
Last updated on 25th Apr 2025| 10106
- Introduction to Apache Airflow
- Use Cases of Apache Airflow
- Understanding DAGs in Airflow
- Real-World Use Case of DAGs
- Creating an Airflow DAG
- Data Pipeline Best Practices
- Using Airflow with Kubernetes
- Conclusion
Introduction to Apache Airflow
Apache Airflow is an open-source platform designed for orchestrating and automating complex data workflows. It allows users to define, schedule, and monitor data pipelines using Directed Acyclic Graphs (DAGs), offering a flexible solution for managing ETL processes, data integration, and machine learning workflows. Airflow’s modular architecture ensures scalability, supporting various executors like Sequential, Local, Celery, and Kubernetes, which makes it adaptable to different workload sizes. The platform provides a web-based UI that enables real-time monitoring, allowing users to easily track DAG execution, inspect logs, and manage tasks, making it an essential tool in Data Science Training. Airflow also supports operators, sensors, and hooks, which enable seamless integration with cloud services, databases, and APIs, making it highly versatile. Its extensibility through custom plugins further enhances its adaptability, allowing users to tailor the platform to their specific data engineering needs. By automating workflows, Airflow improves data processing efficiency, reduces manual intervention, and ensures the reliability of data pipelines. This makes it an invaluable tool for teams working on data engineering, machine learning, and complex data management tasks.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Use Cases of Apache Airflow
- ETL Pipelines – Automate data extraction, transformation, and loading from different sources into data warehouses.
- Machine Learning Pipelines – Schedule and orchestrate model training, validation, and deployment workflows.
- Data Warehousing and Reporting – Process data for business intelligence dashboards and reports.
- DevOps and CI/CD Workflows – Automate software deployment processes and system monitoring, which can be enhanced by understanding What is EDA in Data Science.
- Cloud Data Orchestration – Manage workflows across cloud environments efficiently.
- Data Integration – Seamlessly combine and process data from multiple sources, enabling comprehensive analysis and decision-making.
- Event-Driven Workflows – Automate processes based on specific triggers or events, enabling real-time data processing and responses.
- Tasks: Represent individual work units, such as data extraction, transformation, or model training.
- Operators: Define task execution behavior, specifying what type of action each task performs.
- Dependencies: Define execution order using upstream/downstream relationships, ensuring tasks execute in the correct sequence.
- Task Groups: These are used to group tasks logically within a DAG for better organization.
- Hooks and Plugins: IntegraAirflow’s systems extend Airflow’s functionality, similar to Semantic Networks vs Ontologies in AI.
- Running – The DAG is currently executing.
- Success – The DAG completed execution without any errors.
- Failed – The DAG execution failed due to an error.
- Paused – The DAG is not running but remains available for execution.
- from Airflow import DAG
- from Airflow.operators.python_operator import PythonOperator
- from datetime import datetime
- print(“Hello, Apache Airflow!”)
- with DAG(
- dag_id=’hello_airflow’,’ schedule_interval=’@daily’,’ start_date=datetime(2023, 1, 1),
- catchup=False
- task1 = PythonOperator(
- task_id=’print_hello’,’ python_callable=print_hello
- )
- Clear Data Quality Standards: Ensure that data quality is maintained throughout the pipeline by implementing validation rules. This includes checks for missing values, duplicates, and ensuring consistency across data sources.
- Modular Design: Break down your pipeline into smaller, reusable components or tasks. This modular approach enhances maintainability and allows for easy updates without disrupting the entire workflow.
- Scalability: Design your data pipeline with scalability in mind. As data volumes grow, the pipeline should be able to handle increased loads, whether that involves parallel processing or distributed systems.
- Error Handling and Logging: Implement robust error handling mechanisms and logging throughout the pipeline. This helps in identifying bottlenecks or failures and allows for quicker troubleshooting, especially in Artificial Intelligence in Robotics.
- Automation and Scheduling: Automate repetitive tasks such as data extraction, transformation, and loading (ETL). Use scheduling tools (like Apache Airflow) to run these processes at specific intervals, ensuring timely data delivery.
- Version Control: Use version control for both code and data schema changes. This ensures that modifications can be tracked and rolled back if necessary.
- Security and Compliance: Protect sensitive data by enforcing proper access control and encryption. Adhere to relevant regulatory requirements such as GDPR when handling personal data.
- Monitoring and Alerts: Continuously monitor your data pipeline to detect failures or performance issues. Set up alerts to notify teams of issues, allowing for quick responses to minimize disruptions.
Understanding DAGs in Airflow
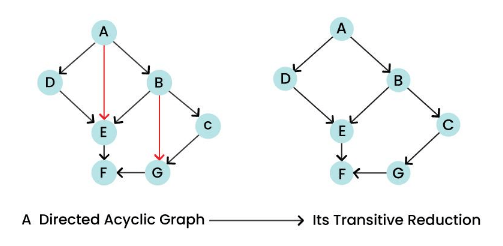
A Directed Acyclic Graph (DAG) is a collection of tasks organized in a way that defines dependencies and execution order. DAGs do not contain cycles, ensuring a linear execution of tasks.
DAG Components
DAG Execution States
Do You Want to Learn More About Data Scientists? Get Info From Our Data Science Course Training Today!
Real-World Use Case of DAGs
Imagine a data pipeline for an e-commerce company that processes daily sales data using Apache Airflow. The workflow begins with a Directed Acyclic Graph (DAG) designed to automate the entire process. First, sales data is extracted from an external API, which provides real-time transactional information. The next step involves transforming this raw data into a structured format, cleaning it to ensure consistency and accuracy, while considering Uncertainty in Artificial Intelligence. Once the data is properly formatted, it is loaded into a data warehouse, where it can be easily accessed for further analysis. The pipeline then generates daily sales reports, providing the business with insights into performance, trends, and key metrics.
Additionally, the pipeline can trigger marketing automation tasks, such as sending promotional emails or adjusting ad targeting, based on the sales trends identified. By automating these tasks in a sequential manner, the DAG ensures that each task is completed correctly, preventing data inconsistencies and improving the efficiency of operations. This data pipeline optimizes the e-commerce company’s ability to respond quickly to changing sales patterns and customer behavior.

Creating an Airflow DAG
DAGs are written in Python and stored in the Airflow DAG folder. Below is an example of a simple DAG, which is often covered in Data Science Training:
def print_hello():
) as dag:
This example defines a DAG named hello_airflow. It contains a single task that prints a message. The DAG is scheduled to run daily starting January 1, 2023.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Data Pipeline Best Practices
Using Airflow with Kubernetes
Using Apache Airflow with Kubernetes provides a powerful solution for managing and scaling data workflows in a containerized environment. Kubernetes offers orchestration for containerized applications, allowing Airflow to run tasks across distributed resources, ensuring scalability and flexibility. By deploying Airflow on Kubernetes, users can leverage its native features like pod management, auto-scaling, and resource isolation, making it easier to handle large and complex workflows. Airflow tasks can be executed within Kubernetes pods, which allows for better resource utilization and isolation of individual tasks. This also ensures that tasks are scheduled and distributed efficiently across the available compute resources, highlighting the Role of Inference in AI and Machine Learning. Kubernetes’ ability to automatically scale resources up or down based on workload demands complements Airflow’s task scheduling capabilities, ensuring that workflows run smoothly even as demand fluctuates. In addition, Kubernetes integration with Airflow enables the use of KubernetesExecutor, which allows each task to run in its own pod, providing fine-grained control over resource allocation and improving fault tolerance. Furthermore, Kubernetes enhances the overall reliability and resilience of Airflow by managing container lifecycles, enabling easy deployment, updates, and rollbacks. This combination results in highly efficient, scalable, and maintainable data pipelines.
Go Through These Data Science Interview Questions & Answer to Excel in Your Upcoming Interview.
Conclusion
Apache Airflow is a powerful, open-source workflow orchestration tool designed to automate, schedule, and monitor complex data pipelines. It enables organizations to build scalable, reliable, and efficient workflows by defining Directed Acyclic Graphs (DAGs), which outline task dependencies and execution sequences. AiAirflow’slexibility allows for seamless integration with various data sources, cloud services, and third-party tools, making it a popular choice for data engineering and ETL (Extract, Transform, Load) processes. Organizations can enhance workflow reliability and reduce failures by following best practices such as modularizing DAGs, implementing proper error handling, and enabling retries, which are key components of effective Data Science Training. Leveraging KubernetesExecutor or CeleryExecutor further boosts scalability by distributing tasks across multiple workers or Kubernetes pods, ensuring efficient resource utilization. Optimizing performance through task parallelism, efficient use of XComs, and proper database configuration can significantly reduce execution time. AiAirflow’s intuitive UI allows real-time monitoring of DAG runs, task statuses, and performance metrics, aiding in proactive troubleshooting. Overall, Apache Airflow empowers organizations to automate complex workflows, streamline data processing, and ensure consistent, repeatable pipeline execution. Its extensibility and robust scheduling and monitoring capabilities make it a cornerstone tool for modern data engineering and workflow automation.




