Last updated on 21st Mar 2025| 6092
- Introduction to AWS Big Data Services
- Key Features of AWS Big Data Solutions
- Amazon S3 and Data Storage
- AWS Glue for Data Transformation
- Amazon Redshift for Data Warehousing
- Amazon EMR for Big Data Processing
- AWS Athena for Serverless Querying
- Machine Learning with AWS Big Data
- Security and Compliance for Big Data on AWS
- AWS Big Data vs Traditional Data Processing
- Cost Optimization Strategies for AWS Big Data
- Getting Started with AWS Big Data.
- Conclusion
Introduction to AWS Big Data Services
Data is one of the greatest assets for companies in various industries today. Processing, storing, and analyzing vast amounts of data have become essential to gain insights, enhance decision-making, and retain a competitive advantage. Amazon Web Services (AWS) offers big data services, enabling companies to process large amounts of data effortlessly, scale, and flexibly. AWS provides extensive, integrated services to help businesses derive value from their big data through storage, transformation, analytics, machine learning, and others. With its powerful tools and scalability, AWS supports businesses in tackling complex data challenges and drives operational efficiencies. Additionally, AWS’s secure environment ensures that sensitive data remains protected while leveraging advanced analytics for better insights. As the data landscape evolves, AWS continues to innovate, offering cutting-edge solutions for modern businesses.
Key Features of AWS Big Data Solutions
- Managed Services: Many of AWS’s big data solutions are fully managed, so users do not have to worry about maintenance, infrastructure management, or scalability.
- Security and Compliance: AWS provides robust security features, including encryption, IAM (Identity and Access Management), VPC (Virtual Private Cloud), and compliance with numerous regulatory frameworks, such as GDPR, HIPAA, and SOC 2.
- Cost Efficiency: AWS uses a pay-as-you-go model, so businesses pay only for what they use, reducing upfront costs.
- Comprehensive Analytics: With services like Amazon Redshift, AWS Athena, and Amazon EMR, AWS enables users to run complex queries, analyze large datasets, and generate real-time insights.
AWS offers a variety of big data solutions that come with several benefits, including: Scalability: AWS services are designed to scale according to the business’s needs, from small datasets to petabytes of data.
These features enable organizations to handle data-intensive workloads while minimizing complexity and reducing costs.
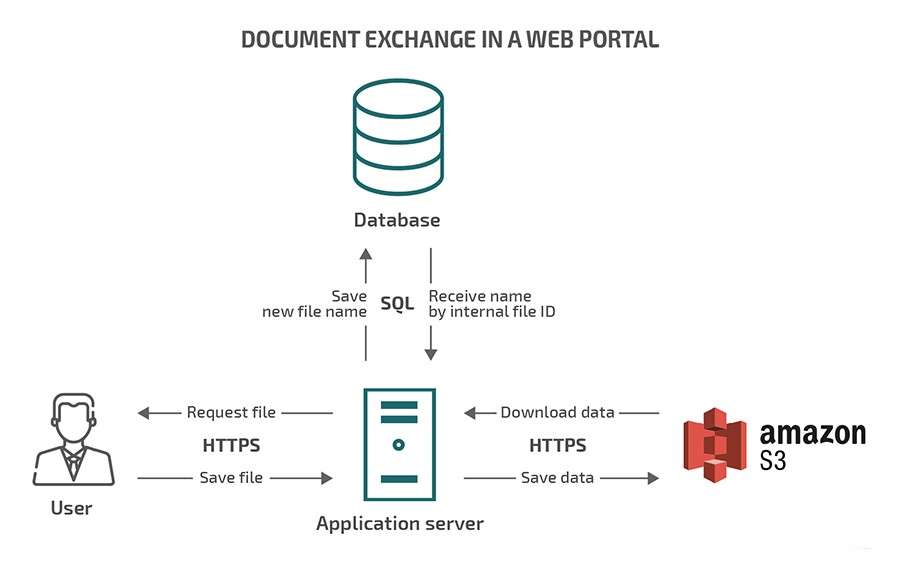
Amazon S3 and Data Storage
Amazon S3 (Simple Storage Service) is AWS’s primary data storage service, designed to handle large amounts of unstructured data. It offers highly scalable, durable, and low-cost storage, making it ideal for big data workloads. S3 can store virtually unlimited amounts of data, providing the scalability needed for modern applications. With 99.999999999% durability and high availability, S3 ensures that data is protected and always accessible, as it stores data across multiple geographic regions. S3 also supports robust data security with encryption for both rest and transit, along with access control policies and detailed logging capabilities. Moreover, it integrates seamlessly with other AWS services like AWS Glue, Redshift, and Athena, enabling powerful data analytics and transformation workflows. By serving as a central storage hub, S3 plays a vital role in large-scale data pipelines, ensuring data is easily accessible and ready for processing.
AWS Glue for Data Transformation
- Automated Schema Discovery: Glue can automatically detect and catalog metadata, reducing the need for manual configuration.
- Data Transformation: Glue allows you to write Python or Scala scripts to perform data transformations such as filtering, mapping, and aggregating.
- Serverless: Glue is fully serverless, meaning users do not have to manage infrastructure, simplify scaling, and reduce costs.
- Integration: AWS Glue integrates with several AWS services, such as S3, Redshift, and Athena, making it easy to move and transform data between different platforms.
AWS Glue is a fully managed ETL (Extract, Transform, Load) service that simplifies preparing and transforming data for analytics. It is designed to handle data in various formats and from multiple sources, making it an essential tool for big data workflows.
Key Features of AWS Glue:
AWS Glue is a powerful tool for transforming data stored in Amazon S3 and preparing it for analysis in services like Redshift or querying via Athena.

Develop Your Skills with AWS Certified Big Data Specialty Online Training
Weekday / Weekend BatchesSee Batch DetailsAmazon Redshift for Data Warehousing
Amazon Redshift is a fast, scalable data warehouse service designed to run complex queries and analyze large datasets efficiently. It handles both structured and semi-structured data and is optimized for analytics workloads. Redshift uses columnar storage, which improves query performance, especially for analytical tasks, by storing data in columns rather than rows. The service also leverages Massively Parallel Processing (MPP) to distribute tasks across multiple nodes, enabling the rapid processing of vast amounts of data. Redshift is highly scalable, allowing businesses to scale resources up or down depending on their specific workload requirements. Integration with other AWS services, such as S3, AWS Glue, AWS Lambda, and AWS Athena, further enhances its ability to process and analyze data seamlessly. Redshift is particularly beneficial for organizations that need to run high-performance, complex queries on large datasets, making it a go-to solution for data-driven businesses. Its flexibility and power make it an essential tool for unlocking valuable insights and driving decision-making.
Amazon EMR for Big Data Processing
- Key Features of Amazon EMR:
- Managed Clusters: Amazon EMR automatically provisions and scales clusters for big data processing, reducing the complexity of managing clusters.
- Scalability: Users can scale EMR clusters up or down based on workload requirements, making it highly flexible.
- Cost-Effective: Since you pay only for the compute and storage resources you use, EMR provides a cost-efficient way to process big data.
- Integration: EMR integrates with various AWS services, including Amazon S3, Amazon Redshift, and AWS Glue.
- Amazon SageMaker: A fully managed service for building, training, and deploying scale-based machine learning models.
- AWS Deep Learning AMIs: Pre-configured Amazon Machine Images (AMIs) for deep learning applications, enabling faster development of machine learning models.
- AWS Lambda: This can trigger machine learning models and workflows in a serverless environment.
- Scalability: AWS offers unlimited scalability, while traditional systems may struggle to scale as data grows.
- Cost-Effectiveness: AWS uses a pay-as-you-go pricing model, eliminating the need for significant upfront investment in hardware and infrastructure.
- Speed: AWS provides services that enable faster data processing, analysis, and machine learning, reducing time-to-insight.
- Flexibility: AWS services are highly flexible and can be integrated with other cloud and on-premises solutions.
- Management: AWS offers fully managed services like Amazon Glue, Redshift, and Athena, significantly reducing operational overhead compared to traditional systems.
- Create an AWS Account: Sign up for an AWS account to access the services.
- Familiarize Yourself with Core Services: Learn about S3, Redshift, Glue, and Athena, which are foundational for big data processing.
- Explore AWS Training Resources: AWS provides free training and certifications for big data solutions.
- Hands-On Practice: Set up simple data pipelines and experiment with querying data on S3 using Athena or process data using EMR.
- Leverage AWS Documentation: AWS offers comprehensive documentation and tutorials to help you learn how to use their services.
Amazon EMR (Elastic MapReduce) is a cloud-native big data processing service that enables users to process large volumes of data quickly and efficiently using popular open-source tools such as Apache, Hadoop, Spark, Hive, and HBase.
EMR is commonly used for big data processing tasks such as batch processing, stream processing, and machine learning.
AWS Athena for Serverless Querying
Amazon Athena is a serverless, interactive query service that allows users to run SQL queries on data stored in Amazon S3 without the need for infrastructure management. This makes Athena a perfect solution for ad-hoc querying, where users can quickly gain insights from large datasets without the complexity of setting up or managing servers. It supports standard SQL, enabling users to query structured, semi-structured, and unstructured data with ease, making it accessible for both technical and non-technical users. Athena integrates directly with Amazon S3, meaning that users can query data where it resides, without having to move or duplicate it to other services. One of Athena’s standout features is its cost-efficiency, as it charges only for the amount of data scanned during the query, making it an ideal choice for organizations that need occasional, cost-effective queries. Whether used for quick analysis or deeper data exploration, Athena offers a powerful, flexible, and low-maintenance solution for querying large datasets. Its serverless nature and seamless integration with S3 further enhance its value for big data analytics.
Machine Learning with AWS Big Data
AWS also provides machine learning services that integrate with its big data solutions, allowing users to build, train, and deploy machine learning models on big data.
Key Services:
Machine learning models can be built and trained on large datasets stored in Amazon S3 and processed using Amazon EMR or AWS Glue. Amazon SageMaker is an excellent choice for running these models in a scalable and managed environment.
Security and Compliance for Big Data on AWS
Security is a critical component of big data solutions, and AWS provides a comprehensive set of tools and features to ensure that your data is protected and compliant with industry standards and regulations. AWS offers encryption both at rest and in transit for data stored in services like S3, Redshift, and EMR, ensuring the confidentiality and integrity of your data. Through AWS Identity and Access Management (IAM), organizations can manage access to AWS resources, defining fine-grained permissions and enforcing security policies at various levels. AWS’s broad compliance certifications, including HIPAA, GDPR, SOC 2, and ISO 27001, ensure that businesses in highly regulated industries can trust AWS to meet their security and regulatory requirements. In addition, AWS provides network security solutions such as Virtual Private Clouds (VPCs), security groups, and firewalls, safeguarding big data workloads from unauthorized access. With continuous monitoring and the ability to adapt to evolving security standards, businesses can rely on AWS to deliver a secure, compliant infrastructure for their big data needs.
AWS Big Data vs Traditional Data Processing
AWS’s big data services offer several advantages over traditional on-premises data processing solutions:
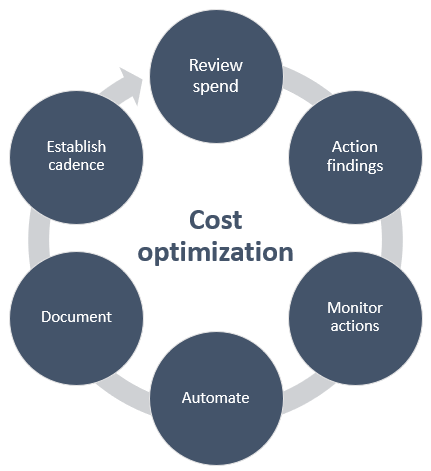
Cost Optimization Strategies for AWS Big Data
While AWS offers highly scalable and robust big data solutions, cost optimization is crucial to ensure resources are used efficiently and to prevent unnecessary expenses. One key strategy is right-sizing, which involves selecting the appropriate instance sizes for big data workloads to avoid over-provisioning and excessive costs. Another effective approach is utilizing Reserved Instances for services like Redshift or EMR, which allows for significant savings on long-term usage commitments. For non-time-sensitive processing tasks, Spot Instances can be leveraged to take advantage of lower pricing, reducing costs while maintaining flexibility. Additionally, implementing data lifecycle policies in Amazon S3 helps automatically archive or delete older data, significantly reducing storage costs over time. By combining these strategies, businesses can optimize their big data solutions on AWS while minimizing unnecessary expenditures and maintaining high performance.
Getting Started with AWS Big Data
To get started with AWS big data services:
By following these steps, you can begin working with AWS’s powerful big data solutions and fully utilize their capabilities.
Conclusion
In conclusion, AWS provides an extensive suite of tools and services that enable businesses to efficiently store, process, and analyze large volumes of data. By leveraging services like S3, Glue, Redshift, and EMR, companies can unlock the potential of their data while benefiting from AWS’s scalability, flexibility, and cost-efficiency. With advanced features such as real-time data processing, seamless integration with machine learning, and automated data pipelines, AWS empowers organizations to make data-driven decisions faster. Additionally, the robust security and compliance features ensure that data remains protected while meeting industry regulations. As businesses continue to rely on data to drive innovation, AWS remains a top choice for cloud computing and big data solutions.




