
Last updated on 13th May 2025| 9855
- What is a Confusion Matrix in Machine Learning ?
- Application of Data Science in the Finance Industry
- Four viable outcomes
- Why learn confusion Matrix
- Understanding various performance metrics
- Accuracy or Classification Accuracy
- Advantages and disadvantages of a confusion matrix
- Conclusion
In Confusion Matrix in Machine Learning, a matrix is a fundamental data structure used to represent and manipulate data, especially in algorithms involving linear algebra. It is essentially a two-dimensional array of numbers arranged in rows and columns. Matrices are widely used for storing datasets (where Data Science Course Training represent instances and columns represent features), performing mathematical operations like transformations, and optimizing models through techniques like gradient descent. In deep learning, matrices are used extensively in operations such as weight multiplication, activation functions, and backpropagation. Overall, matrices provide a structured and efficient way to handle large volumes of numerical data, making them essential for the development and implementation of machine learning models.
What Is a Confusion Matrix in Machine Learning?
A confusion matrix is a desk used to assess the overall performance of a class version in Machine mastering in Python. Confusion Matrix in Machine Learning compares the absolute goal values with the ones anticipated with the aid of using the version, assisting in picking out in which the version is getting matters proper and in which it’s far making mistakes. The matrix is usually organized in a 2×2 layout for binary class, displaying the counts of proper positives (effectively anticipated positives), proper negatives (effectively anticipated negatives), fake positives (incorrectly anticipated positives), and fake negatives (incorrectly expected negatives expected). The matrix can make bigger to greater rows and columns for the multi-magnificence class. By reading a confusion matrix, records scientists can Data Mining and Data Warehousing from more profound insights into a version`s strengths and weaknesses past what easy accuracy metrics can provide. This is the most famous technique used to assess logistic regression. Without further delay, let’s get started. Machine mastering in Python has become famous because of its simplicity, versatility, and the wealth of libraries and equipment available. Python gives user-pleasant libraries like sci-kit-learn, TensorFlow, Keras, and PyTorch, which make it easy to put diverse device mastering algorithms in force—from primary linear regression to superior deep mastering models. With those equipment, builders and records scientists can efficiently manage duties including class, regression, clustering, and advice structures. Python additionally integrates nicely with records evaluation libraries like Pandas and NumPy and visualization equipment like Matplotlib and Seaborn, bearing in mind a continuing quit-to-quit device Machine mastering in Python workflow. Confusion Matrix in Machine Learning readable syntax and robust network help make Python the go-to language for novices and experts inside the device-mastering field.
Become a Data Science expert by enrolling in this Data Science Online Course today.
Application of Data Science in the Finance Industry
Data science allows for things such as handling dangers, catching fraud, using ML algorithms to trade, and optimizing portfolios. By using unique strategies like device mastering and studying massive quantities of statistics. This results in higher predictions and more excellent money-making opportunities. It additionally saves money and time by automating repetitive tasks. Overall, statistics technology is converting finance for the higher and supporting companies to make smarter decisions. Let’s check the main Data Management programs inside the Classification in Data Mining. Customer Data Management: As mentioned, statistics is one of the primary sources of information in the enterprise area. Nowadays, most agencies make use of patron statistics to beautify their productivity. The statistics of clients allow monetary establishments to maintain music in their transactions. In advance days, agencies saved statistics on the usage of conventional methods. However, the upward thrust of numerous technologies has given a brand new path to the finance enterprise. Nowadays, the technology utilized by the finance enterprise are Big Data equipment, Data Science, Artificial Intelligence, and Machine Learning. With the assistance of this technology, statistics control has emerged as much less complicated than in the past. data science techniques monetary establishments is used to control and save their clients` statistics efficiently. The statistics saved through those establishments may be dependent or unstructured. However, the equipment of Data Science can process, store, and segment can process, store, and segment all varieties of statistics. The saved statistics may be processed to prepare the monetary reviews of those agencies.
Advance your Data Science career by joining this Data Science Online Course now.
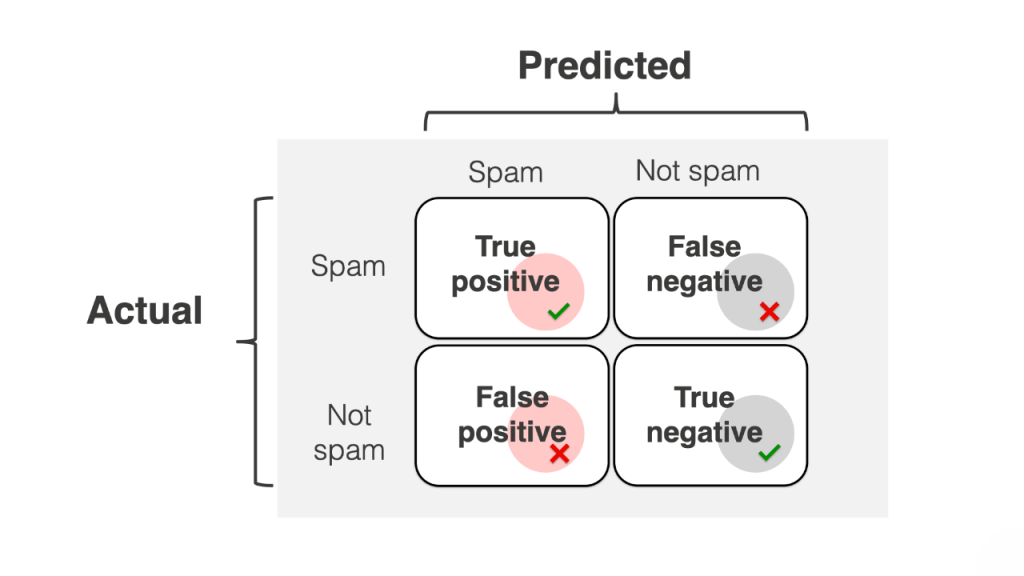
Four viable outcomes
- True Positive: The actual fine is not anything; it is the case wherein the real price and the anticipated cost are actual. The affected person has been identified with most cancers, and the version also anticipated that the affected person had the most cancers.
- False Negative: In a fake negative, the real price is actual, but the anticipated cost is fake. Because of this, the version anticipated that the affected person had most cancers, but the affected person no longer had most cancers.
- False Positive: This is the case wherein the anticipated price is Data Management in Organizations. However, the real cost is fake. Here, the version anticipated that the affected person had most cancers; however, the affected person didn’t have most cancers.
- True Negative: This is the case wherein the real price and the anticipated cost are likewise fake. In other words, the affected person isn’t always identified with most cancers, and our version anticipated that the affected person no longer has most cancers.
Why Learn Confusion Matrix
Learning the confusion matrix is critical for all people running with class fashions in device studying as it affords deeper information on how a version performs properly. Unlike an easy accuracy score, a confusion matrix breaks down predictions into actual positives, actual negatives, fake positives, and fake negatives. This specified perception allows the pick out of not simply what Classification in Data Mining of forecasts had been correct but what styles of mistakes the version is making. For example, in touchy programs like scientific analysis or fraud detection, information about distinguishing between false positives and false negatives is crucial. By studying the way to examine and interpret a confusion matrix, you could fine-track fashions more effectively, pick out the proper overall performance metrics, and make more knowledgeable selections primarily based totally on version behavior.

Understanding Various Performance Metrics
We might use the confusion Matrix in Python given below to discover numerous overall performance metrics.Understanding Various Performance Metrics is essential for evaluating the effectiveness of a machine learning classification model. While accuracy is the most commonly used metric, it doesn’t always provide a complete picture especially in cases of imbalanced datasets. To gain deeper AI Tools for Coding, we use metrics derived from the confusion matrix, which outlines true positives, true negatives, false positives, and false negatives. From this, we calculate precision, which measures the proportion of correct positive predictions, and recall, which assesses the model’s ability to identify all actual positives. The F1-score balances precision and recall, offering a more reliable performance indicator in uneven class distributions. Additionally, specificity helps evaluate how well the model identifies negative cases. Together, these metrics provide a comprehensive understanding of a model’s strengths and weaknesses, enabling better decision-making when choosing or fine-tuning algorithms.
Ready to excel in Data Science? Enroll in ACTE’s Data Science Master Program Training Course and begin your journey today!
Accuracy or Classification Accuracy
Classification Accuracy, often simply called Accuracy, is a widely used metric to evaluate classification models. It is calculated as the number of correct predictions divided by the total number of predictions made. Data Science Course Training metric gives a quick overview of how well a model is performing overall. However, accuracy alone can be misleading, especially with imbalanced datasets for example, if 95% of the data belongs to one class, a model that always predicts that class will still have 95% accuracy without truly understanding the data. Therefore, it is important to consider other metrics like precision, recall, and F1-score to get a more balanced view of model performance. Accuracy is best used when the classes in the dataset are balanced and of equal importance.
- Definition: Accuracy is the ratio of correctly predicted instances to the total number of To Build and Annotate an NLP Corpus Easily made.
- Formula: Accuracy = (True Positives + True Negatives) / Total Predictions.
- Use Case: Best used with balanced datasets where all classes are equally important.
- Limitation: Can be misleading with imbalanced data, as high accuracy may still mean poor model performance on minority classes
- Detailed Evaluation: It gives a complete breakdown of the version’s overall performance by displaying the range of real positives, real negatives, fake positives, and fake negatives.
- Helps Calculate Multiple Metrics: From the confusion matrix, we may derive the numerous essential metrics: accuracy, precision, recall, Master Prompt Engineering for Better AI Results , and specificity.
- Performance Insight: It now exhibits not simply how regularly a version is right but also how it makes mistakes—which lessons are being burdened with others.
- Model Comparison: Confusion matrices assist in examining the overall performance of various fashions or algorithms by supplying an in-depth view of their prediction outcomes.
- Scales Poorly with Many Classes: The confusion matrix will become massive and more challenging to interpret for multi-magnificence class issues with many categories.
- Only Works for Classification: It isn’t relevant for regression issues — it simplest evaluates class models.
- No Probabilistic Insight: Unlike probability-primarily based totally assessment methods, it doesn`t offer records of approximately how assured the version turned into in its predictions.
Are you getting ready for your Data Science interview? Check out our blog on Data Science Interview Questions and Answers!
Advantages and disadvantages of a confusion matrix
Advantages of Confusion Matrix:
Disadvantages of Confusion Matrix:
Conclusion
In conclusion, the confusion Matrix in Python is a crucial assessment device in gadget Machine mastering in Python that allows for examining the overall performance of class models. By imparting an in-depth breakdown of real positives, real negatives, fake positives, and fake negatives, it gives a deeper perception of easy accuracy. Using Python, specifically with libraries like sci-kit-learn, makes generating and interpreting a confusion Matrix in Python. Data Science Course Training permits recorded scientists to discover the strengths and weaknesses of their models, optimize them accordingly, and make more knowledgeable decisions. Ultimately, getting to know the usage of confusion matrices is essential for constructing dependable and powerful gadget-mastering solutions.




