
Last updated on 26th Apr 2025| 9513
- Introduction to Classification in Data Mining
- Difference Between Classification and Clustering
- Supervised Learning in Classification
- Decision Trees for Classification
- Random Forest for Classification
- Neural Networks and Deep Learning in Classification
- Challenges in Classification and How to Overcome Them
- Conclusion
Introduction to Classification in Data Mining
Classification is a fundamental technique in data mining used to categorize data into predefined classes or groups. As a form of supervised learning, classification involves training a model using labeled datasets where the outcomes or classes are already known so it can accurately predict the class of new, unseen data. The process begins with the model learning patterns and relationships in the training data, which it then applies to classify future inputs. This technique is widely applied across various domains. In pattern recognition, classification helps identify objects, text, or images based on learned features a fundamental concept covered in Data Science Training to develop accurate and efficient models. In fraud detection, it distinguishes between legitimate and fraudulent transactions. In spam filtering, emails are automatically categorized as spam or not spam. Similarly, in customer segmentation, classification helps group customers based on behavior or preferences, allowing for targeted marketing strategies. Common classification algorithms include decision trees, logistic regression, support vector machines (SVM), and random forests. These models provide valuable insights by analyzing historical data to detect trends and make accurate predictions. By enabling data-driven decision-making, classification enhances operational efficiency and supports strategic planning in organizations.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Course Training To Gain Insights From Our Experts!
Difference Between Classification and Clustering
While both classification and clustering are essential techniques in data mining, they serve distinct purposes and operate under different learning paradigms. Classification is a supervised learning approach that relies on labeled data to train a model. Each data point in the training set is associated with a predefined class or category. The primary objective of classification is to predict the class of new, unseen data based on the patterns learned during training a concept increasingly relevant in Emerging Tech in Civil to Software Engineering, where AI-driven models are transforming traditional engineering workflows. It is widely used in applications like spam detection, disease diagnosis, and customer churn prediction, where accuracy and predefined outcomes are crucial. On the other hand, clustering is an unsupervised learning method that does not require labeled data. Instead, it groups data points into clusters based on inherent similarities or patterns, without prior knowledge of class labels.
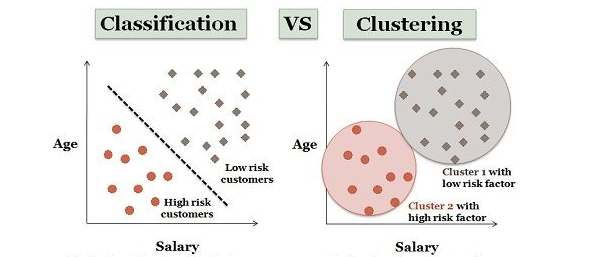
Clustering is particularly useful for exploratory data analysis, market segmentation, anomaly detection, and uncovering hidden structures in large datasets. In summary, while classification is focused on accurate prediction using existing labels, clustering is aimed at discovering meaningful groupings in unstructured or unlabeled data. Both play vital roles in extracting insights and supporting informed decision-making in data-driven environments.
Supervised Learning in Classification
- Definition: Supervised learning is a machine learning approach where the model is trained on a labeled dataset, meaning each input is paired with the correct output or class.
- Labeled Data: The effectiveness of supervised classification depends heavily on high-quality labeled data, where each example is accurately tagged with the correct class.
- Training Process: The model learns the relationship between features (inputs) and labels (outputs) by minimizing the error between predicted and actual labels during training.
- Evaluation Metrics: Model performance is typically evaluated using accuracy, precision, recall, F1-score, and confusion matrix on a test dataset.
- Applications: Supervised classification aids tasks like spam filtering and can Boost Your SEO Strategy with AI Automation through smarter content targeting.
- Goal: The ultimate aim is to build a model that generalizes well to new data, making accurate predictions based on learned patterns.
- Common Algorithms: Popular classification algorithms in supervised learning include Decision Trees, Support Vector Machines (SVM), Logistic Regression, k-Nearest Neighbors (k-NN), and Random Forests.
- Role in Classification: In classification tasks, supervised learning is used to train models that can categorize new, unseen data into predefined classes based on the patterns learned from the training data.
- Overfitting Risk: They are prone to overfitting, especially when the tree becomes too complex or is trained on noisy data, capturing patterns that don’t generalize well.
- Pruning Techniques: To prevent overfitting, pruning techniques (like cost complexity pruning or reduced error pruning) are used to remove unnecessary branches and simplify the model.
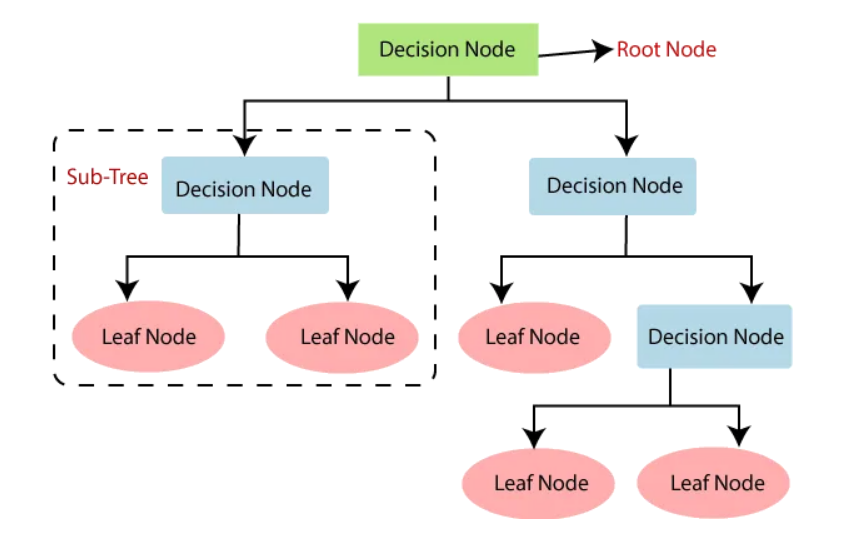
- Hierarchical Structure: The model forms a decision tree using feature-based splits—an approach often used in Quantitative Research Methods for structured analysis.
- Simplicity and Interpretability: Decision trees are widely used because they are easy to understand and visualize, making them ideal for explaining model decisions to non-technical stakeholders.
- Feature Importance: Decision trees can rank features by importance, helping analysts understand which variables most influence predictions.
- Handling Mixed Data: They can handle both numerical and categorical data without requiring complex preprocessing or normalization.
- Scalability and Speed: Decision trees are computationally efficient and scale well to large datasets, making them practical for real-time decision-making tasks.
- Layered Architecture: Artificial Neural Networks (ANNs) consist of multiple layers of interconnected nodes (neurons) that process data by passing inputs through weighted connections and activation functions.
- Deep Learning Capabilities: Deep neural networks, which include multiple hidden layers, are capable of learning hierarchical features and excel at recognizing complex patterns in large and unstructured data.
- Real-World Applications: ANNs power tasks like NLP and image recognition often boosted by a Vector Database for faster, smarter data retrieval.
- Resource Requirements: Despite their impressive performance, deep learning models require large labeled datasets and significant computational resources, including GPUs, for effective training.
- Backpropagation Algorithm: Training ANNs involves backpropagation, an algorithm that adjusts the weights based on the error between predicted and actual output, improving model accuracy over time.
- Overfitting Challenge: Deep networks are prone to overfitting, especially with limited data, which is why techniques like dropout, regularization, and data augmentation are often used to enhance generalization.
To Earn Your Data Science Certification, Gain Insights From Leading Data Science Experts And Advance Your Career With ACTE’s Data Science Course Training Today!
Decision Trees for Classification

Random Forest for Classification
Random Forest is a powerful ensemble learning technique used in classification and regression tasks. It works by combining the predictions of multiple decision trees, each trained on different subsets of the data using a method called bagging (bootstrap aggregating). During prediction, each tree in the forest makes an independent decision, and the final class is determined by the majority vote across all trees. This ensemble approach helps to reduce overfitting, a common issue in single decision trees, by averaging out biases and minimizing variance, resulting in improved model stability and generalization a core technique emphasized in Data Science Training for building reliable predictive models. Random Forest also introduces randomness by selecting a random subset of features at each split, further enhancing model diversity and performance. This technique is highly effective for handling large datasets with high dimensionality and is capable of maintaining accuracy even when a large portion of the data is missing. Thanks to its robustness, accuracy, and ease of use, Random Forest is widely adopted in real-world applications such as financial fraud detection, healthcare diagnosis, customer churn prediction, and credit risk assessment. Its interpretability and ability to rank feature importance also make it a valuable tool in data-driven decision-making.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Neural Networks and Deep Learning in Classification
Challenges in Classification and How to Overcome Them
Classification algorithms, while powerful, face several key challenges that can impact their performance and reliability. One major issue is overfitting, where a model performs exceptionally well on training data but fails to generalize to new, unseen data. This can be mitigated using techniques like regularization and cross-validation, which help ensure the model captures underlying patterns rather than noise. Another common challenge is class imbalance, where one class significantly outweighs others, leading the model to bias its predictions toward the dominant class a problem that can be highlighted and analyzed through Data Visualization to better understand and address model performance. Solutions include resampling techniques (oversampling the minority class or undersampling the majority) or applying cost-sensitive learning methods. Dimensionality issues also arise, especially with high-dimensional datasets that can lead to overfitting and computational inefficiency. In such cases, feature selection or dimensionality reduction techniques like Principal Component Analysis (PCA) are useful for simplifying data without losing critical information. Additionally, noise and outliers in the dataset can distort model learning and reduce accuracy. Preprocessing steps such as data cleaning and outlier detection can improve model robustness. By incorporating robust validation techniques and hyperparameter optimization, organizations can significantly enhance classification model performance and reliability.
Want to Learn About Data Science? Explore Our Data Science Interview Questions & Answer Featuring the Most Frequently Asked Questions in Job Interviews.
Conclusion
Classification is a powerful data mining technique that categorizes data into predefined classes, making it a crucial tool for prediction and decision-making. With algorithms like decision trees, Naïve Bayes, Support Vector Machines (SVM), and neural networks, businesses can uncover valuable insights from complex datasets. These models help in tasks such as customer segmentation, fraud detection, and sentiment analysis. However, challenges like overfitting, where the model performs well on training data but poorly on new data, and class imbalance, where one class dominates, can affect model accuracy issues that are thoroughly addressed in Data Science Training to improve model robustness and performance. To mitigate these issues, best practices such as cross-validation, regularization, resampling techniques, and feature selection should be applied. The ongoing advancements in AI and deep learning are further enhancing classification accuracy, enabling more precise predictions and expanding the potential applications across industries like healthcare, finance, and marketing. As these technologies evolve, the scope and effectiveness of classification models will continue to grow, driving innovation and smarter decision-making.




