
Last updated on 20th May 2025| 9692
- Introduction to Clustering in Data Mining
- Importance of Clustering for Data Analysis
- Types of Clustering Techniques
- K-Means Clustering: Working and Applications
- Hierarchical Clustering: Agglomerative and Divisive Methods
- DBSCAN: Density-Based Clustering Approach
- Mean-Shift Clustering Algorithm
- Evaluating Clustering Performance
- Challenges in Clustering Large Datasets
- Future Trends in Clustering Techniques
Introduction to Clustering in Data Mining
Clustering is a core technique in data mining and machine learning that involves grouping data points so that items within the same cluster are more similar to each other than to those in different clusters. As an unsupervised learning method, it uncovers hidden patterns and structures in data without requiring labeled inputs. This technique is widely applied in fields such as market segmentation, social network analysis, anomaly detection, and image recognition, aiding in identifying natural groupings and supporting strategic decision-making. With the rise in interest across industries, many professionals are turning to Data Science Training to gain hands-on experience and deepen their understanding of clustering and related methods. As data continues to grow rapidly, clustering techniques have advanced significantly, requiring more efficient algorithms and computational power to process large and complex datasets. Recent developments integrate deep learning and artificial intelligence to enhance scalability and accuracy. Despite its effectiveness, clustering presents challenges such as determining the optimal number of clusters and managing noisy or high-dimensional data. This document explores the range of clustering techniques, their practical uses, the hurdles they face, and emerging trends that are shaping their evolution in the era of big data and intelligent systems.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Importance of Clustering for Data Analysis
Clustering plays a crucial role in data analysis by providing insights that might not be immediately apparent. It helps in pattern recognition, customer segmentation, anomaly detection, and simplifying large datasets. By identifying groups within a dataset, businesses and researchers can make informed decisions, optimize marketing strategies, detect fraudulent activities, and enhance recommendation systems. Clustering also helps in reducing the dimensionality of data, making it easier to visualize and interpret complex datasets.
For businesses, customer segmentation based on clustering can lead to improved targeted advertising, efficient inventory management, and better customer relationship management. In healthcare, clustering aids in patient segmentation, enabling more precise treatments and disease outbreak predictions. In finance, clustering helps in fraud detection by identifying anomalous transactions that deviate from typical spending patterns. Learn Data Science to understand how these clustering techniques are applied across industries and to build the skills needed to extract actionable insights from complex data. Furthermore, in social network analysis, clustering reveals hidden community structures, influencing content recommendation algorithms and improving user engagement.
These platforms offer pre-trained models, APIs, and computing resources for training deep learning models. Additionally, version control systems like Git and platforms like Hugging Face Model Hub provide repositories for sharing and reusing models. By setting up an efficient development environment, NLP practitioners can accelerate research, experimentation, and deployment of NLP solutions.
Types of Clustering Techniques
- Partitioning Clustering: Divides data into distinct clusters, with each data point belonging to only one cluster. K-Means is a popular example of partitioning clustering. The technique is efficient but requires the number of clusters to be predefined, which can be a limitation in cases where the optimal number is unknown.
- Hierarchical Clustering: Creates a hierarchy of clusters through either an agglomerative (bottom-up) or divisive (top-down) approach. This technique is beneficial for datasets with inherent hierarchical structures, such as taxonomy classification in biology.
- Density-Based Clustering: Groups data points based on density, distinguishing between noise and clusters. DBSCAN is a well-known density-based clustering method, which is particularly useful for detecting irregularly shaped clusters and handling noise in data. To stay competitive in applying techniques like these, it’s important to focus on Logical Thinking in AI, which cover the latest tools and approaches shaping the future of data analysis.
- Grid-Based Clustering: Divides data space into a finite number of cells and performs clustering based on the density of cells. STING (Statistical Information Grid) is an example of a grid-based approach that efficiently handles large spatial datasets.
- Model-Based Clustering: Assumes data is generated from a mixture of underlying probability distributions and assigns probabilities to cluster memberships. Gaussian Mixture Models (GMMs) are widely used in probabilistic clustering, providing more flexible cluster shapes than K-Means.
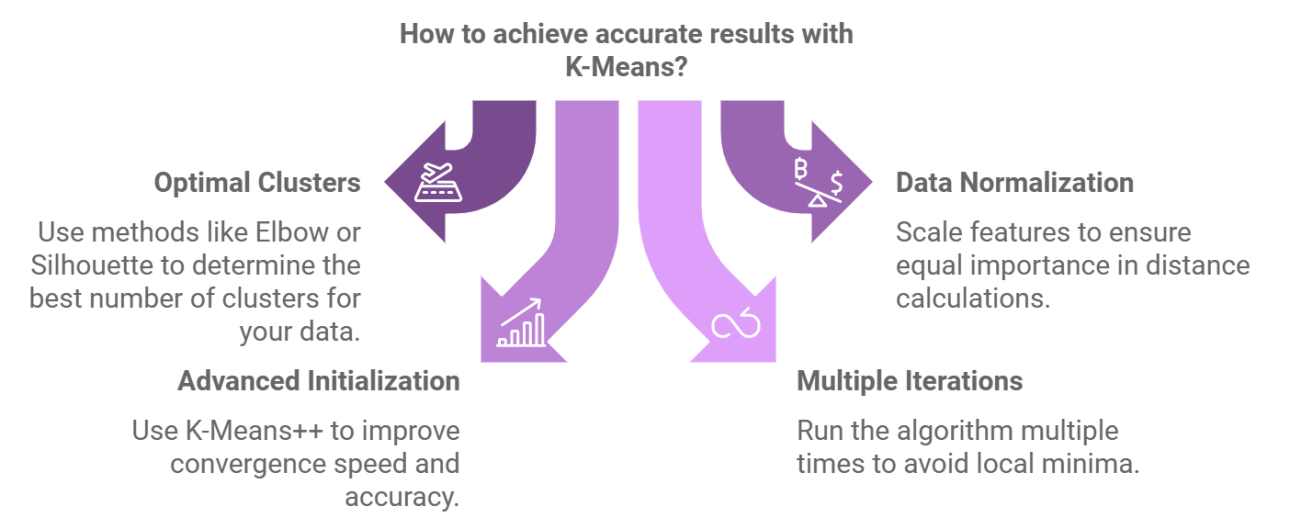
- Selecting K initial cluster centroids.
- Assigning each data point to the nearest centroid based on Euclidean distance.
- Recalculating the centroids as the mean of all points in the cluster.
- Iterating steps 2 and 3 until convergence, where centroids no longer change significantly.
- Customer Segmentation: Businesses segment customers based on purchasing behavior, demographics, and preferences to optimize marketing campaigns.
- Document Clustering: Search engines group similar documents together to improve information retrieval.
- Anomaly Detection: Identifies unusual patterns in network traffic, financial transactions, and manufacturing defects.
- Image Compression: Reduces colors in an image while maintaining visual quality, widely used in digital media applications.
- Geospatial Data Analysis: Detecting urban areas, road networks, and climate zones from satellite imagery.
- Fraud Detection: Identifying anomalous transactions that do not conform to known patterns.
- Network Security Monitoring: Detecting abnormal user behavior in cybersecurity systems.
- Image Segmentation: Grouping pixels with similar color intensities.
- Object Tracking: Tracking objects in video sequences based on movement patterns.
- Feature Space Analysis: Identifying high-density regions in datasets for feature engineering.
- Scalability: Algorithms like hierarchical clustering have high computational complexity.
- Handling High-Dimensional Data: Distance-based methods become less effective as dimensionality increases.
- Choosing the Right Number of Clusters: Many algorithms require the number of clusters to be specified in advance.
- Dealing with Noise and Outliers: Methods like DBSCAN handle noise well, but many algorithms do not.
- Interpreting Results: Clustering results may not always have clear real-world meanings.
There are several clustering techniques, each with its own strengths and applications:
Each of these clustering techniques has its advantages and limitations, making it essential to choose the right method based on the dataset characteristics and problem requirements.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
K-Means Clustering: Working and Applications
K-Means is one of the most widely used clustering algorithms due to its simplicity and efficiency. It works by:
Applications of K-Means include:
Hierarchical Clustering: Agglomerative and Divisive Methods
Hierarchical clustering is a method of cluster analysis that builds a nested hierarchy of clusters using either an agglomerative or divisive approach. The agglomerative method begins with each data point treated as an individual cluster and then progressively merges the most similar clusters based on similarity metrics such as Ward’s method, single linkage, or complete linkage. In contrast, the divisive approach starts with all data points grouped in a single cluster and recursively splits them into smaller clusters, working from the top down. This technique does not require specifying the number of clusters in advance, making it particularly advantageous for exploratory data analysis. For those interested in mastering this and other clustering methods, our Data Science Training offers comprehensive, hands-on learning ideal for building real-world skills and advancing your analytical expertise. Hierarchical clustering is widely used in various domains due to its interpretability and the clear tree-like structure (dendrogram) it produces. In taxonomy classification, it helps in organizing biological species into structured hierarchies based on shared characteristics. In social network analysis, it aids in detecting communities, mapping influence patterns, and understanding hierarchical relationships within a network. Additionally, in gene expression analysis, hierarchical clustering is employed to group genes with similar expression profiles, which is critical for identifying functional relationships and studying genetic disorders. Its ability to reveal nested patterns makes it a valuable tool for uncovering multi-level insights in complex datasets.

DBSCAN: Density-Based Clustering Approach
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) groups together data points that are close in proximity and have sufficient neighbors. Unlike K-Means, DBSCAN can detect clusters of arbitrary shapes and handle noise effectively. If you’re interested in mastering techniques like this and advancing professionally, explore how you can Build a Career in Data Science Today.
Applications include:
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Mean-Shift Clustering Algorithm
Mean-Shift is a non-parametric clustering algorithm that finds dense areas in a feature space by iteratively shifting points towards higher density regions. Unlike K-Means, it does not require specifying the number of clusters beforehand.
It is commonly used in:
Evaluating Clustering Performance
Several evaluation metrics are commonly used to assess the performance and quality of clustering results, helping determine how well the algorithm has grouped the data. The Silhouette Score measures how similar each data point is to its own cluster compared to other clusters, with higher values indicating better-defined clusters. The Davies-Bouldin Index evaluates the compactness within clusters and the separation between them; lower values signify better clustering performance.Enroll in our Data Science Training can provide valuable insights into how these metrics work and how to apply them effectively in real-world scenarios. The Dunn Index is another metric that helps identify clusters that are both well-separated and internally compact, with higher scores reflecting superior clustering structure. Additionally, when ground truth labels are available, the Rand Index and Adjusted Rand Index are used to compare the clustering output with the actual classification. These indices quantify the similarity between two data partitions, with the Adjusted Rand Index correcting for chance groupings. Together, these metrics provide a robust framework for validating clustering results and guiding the selection or tuning of clustering algorithms based on the structure and characteristics of the dataset.
Go Through These Data Science Interview Questions & Answer to Excel in Your Upcoming Interview.
Challenges in Clustering Large Datasets
Clustering large datasets presents several challenges:
Future Trends in Clustering Techniques
Future trends in clustering are increasingly shaped by advancements in artificial intelligence and machine learning, paving the way for more powerful and adaptive techniques. Deep learning-based clustering leverages neural networks to learn complex, high-dimensional representations of data, enabling more accurate and meaningful groupings, especially in unstructured datasets like images or text. Scalable clustering methods are being developed to efficiently handle the ever-growing volume of big data, ensuring that clustering algorithms remain practical and effective in real-world applications. As the field evolves, it’s essential to develop a strong foundation in programming and data science. Learn Python for Data Science and Web Jobs to equip yourself with the necessary skills for mastering these cutting-edge techniques. Another promising direction is hybrid clustering approaches, which combine the strengths of different clustering algorithms to improve accuracy, robustness, and flexibility across diverse data types. Self-supervised clustering is also gaining momentum, as it utilizes the vast amount of unlabeled data to improve clustering outcomes without the need for manual annotations, enhancing performance in domains where labeled data is scarce. As these innovations continue to emerge, clustering is becoming an even more versatile and essential tool for extracting insights, supporting decision-making, and driving innovation across various industries.




