
Last updated on 07th Aug 2025| 13004
- Introduction to Evaluation Metrics
- Precision and Recall Explained
- Definition of F1 Score
- F1 Score Formula
- F1 Score in Imbalanced Datasets
- Macro vs Micro Averaging
- F1 Score vs Accuracy
- When to Use F1 Score
- ROC-AUC vs F1
- Case Studies and Use Cases
- Conclusion
Introduction to Evaluation Metrics
In the world of machine learning, especially classification problems, evaluating a model’s performance accurately is crucial. Evaluation metrics are the tools used to determine how well a model performs, helping practitioners decide whether the model is suitable for deployment. Machine Learning Training emphasizes the use of metrics like accuracy, precision, recall, F1-score, and ROC-AUC to guide model selection and validation. While accuracy is the most commonly used metric, it doesn’t always tell the whole story especially in imbalanced datasets. That’s where other metrics like precision, recall, and most importantly, the F1 Score in Machine Learning come in. These metrics provide a deeper understanding of a model’s strengths and weaknesses, ensuring it performs not just well on paper, but effectively in the real world.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Precision and Recall Explained
In machine learning evaluation, data scientists need to understand precision and recall to assess model performance. The model calculates precision by measuring how accurate its positive predictions are.
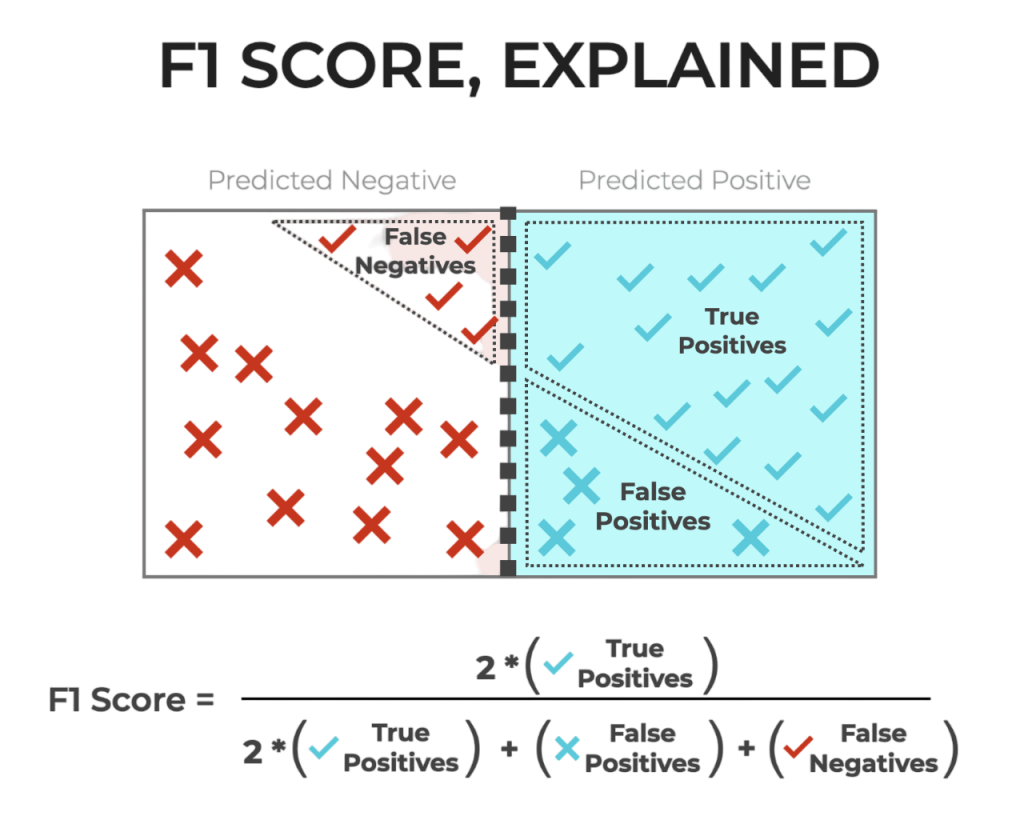
It computes the ratio of true positive results to all positive predictions, answering how often the model correctly identifies a positive case. Recall, on the other hand, focuses on the model’s ability to find all actual positive instances. It determines the proportion of true positives among all actual positive cases. Researchers usually represent these metrics with formulas that use true positives (TP), false positives (FP), and false negatives (FN). Precision is calculated as TP / (TP + FP), while recall is calculated as TP / (TP + FN). By looking at these key metrics, data scientists can better understand a model’s predictive abilities and find areas for improvement.
Definition of F1 Score
The F1 Score in Machine Learning is the harmonic mean of precision and recall. It is a single number that balances the trade-off between precision and recall. Support Vector Machine (SVM) Algorithm models often benefit from F1 Score evaluation, especially in imbalanced classification tasks where both false positives and false negatives carry significant weight. The F1 score becomes especially valuable when there’s an uneven class distribution or when the cost of false positives and false negatives is high. F1 Score = 2 * (Precision * Recall) / (Precision + Recall), Unlike the arithmetic mean, the harmonic mean gives more weight to lower values, ensuring that both precision and recall must be high for a good F1 score.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
F1 Score Formula
Let’s expand the formula in terms of actual confusion matrix values: Decision Trees in Machine Learning use confusion matrix-derived metrics like accuracy, precision, recall, and F1 Score to evaluate split quality and model performance, especially in classification tasks.
- Precision = TP / (TP + FP)
- Recall = TP / (TP + FN)
- F1 Score = 2 * TP / (2 * TP + FP + FN)
This formulation highlights the role of true positives in balancing both false positives and false negatives, giving a nuanced view of model performance.

F1 Score in Imbalanced Datasets
Imbalanced datasets are common in real-world scenarios like fraud detection, medical diagnoses, or rare event prediction. A model could predict the majority class all the time and still achieve high accuracy. However, such a model might entirely miss the minority class. Pattern Recognition and Machine Learning techniques address this by incorporating metrics beyond accuracy and applying sampling strategies or cost-sensitive learning to improve minority class detection.
Example:
In a dataset with 99% class A and 1% class B, a model that predicts only class A has 99% accuracy but it fails completely at detecting class B. Here, the F1 Score in Machine Learning becomes invaluable. It ensures that both precision and recall are considered, giving a better overall picture, especially for minority class performance.
Macro vs Micro Averaging
In multiclass classification problems, data scientists compute a single F1 score using different averaging techniques to represent model performance. Researchers calculate macro-averaging by finding the F1 Score in Machine Learning for each class separately and then taking their average. Machine Learning Training covers macro-averaging techniques to ensure balanced performance evaluation across all classes, especially in multi-class classification tasks. This approach gives each class equal importance. Alternatively, they use micro-averaging, which involves counting the true positives, false positives, and false negatives across all classes before calculating the F1 score. This method works well for datasets with imbalanced class distributions. For a more detailed evaluation, practitioners use weighted averaging, which weighs each class’s F1 score according to its number of true instances. Researchers can easily apply these techniques using scikit-learn’s f1_score function. They simply specify the desired averaging method: ‘macro’, ‘micro’, or ‘weighted’, to get a complete assessment of their multiclass classification models.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
F1 Score vs Accuracy
Accuracy is defined as the number of correct predictions divided by the total number of predictions. It’s a useful metric when classes are evenly distributed and the cost of different types of errors is the same.
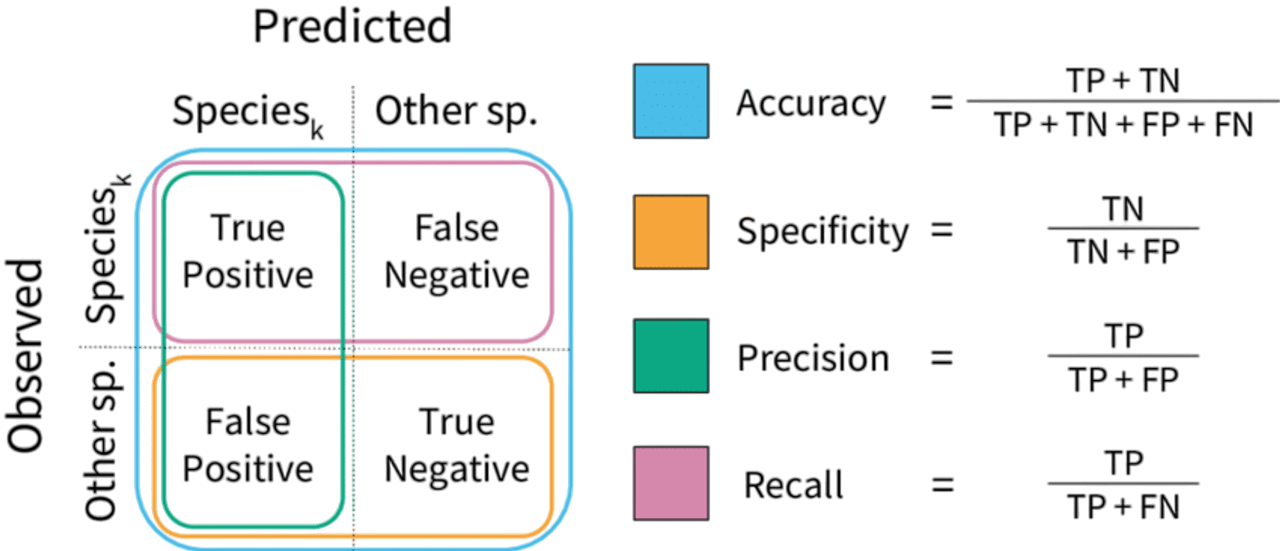
However, accuracy can be deceptive in imbalanced datasets. For instance, in a cancer detection model where only 2% of patients have cancer, predicting “no cancer” for everyone gives 98% accuracy but is practically useless. The F1 score is better in such cases because it directly evaluates how well the model balances precision and recall, making it more robust to class imbalance.
When to Use F1 Score
You should consider using the F1 score over accuracy when: the dataset is imbalanced, and both false positives and false negatives carry significant consequences. Overview of ML on AWS highlights how cloud-native tools like SageMaker enable scalable model evaluation using metrics like F1 Score, precision, and recall especially in domains like fraud detection or anomaly classification.
- You’re dealing with imbalanced datasets
- Both false positives and false negatives are important
- You’re working on tasks like fraud detection, disease classification, spam detection, or search relevance
The F1 score is especially valuable in real-world decision-making scenarios, where making the wrong prediction has significant consequences.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
ROC-AUC vs F1 Score
Both F1 and ROC-AUC are common evaluation metrics in classification tasks, but they serve different purposes. Keras vs TensorFlow frameworks support these metrics natively Keras simplifies implementation with high-level APIs, while TensorFlow offers granular control for custom metric tracking and optimization across complex pipelines.
- F1 Score: Best used when you care about actual class predictions, not just probabilities. It’s threshold-dependent and optimized for discrete decisions.
- ROC-AUC: Evaluates the model’s ability to rank positive instances higher than negative ones. It is threshold-independent and useful for evaluating probabilistic classifiers.
Use F1 score for imbalanced datasets where you need to minimize both false positives and false negatives. Use ROC-AUC when evaluating ranking quality or working with probabilistic outputs.
Case Studies and Use Cases
- Healthcare (Cancer Detection): A model for cancer detection must have high recall to ensure no cancer cases go undetected. However, a high recall may come at the cost of precision. Using the F1 score ensures that both are balanced, providing a robust metric for healthcare applications.
- Spam Detection: False positives (marking real emails as spam) are harmful, as are false negatives (allowing spam through). The F1 score balances these issues effectively.
- Fraud Detection: This is typically a highly imbalanced problem. The F1 score allows financial institutions to evaluate how well models are detecting fraud while minimizing false alarms.
- Information Retrieval: Search engines use F1 score to balance precision (returning relevant documents) and recall (returning all relevant documents).
- Customer Churn Prediction: Identifying customers at risk of leaving (churn) is vital for retention. The F1 score helps companies ensure that predictions are both accurate and actionable.
- Balancing Metrics in Practice: In practical applications, the F1 score often works in combination with other metrics. For example, in a production system, engineers may look at:
Conclusion
The F1 Score in Machine Learning is a powerful metric for classification models, especially when the dataset is imbalanced or the cost of false negatives and false positives is high. Unlike accuracy, it provides a more complete picture by combining both precision and recall. Machine Learning Training highlights how metrics like the F1 Score offer deeper insights into model performance, especially in imbalanced datasets. It’s widely applicable in critical domains such as healthcare, fraud detection, spam filtering, and information retrieval. By mastering the F1 score and integrating it with practical tools like Scikit-learn, machine learning practitioners can build more trustworthy and effective models. Whether you’re tuning thresholds, comparing models, or making real-world decisions, the F1 score is an essential component in your evaluation toolkit.

