
Last updated on 18th Jun 2025| 9731
- Introduction to Data Science Skill sets
- Statistical and Mathematical Proficiency
- Programming Languages (Python, R, SQL)
- Machine Learning & Deep Learning
- Data Wrangling and Cleaning
- Data Visualization and Storytelling
- Big Data Tools (Spark, Hadoop, etc.)
- Cloud Computing Skills (AWS, Azure)
Introduction to Data Science Skill sets
Data science is a dynamic and interdisciplinary field that requires a diverse set of skills to analyze, interpret, and derive insights from data. At the heart of data science lies a strong foundation in mathematics and statistics, which is essential for understanding patterns, trends, and relationships within datasets. Equally important are programming skills particularly in languages like Python and R which enable data scientists to clean, manipulate, and analyze data efficiently. Knowledge of databases and proficiency in SQL, often emphasized in Data Science training are also critical for retrieving and managing large volumes of structured data. Data visualization tools and libraries, such as Tableau, Matplotlib, or Seaborn, are key to communicating complex findings in a clear and compelling way. In addition, familiarity with machine learning algorithms allows practitioners to build predictive models and automate decision-making processes. However, technical abilities alone are not enough; effective data scientists must also possess strong problem-solving skills, business acumen, and the ability to communicate insights to both technical and non-technical audiences. Collaboration and continuous learning are vital, given the rapid evolution of tools and techniques in the field. Together, these skillsets enable professionals to turn raw data into actionable knowledge that drives innovation and strategic decision-making across industries.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
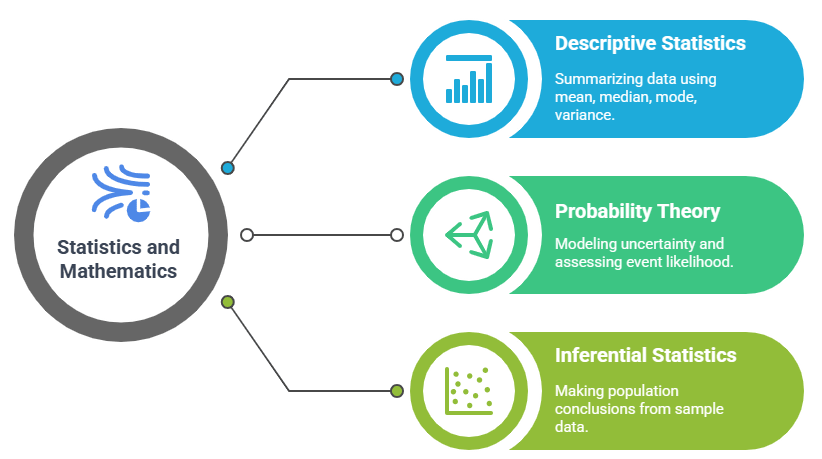
Statistical and Mathematical Proficiency
- Descriptive Statistics: Understanding measures such as mean, median, mode, variance, and standard deviation to summarize and describe data effectively.
- Probability Theory: What Does a Data Scientist Do and how they work often involves applying probability concepts to assess the likelihood of events and model uncertainty in data.
- Inferential Statistics: Using techniques like hypothesis testing, confidence intervals, and p-values to make conclusions about populations based on sample data.
A strong foundation in statistics and mathematics is essential for any data science professional, as these disciplines form the backbone of data analysis, model building, and result interpretation. They enable data scientists to understand data distributions, make accurate predictions, and assess the validity of their findings. Proficiency in these areas ensures more informed and precise decision-making.
- Linear Algebra: Essential for understanding how data is represented and manipulated in machine learning models, especially in algorithms like PCA or neural networks.
- Calculus: Key for optimizing machine learning algorithms, especially in understanding gradients and cost functions used in training models.
- Statistical Modeling: Building and evaluating models such as linear regression, logistic regression, and time series forecasting to make data-driven predictions.
Programming Languages (Python, R, SQL)
Proficiency in programming languages is a core skill for data scientists, enabling them to manipulate data, perform analysis, and build models efficiently. Python, R, and SQL are among the most widely used languages in the field. Python is favored for its simplicity, readability, and a vast ecosystem of libraries such as Pandas, NumPy, Scikit-learn, and Matplotlib, which support data manipulation, statistical analysis, machine learning, and visualization skills that are essential when Earning Your Data Science Certification. R is especially strong in statistical computing and data visualization, with packages like ggplot2, dplyr, and caret that make it a powerful tool for exploratory data analysis and academic research. SQL, or Structured Query Language, is essential for accessing, querying, and managing data stored in relational databases. It allows data scientists to retrieve specific data efficiently and prepare it for further analysis in Python or R. Each of these languages serves a specific role: Python and R for in-depth data analysis and modeling, and SQL for working directly with large datasets at the source. Mastery of these tools allows data professionals to handle end-to-end data workflows, from extraction and cleaning to modeling and reporting, making them indispensable assets in any data-driven project or organization.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Machine Learning & Deep Learning
- Supervised Learning: Involves training models on labeled data to predict outcomes, commonly used in regression and classification tasks.
- Unsupervised Learning: Focuses on identifying patterns or groupings in unlabeled data, such as clustering or dimensionality reduction.
- Reinforcement Learning: Training models to make a sequence of decisions by rewarding desired behaviors often used in robotics and game AI is a key focus area in Artificial Intelligence Hot Technology trends.
- Neural Networks: The foundation of deep learning, consisting of layers of interconnected nodes that process and learn from data.
- Convolutional Neural Networks (CNNs): Specialized for image and visual data processing, widely used in facial recognition and computer vision tasks.
- Recurrent Neural Networks (RNNs): Designed for sequential data like time series or text, useful in language modeling, translation, and speech recognition.
- Clarity and Simplicity: Visuals should be easy to interpret, avoiding clutter and focusing on the key message or trend in the data.
- Choice of Visualization: Selecting the right type of chart such as bar charts, line graphs, scatter plots, or heatmaps enhances understanding and ensures accurate communication, a crucial skill along the Data Science Career Path.
- Tools and Libraries: Familiarity with tools like Tableau, Power BI, or libraries such as Matplotlib, Seaborn, and Plotly helps create effective and interactive visualizations.
- Data-Driven Narratives: Crafting a compelling story around the data helps contextualize findings and aligns insights with real-world decisions or problems.
- Audience Awareness: Tailoring visual content and language to the knowledge level of the audience technical or non-technical ensures better engagement.
- Use of Design Principles: Applying principles like color theory, contrast, and layout enhances visual appeal and makes the data easier to interpret.
Machine learning and deep learning are key pillars of modern data science, enabling systems to learn from data and make intelligent decisions with minimal human intervention. While machine learning focuses on algorithms that learn patterns and make predictions, deep learning is a specialized subset that uses neural networks to solve complex problems like image recognition, natural language processing, and autonomous systems. Together, these technologies power many of today’s AI-driven applications.

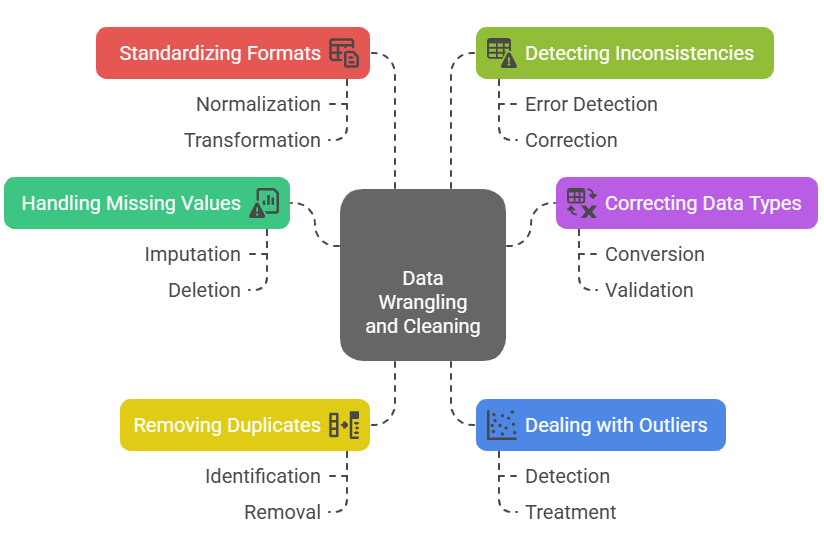
Data Wrangling and Cleaning
Data wrangling and cleaning are critical steps in the data science workflow, as raw data is often messy, incomplete, or inconsistent. This process involves transforming and preparing data into a usable format for analysis, ensuring its quality and reliability. Tasks in data wrangling include handling missing values, correcting data types, removing duplicates, dealing with outliers, and standardizing formats. Cleaning, a key step emphasized in Data Science training also involves detecting and fixing inconsistencies, such as incorrect entries, formatting issues, or invalid data points. Effective data wrangling not only improves the accuracy of models but also saves time during analysis and helps uncover meaningful insights. Tools like Python’s Pandas, R’s dplyr, and various data profiling libraries are commonly used to automate and streamline these tasks. Additionally, SQL is often employed to extract and clean data directly from databases before deeper analysis. Clean and well-structured data is the foundation of successful machine learning and statistical modeling, as even the most advanced algorithms cannot compensate for poor-quality input. Thus, data wrangling is not just a preliminary step, it’s an essential practice that ensures the integrity and success of any data-driven project, making it a vital skill for every data science professional.
Data Visualization and Storytelling
Data visualization and storytelling are essential for transforming raw data into meaningful insights that can be easily understood and acted upon by diverse audiences. While data visualization involves creating charts, graphs, and interactive dashboards to represent data visually, storytelling adds context and narrative to guide interpretation and decision-making. Together, they help bridge the gap between complex analyses and actionable business strategies.
Big Data Tools (Spark, Hadoop, etc.)
Big data tools like Apache Spark, Hadoop, and others are essential for handling and processing massive volumes of data that traditional tools cannot efficiently manage. As data grows in scale, velocity, and variety, these tools enable data scientists and engineers to store, process, and analyze information across distributed systems. Hadoop provides a reliable, scalable framework for distributed storage (via HDFS) and processing (via MapReduce), making it suitable for batch-processing large datasets. Spark, on the other hand, offers faster, in-memory processing capabilities, making it ideal for real-time data analytics, machine learning, and iterative computations key components in understanding What is Predictive Analytics. These tools support programming in languages like Python, Java, and Scala, and integrate with other technologies such as Hive, Pig, and Kafka for data querying and streaming. The use of big data tools is especially critical in industries like finance, healthcare, and e-commerce, where large-scale, real-time insights are essential for decision-making. Mastery of these platforms allows professionals to manage unstructured or semi-structured data efficiently, perform large-scale analytics, and deploy scalable data pipelines. In a world increasingly driven by data, proficiency in big data tools is a key asset for anyone aiming to work with high-volume, high-velocity information environments.
Go Through These Data Science Interview Questions & Answer to Excel in Your Upcoming Interview.
Cloud Computing Skills (AWS, Azure)
Cloud computing skills are increasingly vital in data science, enabling professionals to access scalable infrastructure, storage, and computing power without the need for on-premises hardware. Platforms like Amazon Web Services (AWS) and Microsoft Azure offer a wide range of services that support data storage, processing, machine learning, and deployment of analytics solutions.AWS, often covered in Data Science training, provides tools such as S3 for storage, EC2 for computing, and SageMaker for building and deploying machine learning models. Similarly, Azure offers services like Azure Data Lake, Azure Machine Learning, and Azure Databricks for end-to-end data workflows. These cloud platforms allow data scientists to handle large-scale datasets, collaborate in real-time, and deploy models into production environments seamlessly. Cloud computing also supports automation, monitoring, and security features, which are essential for maintaining efficient and reliable data operations. With the rise of remote work and global teams, cloud-based environments facilitate easy access to data and tools from anywhere. Understanding how to use cloud services not only improves the efficiency and scalability of data projects but also aligns with industry trends where most organizations are shifting their infrastructure to the cloud. Thus, cloud computing expertise, especially in AWS and Azure, is a critical asset for modern data science professionals.




