
Last updated on 18th Jun 2025| 10030
- Introduction to Cloud Computing
- Role of Data Science
- Cloud Platforms
- Benefits of Cloud for Data Science
- Data Storage and Access
- Scalability and Processing Power
- ML Model Deployment in Cloud
- Real-Time Data Processing
Introduction to Cloud Computing
Cloud computing is a transformative technology that allows individuals and organizations to access and manage computing resources such as servers, storage, databases, networking, software, and analytics over the internet instead of relying on local hardware or infrastructure. By leveraging cloud services, users can quickly scale resources up or down based on demand, improving flexibility and reducing costs associated with maintaining physical hardware. Major cloud service providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform offer a wide range of on-demand services, enabling businesses to innovate faster without the burden of managing complex IT environments. One of the key advantages of cloud computing is its pay-as-you-go pricing model, which means organizations only pay for the resources they use, avoiding upfront capital expenses an approach especially beneficial for those undergoing Data Science Training. Cloud computing supports various deployment models, including public cloud, private cloud, and hybrid cloud, each offering different levels of control, security, and customization to meet diverse business needs. It also enables remote access, allowing employees and teams to work collaboratively from anywhere, fostering greater productivity. Cloud computing has revolutionized industries by providing a foundation for emerging technologies such as big data analytics, artificial intelligence (AI), machine learning, and the Internet of Things (IoT). These technologies require vast amounts of computational power and storage, which the cloud readily provides. Overall, cloud computing offers scalability, agility, cost-efficiency, and accessibility, making it a cornerstone of modern IT strategies and digital transformation initiatives worldwide.
Are You Interested in Learning More About Data Science? Sign Up For Our Data Science Course Training Today!
Role of Data Science
Data science plays a pivotal role in transforming raw data into valuable insights that drive strategic decision-making and innovation across various industries. By applying scientific methods, algorithms, and advanced analytical techniques, data science helps organizations uncover hidden patterns, predict future trends, and optimize processes. At its core, data science combines statistics, computer science, and domain expertise to analyze complex and large datasets often referred to as big data that traditional data analysis methods cannot handle effectively. The role of data science extends beyond simple data interpretation; it involves building predictive models and machine learning algorithms that can automate decision-making and personalize customer experiences, often using Top Python Libraries For Data Science. For example, in retail, data science enables personalized marketing by analyzing customer behavior and purchasing patterns. In healthcare, it supports early diagnosis and treatment planning by processing patient data and medical images. In finance, data science is used for fraud detection, risk assessment, and algorithmic trading, enhancing security and efficiency. Data scientists also collaborate closely with business leaders to translate analytical findings into actionable business strategies. They design experiments, test hypotheses, and evaluate outcomes to continuously improve products and services. Furthermore, data science contributes to innovation by enabling the development of new technologies such as artificial intelligence, natural language processing, and autonomous systems.
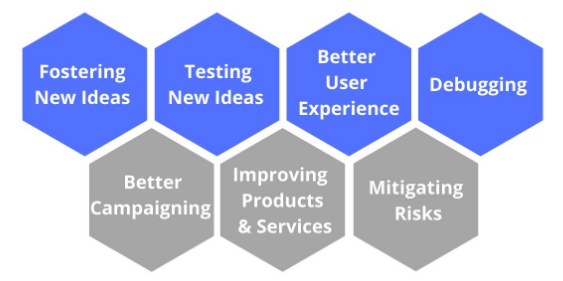
Overall, the role of data science is critical in harnessing the power of data to solve real-world problems, optimize operations, and create competitive advantages. As data generation continues to grow exponentially, the importance of data science in shaping the future of businesses, governments, and society at large will only increase.
Cloud Platforms
- Definition: Cloud platforms provide on-demand access to computing resources such as servers, storage, databases, networking, software, and analytics over the internet. They eliminate the need for physical hardware and allow users to scale resources quickly.
- Types of Services: Cloud platforms offer various service models, including Infrastructure as a Service (IaaS), which provides virtualized hardware; Platform as a Service (PaaS), which offers development environments; and Software as a Service (SaaS), which delivers software applications over the web.
- Major Providers: Leading cloud platforms include Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), IBM Cloud, and Oracle Cloud. Each offers a wide range of services tailored to different business needs, including tools for implementing algorithms like What is Logistic Regression.
- Scalability: One of the biggest advantages of cloud platforms is scalability. Businesses can easily adjust computing power and storage based on demand, avoiding over-provisioning and reducing costs.
- Security: Cloud providers invest heavily in security measures, including data encryption, identity management, and compliance certifications. However, organizations still need to implement best practices to protect their data.
- Global Accessibility: Cloud platforms offer global data centers, enabling organizations to deploy applications closer to end-users for improved performance and availability.
- Integration with Emerging Technologies: Cloud platforms support integration with artificial intelligence, machine learning, big data analytics, and Internet of Things (IoT) services, accelerating innovation and digital transformation.
- Scalability: Cloud platforms provide virtually unlimited computing power and storage that can scale up or down based on the needs of data science projects, enabling efficient handling of large datasets and complex models.
- Cost Efficiency: By using cloud resources on a pay-as-you-go basis, data scientists avoid the high upfront costs of purchasing and maintaining physical hardware, reducing overall expenses.
- Collaboration: Cloud environments enable multiple data scientists and stakeholders to work together seamlessly from different locations, facilitating real-time collaboration on data, code, and models—an essential component of effective Data Science Training.
- Access to Advanced Tools: Cloud providers offer integrated data science tools and frameworks such as Jupyter notebooks, machine learning libraries, and automated model training services, streamlining the development process.
- Faster Deployment: Cloud platforms accelerate the deployment of data science models into production, allowing organizations to quickly operationalize insights and derive business value.
- Data Integration: Cloud services can connect easily with various data sources, including databases, APIs, and streaming data, providing a centralized platform for data ingestion and management.
- Security and Compliance: Leading cloud providers implement robust security measures and compliance certifications, ensuring sensitive data is protected and regulatory requirements are met.
- Definition of Scalability: Scalability refers to a system’s ability to handle increased workloads by adding resources without compromising performance. It can be vertical (adding more power to existing machines) or horizontal (adding more machines).
- Processing Power Explained: Processing power is the capability of a computer system to perform calculations and run applications quickly. It depends on factors like CPU speed, number of cores, and memory capacity.
- Importance for Big Data: Handling large datasets requires high processing power and scalable architectures to efficiently process and analyze data within reasonable timeframes, where tools like Python Generators can help optimize memory usage and performance.
- Cloud Scalability: Cloud platforms offer dynamic scalability, allowing users to automatically increase or decrease processing resources based on demand, which is essential for unpredictable workloads.
- Cost Efficiency: Scalability helps optimize costs by ensuring that resources are used only when needed, avoiding wasteful over-provisioning of hardware.
- Performance Maintenance: Scalable systems maintain consistent performance levels as data volume or user requests increase, ensuring smooth and uninterrupted service.
- Application in Machine Learning: Machine learning algorithms require substantial processing power for training models. Scalability enables parallel processing and faster experimentation, accelerating model development.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Course Training To Gain Insights From Our Experts!
Benefits of Cloud for Data Science
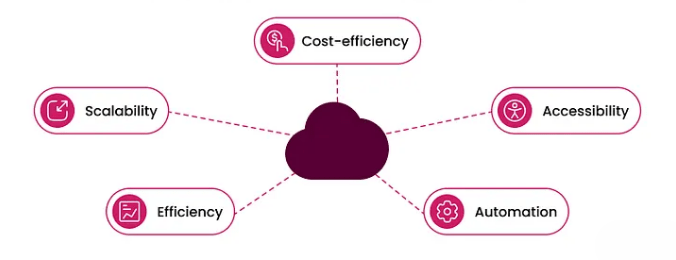

Data Storage and Access
Data storage and access are essential components of modern information systems, allowing organizations to securely save, manage, and retrieve large amounts of data efficiently. With the rapid increase of digital information, including transaction records, multimedia content, and sensor data, effective storage solutions have become increasingly important. Traditional storage relied on physical hardware such as hard drives and onsite servers, but the emergence of cloud computing has transformed how data is stored and accessed by providing scalable, flexible, and cost-effective alternatives. There are three main types of data storage: on-premises storage, cloud storage, and hybrid models that combine both approaches. On-premises storage gives organizations direct control over their data and infrastructure, which is crucial for managing sensitive information that requires strict security and regulatory compliance, especially when choosing between tools like Python vs R vs SAS. Cloud storage, offered by providers like Amazon Web Services, Microsoft Azure, and Google Cloud, allows data to be stored remotely and accessed via the internet from any location. This model supports dynamic scaling so businesses can adjust storage capacity based on current needs, avoiding large upfront expenses. Efficient data access relies on database management systems and retrieval technologies. Structured data is usually stored in relational databases accessed with SQL queries, while unstructured data such as images or videos may be stored in NoSQL databases or data lakes. Fast data retrieval is critical for real-time analytics, decision-making, and application performance. Techniques like caching, indexing, and data partitioning help improve access speeds and overall system efficiency. In summary, modern data storage and access solutions enable organizations to manage increasing data volumes, maintain availability, and ensure security, which supports data-driven operations and analytics.
Are You Considering Pursuing a Master’s Degree in Data Science? Enroll in the Data Science Masters Course Today!
Scalability and Processing Power
ML Model Deployment in Cloud
Machine Learning (ML) model deployment in the cloud has become a popular approach for making predictive models accessible, scalable, and efficient. Once an ML model is trained and validated, deploying it to a cloud environment allows organizations to serve real-time predictions, integrate with applications, and handle varying user demands without worrying about infrastructure management. Cloud platforms such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform offer specialized services for ML deployment, making it easier for data scientists and developers to operationalize models. Deploying an ML model in the cloud involves several key steps. First, the model is packaged, often using containerization tools like Docker, to create a portable and consistent runtime environment demonstrating Why Data Science Matters & How It Powers Business Value. Next, the model is uploaded to the cloud service, where it can be deployed using managed services like AWS SageMaker, Azure Machine Learning, or Google AI Platform. These services provide APIs that enable applications to send data to the model and receive predictions in real time. Cloud deployment also offers scalability through auto-scaling features, which automatically adjust computational resources based on demand, ensuring reliable performance even during traffic spikes. In addition to scalability, cloud deployment improves model monitoring and maintenance. Built-in tools track model performance, detect data drift, and manage version control, enabling continuous improvement and timely updates. Security features in the cloud protect sensitive data during transmission and storage. Overall, deploying ML models in the cloud simplifies operational challenges, accelerates time-to-market, and allows organizations to harness the power of machine learning with greater flexibility and cost efficiency.
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
Real-Time Data Processing
Real-time data processing refers to the ability to ingest, analyze, and respond to data immediately as it is generated. Unlike traditional batch processing, which collects and processes data in large groups at scheduled intervals, real-time processing handles data continuously and delivers insights or actions without delay. This capability is crucial for applications that require instant decision-making, such as fraud detection, stock trading, customer support, and Internet of Things (IoT) device monitoring. To enable real-time data processing, organizations use specialized technologies and frameworks. Stream processing platforms like Apache Kafka, Apache Flink, and Apache Spark Streaming allow data to flow through pipelines, where it can be filtered, transformed, and analyzed on the fly. These platforms support handling massive volumes of data with low latency, ensuring that insights are available as events occur a capability often emphasized during Data Science Training. Real-time analytics can also be integrated with machine learning models to predict outcomes and automate responses instantly. Cloud providers like AWS Kinesis, Google Cloud Dataflow, and Azure Stream Analytics offer managed real-time processing services, simplifying infrastructure management and scaling. These tools enable businesses to build flexible pipelines that process data from multiple sources, such as social media feeds, sensors, or transaction logs. The benefits of real-time data processing include improved customer experience, faster response to operational issues, and enhanced decision-making capabilities. For example, e-commerce platforms can use real-time analytics to recommend products based on current browsing behavior, while logistics companies can optimize delivery routes dynamically based on traffic data. In summary, real-time data processing empowers organizations to act immediately on fresh data, creating competitive advantages in speed, accuracy, and responsiveness.




