
Last updated on 05th Jan 2022| 2789
Introduction to Supervised Machine Learning:
Supervised learning is the kind of machine learning in which devices are trained using well “labeled” training data, and based on that data, machines expect the output. The labeled data means some input data is already labeled with the proper output. In supervised learning, the training data nourished to the machines work as the manager that guides the machines to indicate the output accurately. It involves the same image as a student understands under the maintenance of the teacher.
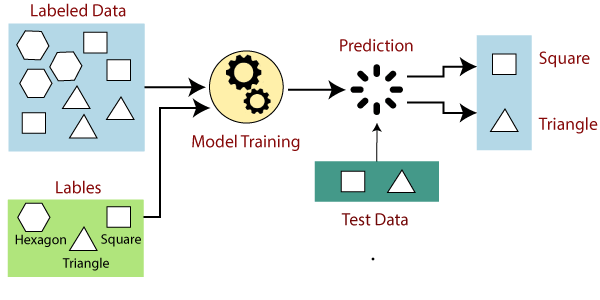
- If the provided shape has four sides, and all the flanks are equal, then it will be marked as a Square.
- If the delivered shape has three sides, then it will be marked as a triangle.
- If the shared shape has six equal sides then it will be tagged as a hexagon.
- Now, after training, we test our example utilizing the test set, and the reading of the model is to identify the shape. The machine is already trained on all kinds of shapes, and when it sees a new shape, it organizes the shape based on several sides and indicates the output.
How Supervised Learning Works?
In supervised learning, representatives are prepared using a marked dataset, where the cast learns about each type of data. Once the training process is concluded, the model is sampled based on test data (a subset of the training set), and then it indicates the output. The working of Supervised learning can be easily comprehended by the below example and diagram:
Suppose we have a dataset of various kinds of shapes that contain square, rectangle, triangle, and Polygon. Now the first step is that we need to train the model for each shape.
- First Select the type of training dataset.
- Order/Gather the tagged training data.
- Divide the training dataset into a training dataset, test dataset, and verification dataset.
- Choose the input elements of the training dataset, which should have enough details so that the model can accurately forecast the output.
- Choose the suitable algorithm for the model, such as help vector machine, decision tree, etc.
- Manage the algorithm on the training dataset. Sometimes we require validation sets as the command parameters, which are the subset of training datasets.
- Consider the accuracy of the model by feeding the test set. If the model indicates the correct output, which represents our model is correct.
Steps Involved in Supervised Learning:
- Linear Regression
- Regression Trees
- Non-Linear Regression
- Bayesian Linear Regression
- Polynomial Regression
- Random Forest
- Decision Trees
- Logistic Regression
- Support Vector Machines
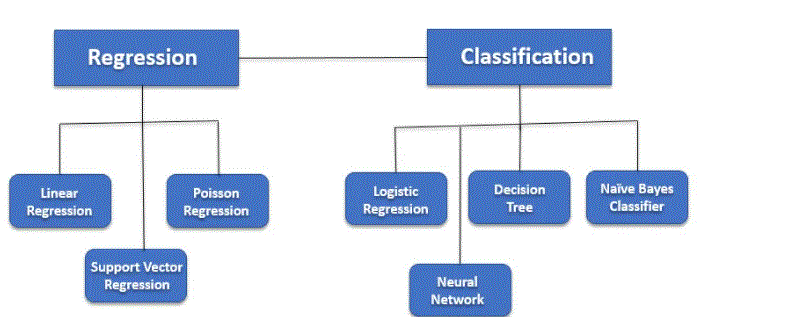
Types of supervised Machine learning Algorithms:
1. Regression
Regression algorithms are utilized if there is a connection between the input variable and the output variable. It is utilized for the forecast of continuous variables, such as Weather forecasting, Market Movements, etc. Below are some famous Regression algorithms which come under supervised learning:

Develop Your Skills with Advanced Suiteflow Workflow Certification Training
Weekday / Weekend BatchesSee Batch Details2. Classification
Classification algorithms are employed when the output variable is absolute, which means there are two types such as Yes-No, Male-Female, True-false, etc.
- With the benefit of supervised learning, the model can expect the output based on prior occasions.
- In supervised learning, we can have an accurate idea about the types of objects.
- A supervised learning model allows us to translate different real-world problems such as fraud detection, spam filtering, etc.
Advantages of Supervised learning:
- Supervised learning models are not appropriate for managing difficult tasks.
- Supervised learning cannot indicate the correct output if the test data is separate from the training dataset.
- Training needed lots of computation times.
- In supervised learning, we need sufficient details about the types of objects.
Disadvantages of supervised learning:
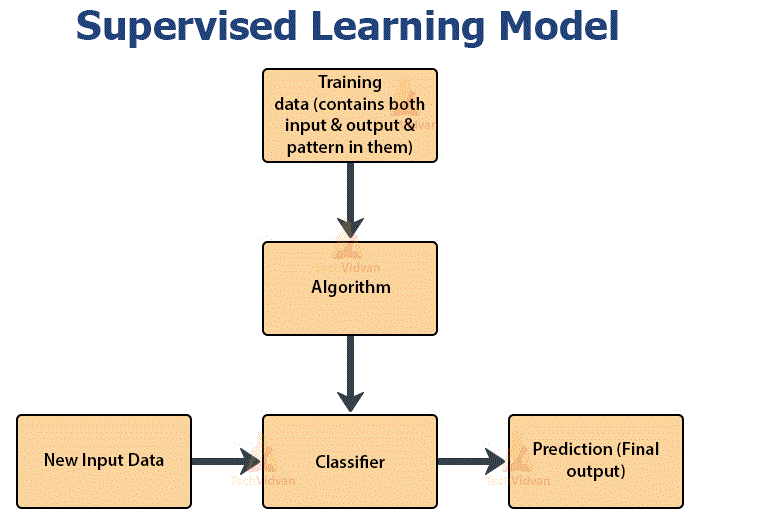
How does supervised learning work?
Like all machine learning algorithms, directed learning is founded on training. During its training phase, the system is provided with marked data sets, which require the system what output is connected to each specific input value. The trained model is then shown with test data: This is data that has been labeled, but the labels have not been shown to the algorithm. The testing data aim to gauge how accurately the algorithm will portray unlabeled data.
Supervised vs. Unsupervised learning:
The chief distinction between unsupervised and supervised learning is in how the algorithm learns. In unsupervised learning, the algorithm is presented unlabeled data as a training set. Unlike in supervised learning, there are no correct output values; the algorithm defines the patterns and parallels within the data, as opposed to relating it to some external measurement. In other words, algorithms can work voluntarily to learn more about the data and find attractive or incidental findings that human beings weren’t looking for. Unsupervised learning is prevalent in applications of clustering (the act of uncovering groups within data) and society (the act of predicting rules that define the data).
Example of a supervised learning project:
Regard the news categorization problem from earlier. One method is to choose which type each piece of news belongs to, such as business, finance, technology, or sports. To unravel this problem, a supervised model would be the best fit.
Humans would give the model different news articles and their categories and have the model learn what kind of news belongs to each category. This way, the model evolves talented at identifying the news type of any article it looks at based on its prior training knowledge.
Different Types of Supervised Learning:
Regression
A single output value is created using training data. This discount is a probabilistic interpretation, which is shown after evaluating the strength of correlation among the intake variables. For example, a regression can assist indicate the price of a house based on its locality, size, etc. In logistic regression, the output has discrete values based on a group of separate variables. This process can struggle when trading with non-linear and multiple decision limits. Also, it is not loose enough to capture difficult connections in datasets.
Classification
It affects grouping the data into classes. If you are considering expanding credit to a person, you can use type to determine whether or not an individual would be a loan defaulter. When the supervised learning algorithm tags input data into two distinct classes, it is called binary classification. Numerous classifications mean organizing data into more than two categories.
Naive Bayesian Model
The Bayesian model of classification is utilized for large limited datasets. It is a way of giving class labels using a direct acyclic graph. The graph includes one parent node and numerous children nodes. And each child node is considered to be independent and different from the parent.
Decision Trees
A decision tree is a flowchart-like model that includes conditional control statements, including decisions and their potential effects. The output relates to the labeling of unforeseen data. In the tree model, the leaf nodes are equal to class labels, and the interior nodes represent the details. A decision tree can be utilized to solve issues with discrete attributes as well as boolean functions. Some of the unique decision tree algorithms are ID3 and CART.
Random Forest Model
The random forest model is a costume method. It works by creating a multitude of decision trees and outputs a classification of the particular trees. Suppose you want to indicate which undergraduate students will perform well in GMAT a test is taken for entry into graduate management programs. A random forest example would complete the task, given the demographic and educational aspects of a set of researchers who have previously accepted the test.
Neural Networks
This algorithm is developed to cluster raw input, recognize ways, or analyze sensory data. Despite their numerous advantages, neural networks need substantial computational help. It can get difficult to fit a neural network when there are thousands of words. It is also called the ‘black-box’ algorithm as analyzing the logic behind their forecasts can be hard.
Support Vector Machines
Support Vector Machine (SVM) is a supervised learning algorithm formed in the year 1990. It pulls from the statistical learning theory created by Vap Nick. SVM diverges hyperplanes, which makes it a discriminating classifier. The output is made in the form of an optimal hyperplane that classifies new examples. SVMs are closely associated with the kernel framework and used in diverse fields. Some models have bioinformatics, pattern recognition, and multimedia data recovery.
Conclusion:
Supervised learning is the easiest subcategory of machine learning and serves as an opening to machine learning for many machine learning practitioners. Supervised learning is the most commonly employed form of machine learning, and has been demonstrated to be an ideal tool in many fields. This position was part one of a three-part series. Part two will cover unsupervised learning




