
Last updated on 22nd Apr 2025| 10472
- Introduction to String Searching Algorithms
- Overview of Boyer-Moore Algorithm
- How Boyer-Moore Algorithm Works
- Bad Character Heuristic
- Good Suffix Heuristic
- Time Complexity of Boyer-Moore Algorithm
- Comparison with Other String Matching Algorithms
- Implementing the Boyer-Moore Algorithm in Python
- Real-World Applications of Boyer-Moore Algorithm
- Advantages and Limitations of Boyer-Moore
- Optimizing Boyer-Moore for Large Datasets
- Common Mistakes While Implementing Boyer-Moore
Introduction to String Searching Algorithms
String searching is a fundamental problem in computer science and has applications across various fields, including text editing, data mining, bioinformatics, and information retrieval. String searching algorithms aim to find all occurrences of a pattern (substring) within a larger text (string). DNA sequence algorithms are crucial when efficient searching is required, such as searching for a keyword in a large document or finding a subsequence in a DNA sequence. Over the years, many string searching algorithms have been developed to address efficiency and scalability challenges, given that large-scale Data Science Course Training are standard in modern applications. Some of the most well-known algorithms include brute-force search, Knuth-Morris-Pratt (KMP), Rabin-Karp, and Boyer-Moore. Among these, the Boyer-Moore algorithm is one of the most efficient and widely used in practice, particularly for large-scale text searching. In this article, we will explore the Boyer-Moore algorithm, how it works, its advantages and limitations, and its real-world applications.
Overview of Boyer-Moore Algorithm
The Boyer-Moore algorithm was developed by Robert S. Boyer and J Strother Moore in 1977. It is one of the most efficient string-searching algorithms, particularly for searching patterns in large text. The algorithm is based on skipping over sections of the text that cannot match the pattern, thereby improving performance compared to other algorithms like the brute-force method. Boyer-Moore employs two key heuristics to speed up the search: the Bad Character Heuristic and the Good Suffix Heuristic. Dispersion in Statistics heuristics help the algorithm make intelligent decisions about where to skip in the text rather than examining every character in the text sequentially. The Boyer-Moore algorithm works by aligning the pattern to the beginning of the text and comparing the pattern from right to left with the text. If a mismatch occurs, the algorithm uses the heuristics to determine the next best position to start the comparison. This process repeats until a match is found or the entire text is scanned.
Become a Data Science expert by enrolling in this Data Science Online Course today.
How Boyer-Moore Algorithm Works
The Boyer-Moore algorithm examines the pattern from right to left rather than the traditional left-to-right approach used in other string-matching algorithms. The algorithm compares the pattern’s characters with the corresponding characters in the text, starting from the rightmost character of the pattern. This reverse approach allows the Boyer-Moore algorithm to make significant jumps in the text, skipping over sections that cannot possibly match the pattern.
The basic idea of the algorithm is as follows:
- Align the pattern: Start by aligning the pattern to the beginning of the text. Compare characters: Compare the pattern characters from right to left with the corresponding characters in the text.
- Handle mismatches: If a mismatch occurs, use the Bad Character Heuristic or the good suffix table to Simple Linear Regression how much to shift the pattern.
- Shift the pattern: Shift the pattern based on the heuristics and repeat the process until a match is found or the entire text is scanned.
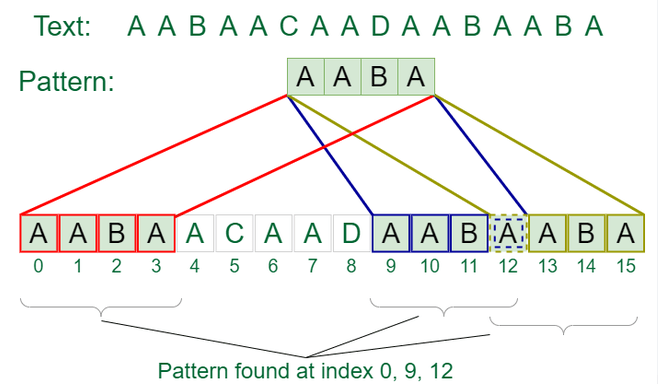
Bad Character Heuristic
The Bad Character Heuristic determines how far the pattern can be shifted when a mismatch occurs. KMP algorithm operates on the assumption that if a mismatch occurs at a particular character in the pattern, then this character cannot appear at the same position in the text. To apply the Bad Character Heuristic, the algorithm looks at the mismatched character in the text and checks the pattern to see if that character exists. If the character does not exist in the pattern, the entire pattern can be shifted past the current position in the text. If the character exists in the pattern, the pattern can be moved to the right so that the mismatched character in the text aligns with its last occurrence.
Good Suffix Heuristic
The Good Suffix Heuristic determines how far the pattern can be shifted based on the characters that have already matched. When a mismatch occurs, the algorithm examines the matched portion of the pattern (the suffix) and tries to align A Web Crawler with another occurrence of the same suffix. If the matched suffix has another occurrence in the pattern, the pattern can be shifted so that this occurrence lines up with the corresponding portion of the text. If no such occurrence exists, the pattern is shifted as much as possible based on the pattern’s structure. Using these two heuristics, the Boyer-Moore algorithm can skip over large portions of the text, making it much faster than other algorithms that examine each text character sequentially.
Advance your Data Science career by joining this Data Science Online Course now.
Time Complexity of Boyer-Moore Algorithm
The time complexity of the Boyer-Moore algorithm depends on several factors, including the length of the pattern (m) and the length of the text (n). In the best case, the time complexity of the Boyer-Moore algorithm is O(n/m), where the algorithm can skip large sections of the text by leveraging the heuristics. This makes the Boyer-Moore algorithm highly efficient, especially for long patterns and significant texts. However, in the worst case, the time complexity can be as high as O(n * m), which occurs when the pattern and text are highly similar and the heuristics do not allow for significant skipping. Despite Data Wrangling , the worst-case scenario is rare, and in most cases, the Boyer-Moore algorithm performs much better than its worst-case time complexity suggests.
Comparison with Other String Matching Algorithms
It is helpful to compare the Boyer-Moore algorithm with other commonly used string-matching algorithms to understand its advantages. Brute-Force Search. The brute-force search algorithm is the most straightforward string-matching algorithm. Python works by examining each character of the text and checking if it matches the first character of the pattern. If a match is found, the algorithm checks the subsequent characters until the entire pattern is matched. The time complexity of the brute-force algorithm is O(n * m), where n is the length of the text and m is the length of the pattern. While simple, the brute-force search is inefficient for significant texts.

Knuth-Morris-Pratt (KMP)
The Knuth-Morris-Pratt (KMP) algorithm improves on the brute-force approach by avoiding unnecessary re-examinations of characters in the text. DNA sequences preprocesses the pattern to create a partial match table Data Science Course Training helps skip characters when a mismatch occurs. The KMP algorithm’s time complexity is O(n + m), which is more efficient than the brute-force approach. However, the KMP algorithm still examines the text left to right, which may be less efficient than Boyer-Moore in some cases.
Rabin-Karp
The Rabin-Karp algorithm uses hashing to find pattern matches in the text. It computes a hash value for the pattern and compares DNA sequences with the hash values of substrings in the text. A direct comparison of the characters is performed if a match is found. The time complexity of the Rabin-Karp algorithm is O(n + m) on average, but it can degrade to O(n * m) in the worst case due to hash collisions. Compared to these algorithms, the Boyer-Moore algorithm often outperforms them, especially when the pattern is relatively long, and the text is significant due to its ability to skip text sections using its heuristics.
Ready to excel in Data Science? Enroll in ACTE’s Data Science Master Program Training Course and begin your journey today!
Implementing the Boyer-Moore Algorithm in Python
- Purpose: It is an efficient string matching algorithm designed to search for a pattern (substring) within a text (string).
- Efficiency: Boyer-Moore improves searching speed by skipping sections of the text, using information gathered during the search process. Most Popular Python Toolkit performs better than brute-force algorithms, especially for longer patterns.
- Core Idea: The algorithm works by matching the pattern from right to left (in contrast to many algorithms that match from left to right).
- Bad Character Heuristic: If a mismatch occurs, the algorithm shifts the pattern based on the character in the text, which helps avoid unnecessary comparisons.
- Good Suffix Heuristic: If a part of the pattern matches, the pattern is shifted by the length of the matched part to avoid redundant checks.
Real-World Applications of Boyer-Moore Algorithm
The Boyer-Moore algorithm has several practical applications across a variety of fields:
- Text Editing: Text editors use the Boyer-Moore algorithm to efficiently search for keywords or substrings in large documents.
- Search Engines: Search engines utilize string-matching algorithms like Boyer-Moore to search through large volumes of indexed text for relevant results.
- Bioinformatics: In bioinformatics, the Boyer-Moore algorithm finds specific patterns or motifs in large DNA sequences.
- Data Mining: The Boyer-Moore algorithm can be applied to efficiently search for patterns in Data Normalization , such as logs or databases.
Are you getting ready for your Data Science interview? Check out our blog on Data Science Interview Questions and Answers!
Advantages and Limitations of Boyer-Moore
Advantages:
- Efficiency: The Boyer-Moore algorithm is highly efficient, especially for significant texts and long patterns. It can skip over large text sections faster than other algorithms, such as brute force or KMP algorithm.
- Flexible Heuristics: The Bad Character and Good Suffix heuristics allow the algorithm to make intelligent decisions about how far to shift the pattern, reducing unnecessary comparisons.
- Worst-Case Performance: In rare cases, the Boyer-Moore algorithm can perform poorly, with a worst-case time complexity of O(n * m).
- Preprocessing Time: Preprocessing the pattern to create the lousy character table and good suffix table can take time, though the benefits generally outweigh this during the search phase.
Limitations:
Optimizing Boyer-Moore for Large Datasets
One approach to optimizing the Boyer-Moore algorithm for large datasets is to preprocess the pattern in advance so that the search phrase is as fast as possible. Additionally, the implementation can be further optimized by reducing the space complexity of the heuristics and Data Science Course Training the search process in multi-core processors.
Common Mistakes While Implementing Boyer-Moore
- Incorrect Shift Calculation: One common mistake is miscalculating the shift when a mismatch occurs. Python essential to apply the correct heuristic to shift the pattern efficiently.
- Handling Edge Cases: Ensure that edge cases such as empty text or patterns are correctly handled.
- Memory Management: The Boyer-Moore algorithm requires additional space to store the evil character and good suffix tables. Care should be taken to manage memory for large patterns efficiently.




