
Last updated on 24th Apr 2025| 7819
- Introduction to NLP and Corpus
- Definition of a Corpus in NLP
- Types of Corpora in NLP
- Monolingual vs. Multilingual Corpora
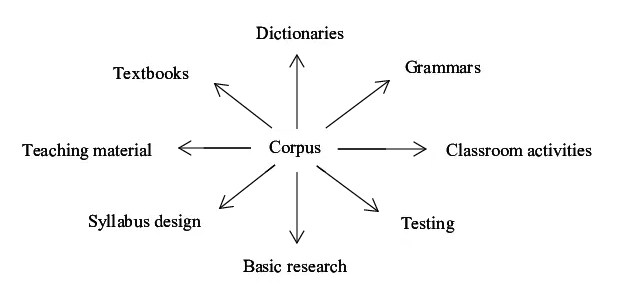
- Role of Corpus in Language Processing
- How to Build a Corpus for NLP
- Corpus Annotation and Preprocessing
- Challenges in Data Wrangling
- Conclusion
Introduction to NLP and Corpus
Natural Language Processing (NLP) is a dynamic and rapidly evolving subfield of Artificial Intelligence (AI) that empowers machines to understand, interpret, analyze, and generate human language in a meaningful way. NLP bridges the gap between human communication and computer understanding by integrating computational linguistics, machine learning, and deep learning techniques. These technologies enable the processing and extraction of valuable insights from vast amounts of natural language data. One of the most critical components in the development of NLP systems, especially in Data Science Training, is the corpus, which refers to a large and well-organized collection of written or spoken texts. A high-quality, diverse, and well-structured corpus is essential for training robust language models, as it provides the linguistic data required to learn grammar, syntax, semantics, and contextual usage. Such corpora play a foundational role in a wide range of NLP tasks, including but not limited to text classification, named entity recognition (NER), sentiment analysis, machine translation, question answering, speech recognition, and language generation. By leveraging powerful algorithms and massive corpora, NLP continues to drive advancements in voice assistants, chatbots, automated content moderation, and various language-based applications that enhance human-computer interaction.
Eager to Acquire Your Data Science Certification? View The Data Science Course Offered By ACTE Right Now!
Definition of a Corpus in NLP
In NLP, a corpus is a large and structured set of texts used to train, test, and validate language models and NLP algorithms. These texts could include written documents, speech transcripts, or any data that reflects natural language use. The corpus is a foundation for statistical analysis, feature extraction, and pattern recognition in NLP tasks.
- Raw Text: The actual content of the corpus, often unprocessed and in its original form.
- Annotations: Labels or tags attached to the text, such as part-of-speech tags, named entities, sentiment labels, etc.
- Metadata: Information about the text, such as author, genre, date of creation, etc.
Types of Corpora in NLP
Monolingual Corpora: These contain texts in a single language. A monolingual corpus is used for language modeling, text classification, and sentiment analysis in one language.
- Example: The British National Corpus (BNC), an extensive collection of written and spoken texts in British English.
Multilingual Corpora: These corpora contain texts in multiple languages and are particularly useful for tasks such as machine translation, cross-lingual information retrieval, and multilingual text classification.
- Example: The Europarl Corpus consists of European Parliament proceedings in multiple languages.
Parallel Corpora: A multilingual corpus that contains text in one language and its translation in another is commonly used in Natural Language Processing tasks such as machine translation.
- Example: The Canadian Hansard Corpus contains English and French versions of Canadian parliamentary debates.
Specialized Corpora: These are focused on a specific domain or genre of text, such as medical, legal, or scientific texts. They help train NLP models tailored to specific applications.
- Example: The PubMed corpus, a collection of medical literature, or LegiLex, a corpus of legal documents.
Spoken Corpora: These corpora consist of transcriptions of spoken language and are valid for speech recognition and natural language understanding in audio or spoken contexts.
- Example: The Switchboard Corpus, a collection of telephone conversations for training speech recognition systems.
Monolingual vs. Multilingual Corpora
Monolingual Corpora:
- Focused on a single language.
- Used for tasks like language modeling, text classification, sentiment analysis, and part-of-speech tagging.
- It is more straightforward and less complex to manage but limited to a specific language.
Multilingual Corpora:
Excited to Obtaining Your Data Science Certificate? View The Data Science Training Offered By ACTE Right Now!
Role of Corpus in Language Processing
A corpus serves as the foundation for training and evaluating NLP models. It plays a crucial role in the following ways:
- Training Data: A corpus trains language models, helping them learn statistical patterns and relationships between words and phrases.
- Evaluation: Corpora serve as a benchmark to evaluate the performance of NLP algorithms, including tasks such as Parsing in NLP. A test corpus assesses how well a model generalizes to unseen data.
- Feature Extraction: A corpus helps extract features (like n-grams, word embeddings, and part-of-speech tags) needed for various NLP tasks.
- Language Understanding: By analyzing large corpora, NLP models can better understand the structure, syntax, semantics, and nuances of natural language.
Interested in Pursuing Data Science Master’s Program? Enroll For Data Science Master Course Today!
How to Build a Corpus for NLP
Building a corpus for Natural Language Processing (NLP) involves a series of essential and methodical steps to ensure the resulting dataset is both useful and effective for training language models. The process begins with data collection, where a large and diverse set of texts is gathered from various sources such as web scraping, publicly available datasets, or domain-specific documents like legal or medical texts. Following collection, data cleaning is performed to preprocess the raw text by removing noise such as special characters, irrelevant content, and duplicates—and applying techniques like tokenization, stemming, and lemmatization to standardize the text. If the corpus is intended for supervised learning tasks, annotation becomes necessary, involving the labeling of data for applications such as part-of-speech tagging, named entity recognition, sentiment analysis, or Data science Training. After annotation, the corpus needs to be organized in a structured format that is easy to manage and compatible with processing tools, typically using formats like XML, JSON, or CSV. Finally, validation is crucial to ensure the corpus accurately represents the intended language or domain and contains high-quality, consistent annotations. This structured approach lays the foundation for building reliable and effective NLP models.

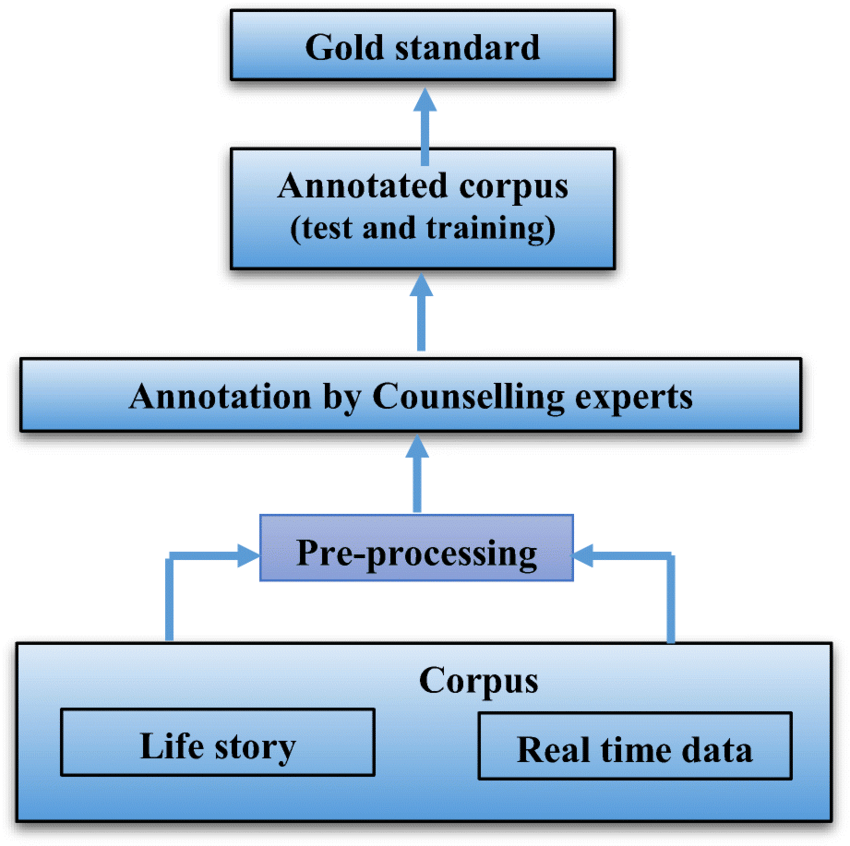
Corpus Annotation and Preprocessing
Annotation involves adding labels or tags to the text for various tasks such as named entity recognition (NER), part-of-speech tagging, sentiment analysis, or syntactic parsing. Annotations are typically done manually or through semi-automatic tools, though high-quality annotations can be expensive and time-consuming; however, Deep Learning techniques are increasingly being explored to automate and enhance this process.
Preprocessing includes tasks like:
- Tokenization: Splitting the text into smaller units, such as words or subwords.
- Lowercasing: Converting all text to lowercase to maintain consistency.
- Stopword Removal: Removing common words like “the,” “and,” “is,” etc., that do not contribute to meaning.
- Lemmatization/Stemming: Reducing words to their base forms (e.g., “running” to “run”).
- POS Tagging: Labeling words with corresponding parts of speech tags (noun, verb, etc.).
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
Challenges in Corpus Management
Managing a corpus can be a complex and resource-intensive task due to the following challenges:
- Data Diversity: Ensuring the corpus includes diverse text samples from various genres, domains, and sources to avoid bias.
- Size and Scalability: Storing, processing, and analyzing large corpora can be challenging, especially when dealing with terabytes of data.
- Annotation Quality: High-quality, accurate annotations are crucial, but manual annotation can be time-consuming and prone to human error, making Process Capability Analysis essential for evaluating and improving annotation consistency and efficiency.
- Language Variations: Handling linguistic variations, such as dialects, slang, or evolving language usage, is often tricky, particularly for multilingual corpora.
- Ethical Concerns: Ensuring that corpora do not contain biased, harmful, or inappropriate content is essential for fair and responsible AI development.
Conclusion
In conclusion, corpora play a vital and foundational role in Natural Language Processing (NLP) by providing the extensive and diverse data required to train, fine-tune, and evaluate artificial intelligence (AI) models. A well-constructed corpus serves as the backbone of any NLP system, enabling machines to learn linguistic patterns, semantic structures, and contextual meanings effectively. Building high-quality, diverse, and representative corpora is essential for pushing the boundaries of NLP technologies, enhancing Data Science Training, and achieving more accurate, reliable, and context-aware language models. As AI continues to evolve and grow more sophisticated, the development of better, larger, and more precisely annotated corpora will remain a critical factor in enhancing the performance and applicability of language models across a wide range of real-world scenarios—from virtual assistants and customer service bots to translation tools and content moderation systems. Therefore, understanding how to properly collect, manage, annotate, and preprocess corpora is a key competency for researchers, engineers, and developers working in the NLP field. Mastery of these processes ensures the creation of data-driven solutions that are both scalable and linguistically intelligent.




