
Last updated on 06th Aug 2025| 13093
- Introduction to Boosting
- Concept of AdaBoost in Machine Learning
- Weak Learners and Decision Stumps
- AdaBoost Algorithm Step-by-Step
- Weight Adjustment Mechanism
- Mathematical Formulation
- Application in Classification
- Overfitting and Regularization
- Real-World Use Cases
- Conclusion
Introduction to Boosting
Boosting is an ensemble technique in machine learning that combines multiple weak learners to form a strong learner with improved predictive performance. The core idea is to sequentially train models, each compensating for the errors of its predecessor, thereby reducing bias and variance in the final model a foundational strategy in Machine Learning Training. Unlike bagging, where models are trained independently on random subsets of data, boosting trains learners in a sequence where each learner focuses more on the misclassified data points from previous learners. This approach aims to minimize the overall error by iteratively improving on difficult examples. Boosting machine learning algorithms are widely used because of their ability to convert weak models, often just slightly better than random guessing, into a powerful predictive model. Examples include AdaBoost, Gradient Boosting Machines (GBM), XGBoost, and LightGBM. The boosting concept is crucial in classification and regression problems where the base learner is often a simple model like a decision stump (a tree with just one split). By combining many such learners, boosting achieves high accuracy and robustness. Among boosting algorithms, AdaBoost (Adaptive Boosting), introduced by Freund and Schapire in 1995, is one of the earliest and most influential methods. It laid the groundwork for many modern boosting techniques and remains a popular and effective algorithm for various machine learning tasks.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Concept of AdaBoost in Machine Learning
AdaBoost in Machine Learning is a boosting algorithm that adaptively adjusts the weights of training instances based on how difficult they are to classify. The main idea is to pay more attention to the samples misclassified by earlier weak learners, allowing subsequent learners to focus on the “hard” cases. The term “adaptive” in AdaBoost refers to this process of adapting the weights of data points as the training progresses. Initially, all samples are assigned equal weights a mechanism often highlighted in Machine Learning Tools for boosting-based model optimization. After training the first weak learner, AdaBoost increases the weights of misclassified samples and decreases the weights of correctly classified ones. The next learner is then trained on this weighted dataset, emphasizing the challenging cases.
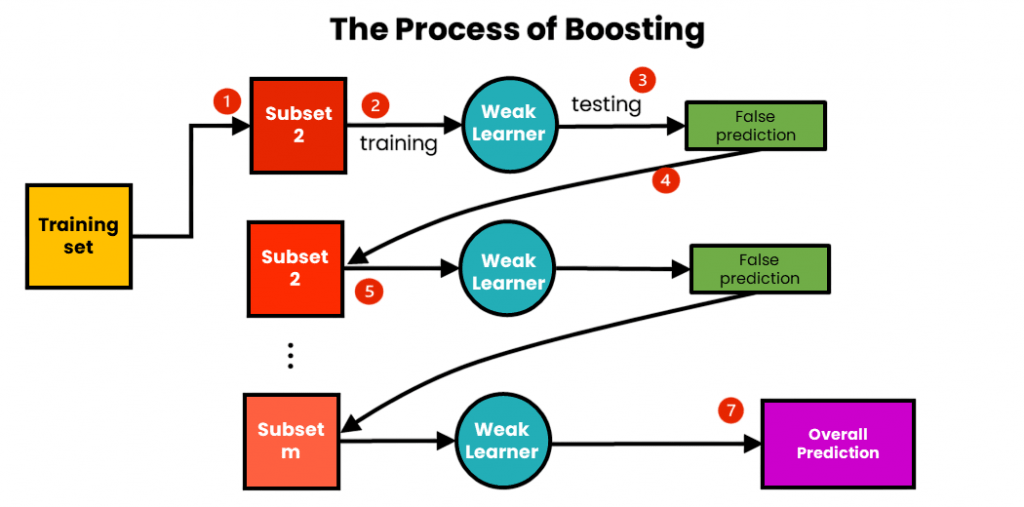
AdaBoost combines the predictions of all weak learners through a weighted majority vote (for classification) or weighted sum (for regression). The weight assigned to each learner depends on its accuracy; better learners have a greater influence on the final prediction. In classification problems, AdaBoost typically uses simple weak learners called decision stumps shallow trees with one split which on their own are only slightly better than random guessing but collectively produce a highly accurate model. AdaBoost’s ability to focus on misclassified points helps it reduce bias significantly while also controlling variance. Its adaptive nature and simplicity make it effective for both binary and multiclass classification tasks.
Weak Learners and Decision Stumps
A weak learner is a model that performs only slightly better than random chance. AdaBoost primarily uses weak learners to build a strong predictive model. The classic weak learner for AdaBoost is the decision stump, which is a decision tree with only one level, that is, it makes a prediction based on a single feature threshold. Despite its simplicity and low accuracy alone, the decision stump is fast to train and provides the flexibility required by AdaBoost to iteratively improve a concept often introduced in Best Deep Learning Books when discussing ensemble foundations.
Why use decision stumps?
- Simplicity: They are easy to understand and implement.
- Speed: Training is very fast compared to deeper trees.
- Complementarity: Each stump focuses on a different aspect of the data, allowing AdaBoost to combine many diverse stumps effectively.
Weak learners in AdaBoost do not have to be decision stumps exclusively. In practice, other classifiers like linear models, small neural networks, or any model slightly better than chance can be used, as long as they are sensitive to weighted samples. The ensemble formed by AdaBoost can be thought of as a weighted combination of many weak learners, where each learner’s contribution is based on its performance. This approach turns a set of individually poor models into a powerful learner.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
AdaBoost Algorithm Step-by-Step
The AdaBoost in Machine Learning algorithm follows an iterative procedure. Here is a step-by-step description of the algorithm for binary classification an essential entry in Machine Learning Algorithms used to enhance weak learners through adaptive reweighting.
Initialization:
- Start with a training dataset of N samples: (x1,y1),(x2,y2),…,(xN,yN)(x_1, y_1), (x_2, y_2), …, (x_N, y_N)(x1,y1),(x2,y2),…,(xN,yN), where yi∈{−1,+1}y_i \in \{-1, +1\}yi∈{−1,+1}.
- Initialize weights wi=1Nw_i = \frac{1}{N}wi=N1 for each sample. Each sample has equal importance initially.
Iteration (for m=1m = 1m=1 to MMM, number of weak learners):
- Train: weak learners hmh_mhm using the weighted training data.
- Calculate weighted error for hmh_mhm: ϵm=∑i=1Nwi⋅1(hm(xi)≠yi)∑i=1Nwi\epsilon_m = \frac{\sum_{i=1}^N w_i \cdot \mathbf{1}(h_m(x_i) \neq y_i)}{\sum_{i=1}^N w_i}ϵm=∑i=1Nwi∑i=1Nwi⋅1(hm(xi)=yi) where 1(⋅)\mathbf{1}(\cdot)1(⋅) is the indicator function (1 if the prediction is wrong, 0 otherwise).
- Compute learner weight αm\alpha_mαm: αm=12ln(1−ϵmϵm)\alpha_m = \frac{1}{2} \ln\left(\frac{1 – \epsilon_m}{\epsilon_m}\right)αm=21ln(ϵm1−ϵm) Learners with lower error get higher weight.
- Update sample weights: wi←wi×exp(−αmyihm(xi))w_i \leftarrow w_i \times \exp(-\alpha_m y_i h_m(x_i))wi←wi×exp(−αmyihm(xi)) Misclassified samples receive higher weights.
- Normalize weights: so that ∑iwi=1\sum_i w_i = 1∑iwi=1.

Weight Adjustment Mechanism
AdaBoost’s main strength comes from its unique weight adjustment method. This method focuses learning efforts on difficult classification examples. At first, the algorithm gives equal weights to all training samples. As it moves forward, it places much more importance on samples that were misclassified. When a weak learner makes a mistake, the algorithm significantly raises that data point’s weight a dynamic adjustment central to Machine Learning Training strategies like AdaBoost. This change urges the next learners to pay more attention to these tough cases. This flexible weighting system helps the model repeatedly focus on harder samples. This allows AdaBoost to reach impressive accuracy with relatively simple weak learners. By raising weights for misclassified points, the algorithm builds a strong process that gradually improves its learning. However, practitioners should be careful about overfitting, especially when the algorithm gives too much weight to outliers. They can manage this risk with methods like early stopping and regularization.
Mathematical Formulation
AdaBoost in Machine Learning algorithm that uses a unique method to minimize the exponential loss function during training. The algorithm selects weak learners and their weights in a series of steps to create a combined model F(x) that effectively reduces classification errors. Researchers find the update rule for learner weights by optimizing the weighted error, using a logarithmic formula that balances model complexity and performance. The exponential loss function is related to the logistic loss in logistic regression, which allows researchers to see AdaBoost as an additive modeling technique in function space a perspective often explored in Machine Learning Projects focused on ensemble learning. The exponential loss function forward stagewise method lets the algorithm gradually add weak learners that consistently lower residuals, resulting in a strong and flexible classification model with great generalization abilities.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Application in Classification
AdaBoost is widely used in classification problems due to its high accuracy and simplicity. It is effective in various domains such as:
- Face detection: AdaBoost was one of the first algorithms to power real-time face detection in computer vision. Viola-Jones face detector uses AdaBoost with Haar-like features as weak learners.
- Spam filtering: Helps identify spam emails by combining weak classifiers focusing on challenging spam examples.
- Medical diagnostics: Used in disease classification where high accuracy and interpretability are important.
- Credit scoring: Combines simple classifiers to predict loan defaults.
- Text classification and sentiment analysis.
AdaBoost handles binary classification naturally, but it can be extended to multiclass problems via techniques such as:
Overfitting and Regularization
Although AdaBoost is less prone to overfitting than many other algorithms, it can still overfit, especially with noisy data or very large numbers of iterations a behavior that can be analyzed through error dynamics and weight distributions within a Matrix in Machine Learning framework.
Reasons for overfitting in AdaBoost:
- Increasing weights on noisy or mislabeled samples leads to memorization.
- Too many weak learners can model noise rather than signal.
Regularization techniques:
- Early stopping: Stop training when performance on validation data starts to degrade.
- Limiting weak learner complexity: Using decision stumps or shallow trees restricts capacity.
- Learning rate (shrinkage): Introduce a multiplier to αm\alpha_mαm to reduce each learner’s impact (common in gradient boosting).
- Sample reweighting tweaks: Modifications to the weight update step can reduce noise impact.
Recent variants and hybrid models incorporate such regularization methods to improve AdaBoost’s robustness.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Real-World Use Cases
- Face Detection: The Viola-Jones face detection framework famously uses AdaBoost to select and combine weak classifiers based on simple rectangular features. This made real-time face detection practical on consumer hardware.
- Credit Scoring: Banks use AdaBoost ensembles to predict loan defaults by combining simple decision trees trained on weighted customer data, focusing on challenging cases to reduce false negatives.
- Medical Diagnosis: AdaBoost classifiers help diagnose diseases by combining simple diagnostic tests or clinical features, improving accuracy while maintaining model interpretability.
- Spam Detection: Email spam filters leverage AdaBoost to combine many simple text-based classifiers focusing on difficult-to-classify emails, effectively filtering spam.
- Fraud Detection: Financial institutions use AdaBoost to identify fraudulent transactions by emphasizing examples with unusual or suspicious patterns.
- Bioinformatics: In gene expression and protein classification, AdaBoost ensembles combine weak models trained on noisy biological data for robust predictions.
Conclusion
AdaBoost in Machine Learning is a key algorithm in ensemble learning. It stands out by focusing on hard training samples and using simple base learners. Even with the rise of gradient boosting variations, AdaBoost still does well due to its simplicity, speed, and clear theoretical foundation. This is especially true in classification problems where model interpretability is important to researchers. To get the most out of AdaBoost, practitioners should use simple weak learners like decision stumps. They should implement early stopping to avoid overfitting, carefully adjust the number of estimators and learning rate, and consider possible extensions or alternatives when dealing with noisy or complex datasets best practices rooted in Machine Learning Training. In the end, mastering AdaBoost is an important step for professionals and researchers who want to create effective machine learning algorithms that combine performance, efficiency, and clarity.

