1950, the first program was Samuel’s checker-playing program |
| Responsibility | Data mining is used to get the rules from the existing data. | Machine learning teaches the computer to learn and understand the given rules. |
| Origin | Traditional databases with unstructured data | Existing data as well as algorithms. |
| Implementation | We can develop our own models where we can use data mining techniques for | We can use machine learning algorithm in the decision tree, neural networks and some other area of artificial intelligence. |
| Nature | Involves human interference more towards manual. | Automated, once design self-implemented, no human effort |
| Application | used in cluster analysis | used in web search, spam filter, credit scoring, fraud detection, computer design |
| Abstraction | Data mining abstract from the data warehouse | Machine learning reads machine |
| Techniques Involved | Data mining is more of research using methods like machine learning | Self-learned and trains system to do the intelligent task. |
| Scope | Applied in the limited area | Can be used in a vast area. |
Relationship between Data Mining and Machine Learning
There is no universal agreement on what “Data Mining” suggests that. The focus on the prediction of data is not always right with machine learning, although the emphasis on the discovery of properties of data can be undoubtedly applied to Data Mining always.
So, let’s begin with that: data processing may be a cross-disciplinary field that focuses on discovering properties of knowledge sets. (Forget concerning it being the analysis step of “knowledge discovery in databases” KDD, this was perhaps valid years gone, it’s not anymore).
There area unit different approaches to discovering the properties of knowledge sets. Machine Learning is one among them. Another one is just gazing the information sets victimization image techniques or Topological information Analysis.
On the opposite hand, Machine Learning may be a sub-field of knowledge science that focuses on planning algorithms that may learn from and create predictions on the information. Machine learning includes supervised Learning and Unsupervised Learning ways. Unsupervised ways take off from unlabeled information sets, so, in a way, they’re associated directly with looking for unknown properties in them (e.g., clusters or rules).
It is clear then that machine learning will be used for data processing. However, data processing will use different techniques besides or on high of machine learning.
To create things even a lot of sophisticated, currently, we have a replacement term, information Science, that’s competitor for attention, particularly with data processing and KDD. Even the SIGKDD cluster at ACM is slowly moving towards victimization information Science. In their web site, they currently describe themselves as “The community for data processing, information science, and analytics.” According to the predictions, KDD can disappear as a term pretty before lengthy edition, and data processing can merely merge into an information science.
Say the matter is to filter Outliers from your information (Anomaly detection), which might be a knowledge Mining task. One could build use of standard Machine Learning techniques like K-means algorithmic rule in Cluster analysis to spot these outliers and build the algorithmic rule to learn whereas doing this.
Now, these Outliers square measure ‘Previously Unknown, ’ and thus the task was same to be of information Mining, whereas Machine Learning comes into an image with the ‘Learning’ attribute of the algorithmic rule wont to find the outliers.
To “teach the machine” you wish information. As an example, if you would like to train a neural web for predicting the winner of the Superbowl, you can’t merely sort in UN agency won that games for the year. That’s not reaching to be enough. You will wish a lot of information, like the maximum amount as you’ll be able to get. You want for each stat for each player ideally for his or her entire careers. A lot of information you’ve got, a lot of the neural web will learn from the same details. I attempted coaching a neural network to form practical jokes and that I had like 10kb of information. I believed that was loads, then found a diary wherever somebody was victimization over 3mb. That’s why you wish data processing. If you’re thinking that of the pc as someone, however long will it take someone to be told to speak? They observe several conversations; they don’t merely hear ten conversations then as if by magic become fluent. Thus essentially, data processing is one among the earliest steps toward machine learning. You mine the info, then organize, normalize, etc. because of the initial stages of coaching a neural web.




