
Last updated on 16th Dec 2021| 2063
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
- Introduction to Web Crawler
- A Web Crawler overview
- Features of Web Crawler
- Web Crawler Architecture
- Web Crawler Security
- How do Web Crawlers work?
- Why are Web Crawlers called ‘spiders’?
- List of Web Crawlers
- Benefits of Web Crawler
- Conclusion
- Web Crawler, generally known as spider or spiderbot and is usually abbreviated to crawler, net} crawl that crawls the globe Wide net and is usually employed by search engines for web functions (spiders).
- Web search engines and different websites use net locomotion or spidering software packages to update their web page or web page indexes on different sites. net searchers copy pages for programme improvement, compartmentalisation downloaded pages thus users will search a lot of with efficiency.
- Searchers use resources on visited systems and sometimes visit sites all of sudden. issues with format, responsibility, and “respect” begin to figure once massive teams of pages are reached. ways that are offered on social media that don’t need to be crawled in order that this could be reported to crawlers. For instance, together with a robots.txt file will raise bots to show solely elements of a web site, or nothing in the slightest degree.
- The number of sites is extremely large; even the largest pilots fail to form a whole index. For this reason, search engines struggled to produce relevant search ends up in the first years of the globe Wide net, before 2000. Today, the correct results are being given as recently as potential.
- Searchers will verify links with markup language code. they will even be wont to kick net and data-driven systems.
Introduction to Web Crawler:
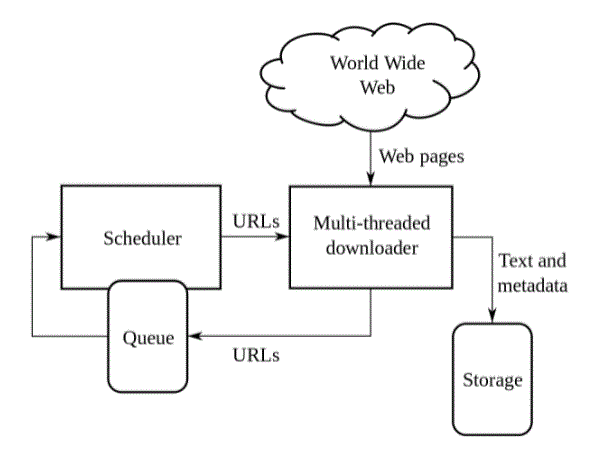
- Web search starts with a listing of URLs which will be visited. Those initial URLs are units referred to as seeds. Because the browser visits these URLs, by contacting the online servers that reply to those URLs, we tend to establish all the links on the came sites and add them to the list of URLs that may be visited, referred to as crawl frontier. URLs from the border area unit usually visited in line with a collection of policies. If the search ends with netsite|an internet site|a web site} archive (or web archive), we tend to copy and store the data because it travels. Archives area units typically keep in such the simplest way that they will be viewed, browsed and navigated as if they were on a live internet, however kept as ‘pictures’.
- Archive is understood as an associate degree archive and is intended to store and manage webpage collections. Archive solely saves markup language pages and these pages are unit saved as separate files. The repository is comparable to the other knowledge storage system, like a contemporary web site. The sole distinction is that the repository doesn’t need all the practicality offered by the info system. The archive keeps the newest version of the online page renovated to look.
- High volume implies that the browser will solely transfer a restricted variety of sites in a very given time, therefore we want to grade its transfer. A high level of modification could mean that the pages could have already been updated or deleted.
- The number of URLs that will be generated by a third-party software system has created it tough for internet searchers to avoid retrieving duplicate content. associate degree endless combination of HTTP GET (URL-based) parameters exists, solely a tiny low choice can come back the various content. as an example, an easy on-line photograph gallery could provide 3 choices for users, as laid out in the HTTP GET parameters within the uniform resource locator. With four image filter choices, 3 fingernail size choices, 2 file formats, and a user-provided disable choice, an equivalent content set may be accessed with forty eight totally different URLs, all of which might be coupled. place. This mixture of statistics creates a haul for searchers, as they need to arrange exploitation associate degrees with an endless combination of tiny written texts to seek out totally different content.
- As Edward et al. noted, “Because the scope of crawl traffic {is restricted|is restricted|is proscribed} and limited, it’s necessary to clear the online not solely cheaply, however effectively, if an explicit level of quality or youth ought to be maintained.” The searcher should fastidiously opt for every step he can visit.
A Web Crawler overview:
Features of Web Crawler:
Distributed:
The detective should be able to operate a cosmopolitan system.
Scalable:
The search structure ought to leave larger clarity by adding further resources and information measures.
Efficiency and efficiency:
The travel system ought to observe use of assorted system resources together with the processor, storage and network information measures.
Quality:
Considering that an outsized part of each web page may be a poor service in providing user queries, the searcher ought to be additional able to transfer the “ helpful ” pages initially.
New:
In most applications, the searcher should add continuous mode: we have a tendency to acquire new copies of antecedently downloaded pages. a pursuit engine search, for instance, will verify that the program index contains the present illustration of every indexed website. With such continuous clarity, the searcher ought to be able to specify a page with a frequency up to the conversion rate of that page.
Extensible:
Search ought to be engineered to expand in some ways – handling new knowledge formats, new transfer agreements, and so on. This needs the search design to be standard.
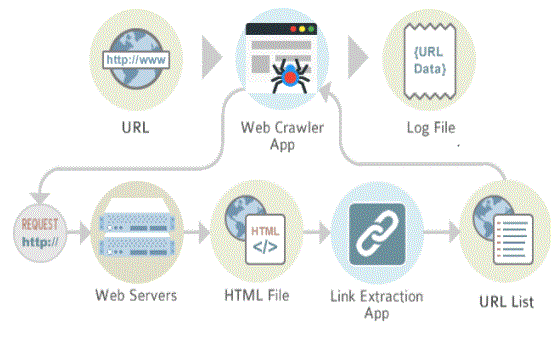
Web Crawler Architecture:
The searcher shouldn’t solely have an honest travel strategy, as noted in previous sections, however ought to even have a lot of advanced structures. While it’s simple to make a slow program that downloads a couple of pages per second in an exceedingly short amount of your time, building a extremely economical program which will transfer many countless pages in an exceedingly few weeks presents variety of challenges to system style, I / O and network performance, sturdiness and management.

Learn Advanced Websense Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch DetailsWeb searchers are a central part of search engines, and details regarding their algorithms and properties are unbroken as a business secret. Once program styles are printed, there’s usually a severe shortage of knowledge that stops others from reproducing the work. There’s additionally the priority of “search engine spam”, that prevents major search engines from publishing their normal algorithms.
Web Crawler Security:
While most website owners prefer to have their pages indexed as widely as possible in order to have a strong presence in search engines, web clarity can have unintended consequences and cause damage or data breaches if the search engine identifies services that should not be public. available, or pages that display.
Subject: Google robberies.
In addition to the webmasters’ common security system, website owners can reduce their exposure to opportunistic traffic by allowing search engines only to target public sections of their websites (via robots.txt) and explicitly prevent them from identifying marketing features (login pages, private pages, etc.).

- The internet is consistently dynamic and growing. As a result of it’s not possible to grasp what percentage websites there are on the net, internet crawler bots begin with interest, or a listing of famed URLs. They crawl websites to those URLs 1st. As they crawl through those websites, they’ll realise links to different URLs, and that they will add those to the list of pages to crawl next.
- Given the massive range of websites on the net that may be targeted for search, this method could also be nearly permanent. However, an internet browser can follow certain policies that build it additional selectiveness concerning that pages to crawl, the way to crawl them, and the way typically they need to crawl to review content reviews.
- Relevant connexion of every internet page: Most internet search engines don’t crawl everywhere the net and aren’t targeted; instead they decide that pages to crawl 1st supported the quantity of pages that link to it page, the quantity of tourists that the location receives, and different factors that indicate that the page could contain necessary info.
- The idea is that a webpage quoted by several different websites which receives a great deal of tourists could contain high-quality, authoritative info, thus it’s vital that the program lists it – even as a library would possibly do. make sure to stay a pile of copies of the foremost wide scan book.
- Re-webpage: website is consistently being updated, deleted, or touched to new locations. internet searchers can often have to be compelled to come back to the pages to confirm that the most recent version of the content is displayed.
- Robots.txt Requirements: internet searchers additionally verify that pages to crawl supported the robots.txt protocol (also called the robots unleash protocol). Before processing an internet page, they’ll rummage around for a robots.txt file hosted by that internet server. A robots.txt file could be a computer file that specifies the foundations for any bots accessing a hosted web site or application. These rules outline what larva pages will crawl, and what links they will follow. For instance, scrutinise the Cloudflare.com robots.txt file.
- All of those options have a special weight inside every program algorithm that hinges on their spider bots. internet searchers from totally different search engines can behave otherwise, though the final word goal is that the same: downloading and classification content on websites.
How do Web Crawlers work?
- The web, or a minimum of a part of it, is additionally referred to as the globe Wide internet – that is wherever the “www” section of most web site URLs comes from. It had been natural to decide bots within the computer program “spiders,” as a result of them crawling everywhere on the net, even as real spiders crawl on the internet.
- That depends on the property of the net, and depends on the quantity of options. Internet searchers would like server resources to spot content – they create requests the server must reply to, like a user visiting a web site or different bots accessing a web site. Considering the number of content on every page or the quantity of pages on the location, it should be best for the web site operator to not permit frequent search queries, as listing will tax the server, increase information, measure prices, or both.
- Also, developers or firms might not need different websites to be accessed unless the user has been given a page link (without inserting the page behind the paywall or login). One example of such a scenario for firms is once they produce a fanatical prediction page for a promoting campaign, however they do not need anyone United Nations agency isn’t targeted by the campaign to access the page. this fashion they’ll organize the messages properly or accurately live the performance of the page. In such cases the business could add a “no index” to the prediction page, and will not see in computer program results. they’ll conjointly add a “do not allow” tag to a page or a robots.txt file, and also the computer program spiders won’t crawl the least bit.
- Website homeowners might not need internet crawler bots to crawl half or all of their sites for a spread of reasons yet. For instance, a web site that provides users the facility to look among the location might want to dam the search results pages, as this is often not useful for many users. Some auto-generated pages are a unit helpful to just one user or a number of users ought to even be blocked.
Why are Web Crawlers called ‘spiders’?
- World Wide Web Worm was a search engine used to create a simple index of document titles and URLs. The index can be searched using the grep Unix command.
- Yahoo! Slurp was the name of Yahoo! Search. Yahoo! has a contract with Microsoft to use Bingbot instead.
- In-house web search
- Applebot is Apple’s web browser. Supports Siri and other products.
- Bingbot is the name of Microsoft’s Bing webcrawler. Replaces Msnbot.
- Baiduspider is a Baidu web search.
- Googlebot is described in some detail, but the reference is to the original version of its architecture, which was written in C ++ and Python. The searcher is integrated with the indexing process, because text sorting is done for full text identification and URL extracting. There is a URL server that sends lists of URLs that will be downloaded by a few clearing processes. During the analysis, the recovered URLs were transferred to a URL server that checked the URL before detection. If not, the URL is added to the URL Server URL.
- WebCrawler was used to create the first publicly available text index for the sub-web set. It is based on lib-WWW download pages, and other system analysis and ordering URLs to test the initial scope of the Web graph. It also installed a real-time search that followed links based on anchor text similarity to a given query.
- WebFountain is a distributed search engine, similar to Mercator but written in C ++.
- Xenon is a web browser used by government tax authorities to detect fraud.
- Commercial web search engines.
- GNU Wget is a command line-based search engine labelled C and issued under the GPL. It is often used to showcase Web and FTP sites.
- GRUB was a widely distributed open source search tool used by Wikia Search to crawl the web.
- Heritrix is an archive of quality archive, designed to archive snapshots of time for a large part of the Web. Written in Java.
List of Web Crawlers:
More info: Search engine software list
The following is a list of published crawler properties for general purpose crawlers (other than web-based search engines), with a brief description that includes names given to different sections and outstanding features:
History web search history
The following web search is available, at a price :
SortSite – a web analytics search engine, available for Windows and Mac OS.
Swiftbot – Swiftype web browser, available as software as a service.
Open source search
- This can be of nice profit particularly to those that face stiff competition in their trade. Sun Tzu, a typical Chinese military contriver, prompts “If you recognize your enemies and yourself, you’ll ne’er be defeated” To achieve your trade, you wish to check your competitors. you wish to search out the spirit of what works for them. Their costs, promoting methods, and everything.
- With internet Crawlers, you’ll mechanically extract information from varied competitive websites with no trouble. This provides you and your workers the chance to avoid wasting time for alternative productive activities. The actual fact that information is mechanically extracted offers you the advantage of accessing giant volume information.
- If you’ve got a sales team, product management team, or perhaps a promoting team required to judge new merchandise / competitors’ services. Then you must take into account internet Crawlers. It conjointly provides a chance to review your costs and make certain they’re competitive. With extracted information you discover on varied websites. You get to search out promoting methods for your competitors.
Benefits of Web Crawler:
Now that you just have a whole understanding of the which means of sites. however it works and its importance. It’s necessary to debate a number of the advantages of internet crawlers. several of the subsequent ares particularly useful for those within the competitive trade.
Keeping Tables for Competitors
Industrial Trend pursuit
Staying au fait trends in your trade is crucial to valuation and responsibleness. It conjointly proves to the general public that your company is promising. Business professionals perceive the importance of obtaining the newest developments in their trade. Despite this state of your business, take the time to remain advised. By accessing an oversized quantity of knowledge from varied sites. Internet Crawlers offer you the chance to trace trends in your trade.
The Leading Generation
Talking regarding the advantages of internet crawlers isn’t complete while not talking regarding lead generation. If you run a business supported data printed on your competitors’ websites to come up with extra revenue. Then you must take into account internet Crawlers. It offers you instant access to the current data. therefore you’ve had a positive impact on your financial gain.
Competitive costs
For some reason, you will have issue setting costs for your merchandise or services. it’s even more durable once you have an issue career for the costs of multiple merchandise. however with internet Crawler, you’ll simply reach the costs of your competitors. providing you with the chance to line competitive costs for your shoppers.
Targeted listing
Web Crawlers enables you to return up with an inventory of firms or individual contacts for all kinds of functions. With Crawler, you’ll access data like phone numbers, address, email address, and more. it’s going to conjointly establish an inventory of targeted websites that give an inventory of relevant firms.
Provider costs and convenience
If you’re on a business list that features purchases from varied suppliers. you’re expected to go to your providers’ website frequently to match and compare convenience, prices, and more. With internet Crawler, you’ll simply access and compare this data while not having to go to their varied websites. This is able to not solely prevent stress and time. it’ll conjointly make sure that you are not missing out on the nice deals.
Conclusion:
A web searcher is a way for search engines and other users to always ensure that their database is up to date. Web searchers are a central part of search engines, and information on their algorithms and properties is kept as a business secret.
If you have a well-designed site that provides easy access to search engines to crawl your site data regularly. It allows your content to be indexed, thus establishing an effective SEO strategy. In addition, Ensuring that your website is easy to use, and easy to use, is guaranteed to benefit your SEO!




