
Last updated on 07th Aug 2025| 12057
- Importance of Feature Engineering
- Feature Extraction vs Selection
- Handling Missing Data
- Encoding Categorical Variables
- Normalization and Scaling
- Creating New Features
- Feature Selection Techniques
- Dimensionality Reduction (PCA, LDA)
- Interaction and Polynomial Features
- Automated Feature Engineering Tools
- Conclusion
Importance of Feature Engineering
Feature Engineering for Machine Learning is the process of transforming raw data into meaningful features that can be effectively used by machine learning algorithms. It is often cited as the most critical step in the data science pipeline, with the potential to significantly enhance model accuracy and performance. Machine Learning Training ensures that models learn meaningful patterns from data, enabling robust predictions and scalable deployment. In fact, high-quality feature engineering can outperform sophisticated algorithms, whereas poorly chosen features can severely limit model success. The essence of Feature Engineering for Machine Learning lies in understanding the domain and creatively generating inputs that improve the predictive capability of the model.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Feature Extraction vs Selection
Data scientists transform raw data through feature engineering, which is a key preprocessing technique that uses two main approaches, feature extraction and feature selection. In feature extraction, they convert original data into more meaningful forms. For example, they can derive detailed time-based components from timestamps by extracting indicators for the day, month, and whether it is a weekend. Techniques like Bagging vs Boosting in Machine Learning further enhance model performance by optimizing how features are used during training. On the other hand, in feature selection, they find and keep only the most useful attributes. They systematically remove redundant or irrelevant variables using methods like correlation analysis and mutual information assessment. By using these connected techniques, data scientists improve and refine datasets. This ultimately boosts the predictive power and efficiency of machine learning models by creating more useful and targeted input features.
Handling Missing Data
Missing data is a common issue in real-world datasets, and improper handling can lead to biased or inaccurate models. What Is Machine Learning introduces foundational techniques for addressing missing values, including:
- Deletion: Removing rows or columns that contain a significant amount of missing data. This is suitable only when the missingness is random and the amount is negligible.
- Imputation: Filling missing values using strategies like mean, median, mode, or using advanced methods like k-nearest neighbors, regression models, or interpolation.
- Predictive Imputation: Predicting the missing values using other variables in the dataset.
- Indicator Variables: Creating binary flags to indicate missing entries, which can be useful if the missingness carries information.
The choice of strategy depends on the nature of the data and the context of the problem.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Encoding Categorical Variables
Since most machine learning algorithms require numerical inputs, categorical data must be encoded:
- Label Encoding: Assigns a unique integer to each category. Best for ordinal data where order matters.
- One-Hot Encoding: Converts each category into a binary feature. Ideal for nominal data but can lead to high dimensionality with many categories.
- Binary Encoding and Hashing: Useful for high-cardinality features to reduce dimensionality.
- Target Encoding: Replaces categories with the mean target value for that category, typically used in regression tasks.
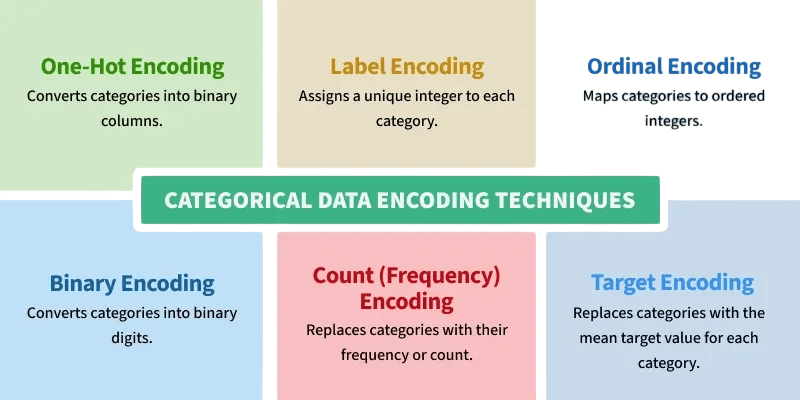
Choosing the right encoding technique ensures that categorical variables are correctly interpreted by the algorithm.

Normalization and Scaling
In machine learning, data scientists use feature scaling to improve model performance, especially during training for algorithms like k-NN, SVM, and neural networks. Researchers have developed various scaling techniques that provide different benefits in data preprocessing. Min-Max Scaling adjusts features to a standard 0–1 range, while Standardization centers data around the mean with a standard deviation of 1. For datasets with significant outliers, data scientists use the Robust Scaler as a strong alternative by applying the median and interquartile range. Machine Learning Training covers these preprocessing techniques to ensure models receive well-conditioned inputs for optimal learning. These methods help machine learning practitioners make sure that features contribute fairly during model training. This approach ultimately improves the accuracy and reliability of machine learning algorithms by preventing any single feature from overly influencing the model’s results.
Creating New Features
Data scientists improve machine learning models by creating features that include domain knowledge through careful feature engineering. They use various techniques, including:
- Developing mathematical combinations such as arithmetic operations to gain new insights.
- Extracting time-related features from date-time variables.
- Calculating detailed statistical metrics through data aggregations.
They can also create useful text features like word count and sentiment scores, as well as domain-specific metrics such as credit utilization ratios or BMI calculations. By carefully crafting these features, data scientists enhance model clarity and accuracy. This process transforms raw data into valuable predictive elements that better capture complex relationships and underlying patterns than traditional modeling methods.
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Feature Selection Techniques
Selecting the most relevant features is crucial to improve model interpretability and avoid overfitting. Decision Trees in Machine Learning naturally support feature selection by evaluating split criteria and importance scores. Common techniques include:
- Filter Methods: Use statistical tests (correlation, chi-squared, ANOVA) to evaluate the relationship between features and the target.
- Wrapper Methods: Use model performance to assess subsets of features (e.g., Recursive Feature Elimination).
- Embedded Methods: Incorporate feature selection into the model training process (e.g., Lasso regression, tree-based models).
- Univariate Selection: Selecting best features using univariate statistical tests.
Effective feature selection reduces model complexity and training time.
Dimensionality Reduction (PCA, LDA)
When working with high-dimensional data, reducing the number of features helps in mitigating overfitting, improving visualization, and speeding up computations:
- PCA (Principal Component Analysis): Unsupervised method that transforms features into orthogonal components, capturing the most variance.
- LDA (Linear Discriminant Analysis): Supervised method that projects features in a way that maximizes class separation.
- t-SNE and UMAP: Non-linear techniques useful for data visualization.
These methods are particularly useful when dealing with hundreds or thousands of features.
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Interaction and Polynomial Features
Creating interaction terms or polynomial combinations of features allows models to capture non-linear relationships an approach often emphasized in Pattern Recognition and Machine Learning when enhancing model expressiveness and predictive power.
- Interaction Terms: Multiply two or more features to model interdependencies (e.g., income * education).
- Polynomial Features: Include square or cube terms to capture curvature in the data.
These techniques are especially useful in linear models to boost expressiveness without switching to complex models.
Automated Feature Engineering Tools
Manual feature engineering is time-consuming. Several tools have been developed to automate the feature engineering task:
- FeatureTools: Performs deep feature synthesis on relational data.
- TSFresh: Automatically extracts features from time-series datasets.
- AutoFeat: Useful for extracting new features from numerical datasets.
- AutoML Platforms: Google AutoML, H2O.ai, DataRobot incorporate feature engineering in their workflows.
While automated feature engineering tools accelerate development, they may not replace the insight that comes from domain expertise.
Conclusion
Feature Engineering for Machine Learning remains one of the most impactful tasks in the machine learning algorithms workflow. It requires creativity, domain knowledge, statistical understanding, and experimentation. From handling missing values and encoding categories to creating interaction terms and applying dimensionality reduction, every step in Feature Engineering for Machine Learning shapes how well your model will perform making it a cornerstone of effective Machine Learning Training. As tools and automation evolve, the human ability to understand data contextually and engineer meaningful features will continue to be a decisive factor in AI success.

