Last updated on 26th Feb 2025| 5530
- Introduction to Azure Data Factory
- Understanding Data Flow Concepts
- Debugging and Troubleshooting Data Pipelines
- Creating and Managing Data Pipelines
- Optimizing Costs in Azure Data Factory
- Integrating with On-Premises and Cloud Data Sources
- Strengthening Data Governance and Compliance
- Security and Performance Optimization
- Best Practices for Data Transformation
- Enhancing Analytics with Machine Learning and AI
- Conclusion
Introduction to Azure Data Factory
Azure Data Factory (ADF) is a cloud-based data integration service that allows you to create, schedule, and orchestrate data pipelines for moving and transforming data across various sources and destinations. Microsoft Azure Training provides a seamless environment to handle large-scale data processing and enables the transfer and transformation of data from on-premises to cloud platforms or between multiple cloud environments. Azure Data Factory is often used for ETL (Extract, Transform, Load) operations, and building end-to-end data workflows. With its ability to integrate with numerous data storage services, both on-premises and in the cloud, ADF is a powerful tool for organizations dealing with large volumes of data from diverse sources.
Understanding Data Flow Concepts
Data Flow in Azure Data Factory refers to the process of moving and transforming data from one or more sources to a destination, often involving transformations to meet specific business needs. The key concepts in ADF’s data flow are:
Source: The data source from which data is read. It can be a database, a file in cloud storage, or any other supported format.
Transformation: This is the step where data is processed and altered according to business logic, such as filtering, aggregating, and sorting data. Azure Data Factory provides several built-in transformations like joins, lookups, derived columns, and expressions.
Sink: The destination where the transformed data is stored. This could be a database, data lake, or a data warehouse in the cloud, among others.
Control Flow: In ADF, control flow defines the execution sequence of activities like data movement, transformation, and triggers. It can be orchestrated using pipelines that allow you to group different tasks together to execute them in a specific order.
Debugging and Troubleshooting Data Pipelines
Ensuring the smooth execution of data pipelines in Azure Data Factory requires effective debugging and troubleshooting strategies. ADF provides built-in monitoring tools that allow users to track pipeline executions and diagnose failures. Logs can be analyzed using Azure Monitor, Log Analytics, or Application Insights for deeper error insights. The Debug Mode in ADF enables users to test and validate data flows before Edge Computing with AWS Greengrass, offering real-time execution visibility and allowing inspection of intermediate data to identify potential issues. Implementing failure-handling mechanisms such as retry policies and error-handling logic using “If Condition” and “Try-Catch” patterns ensures resilience against transient failures. Performance diagnostics can be enhanced by analyzing execution logs, identifying transformation bottlenecks, and optimizing pipeline efficiency using metrics like execution time, data volume, and resource consumption.
Gain in-depth knowledge of Microsoft Azure by joining this Microsoft Azure Training now.
Creating and Managing Data Pipelines
Data Pipelines are the backbone of Azure Data Factory, enabling the orchestration of data processing tasks. Creating and managing pipelines involves the following steps:
-
Pipeline Creation:
- Use the Azure Data Factory interface to create a new pipeline. Understanding AWS NAT Gateway consist of activities like data movement, data transformation, and orchestration activities.
- You can drag and drop activities to create a logical flow that defines how data is processed. Adding Activities:
- Activities in a pipeline can range from moving data between sources and sinks, to running data flow tasks, executing stored procedures, and managing the flow using triggers.
- Copy Activity is a common task used for data movement, and Data Flow Activity is used for data transformations. Parameterization:
- Pipelines can be parameterized to allow reusability and flexibility. Parameters can be defined at the pipeline level, allowing for dynamic control over the execution of different activities based on input values. Monitoring and Managing Pipelines:
- Once a pipeline is created, it can be scheduled to run at specified intervals or triggered on-demand.
- Azure Data Factory provides a Monitoring Dashboard where users can track pipeline runs, view success or failure details, and diagnose issues. Triggers:
- Triggers in ADF help automate the execution of pipelines based on events like the arrival of new data, specific times, or other custom conditions.
- Cloud Sources: ADF integrates with a variety of cloud storage services such as Azure Blob Storage, Azure SQL Database, Azure Data Lake, Amazon S3, Google Cloud Storage, and more. Data movement between cloud services is seamless, and transformations can be executed on cloud-based data directly.
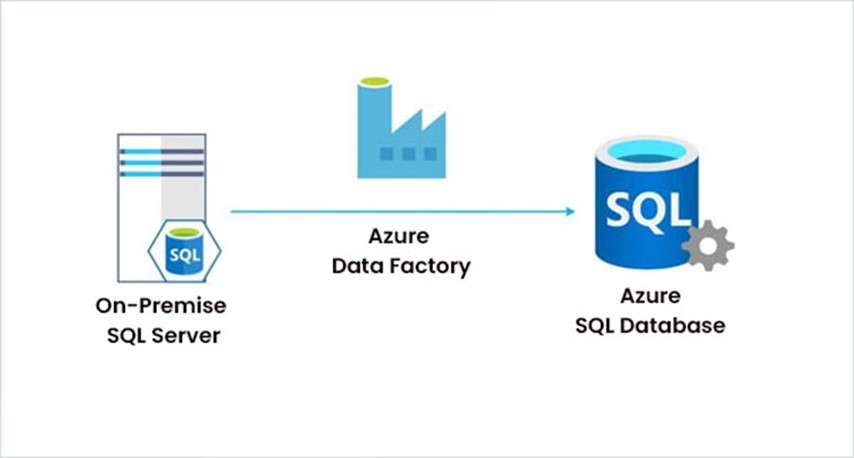
- On-Premises Data Sources: For data residing in on-premises systems, ADF can connect using the Self-hosted Integration Runtime (IR). The IR acts as a bridge to securely transfer data between on-premises systems and the cloud. ADF supports integration with on-premises databases, file systems, and custom applications through the IR.
- Hybrid Integrations: ADF enables hybrid integration, where data can be moved between Understanding the Devops Periodic Table and on-premises sources. For example, you might pull data from an on-premises SQL Server database, transform it in the cloud, and store the result in Azure SQL Database.
- Data Encryption:Azure Data Factory ensures that data in transit is encrypted using TLS and data at rest is encrypted with Azure Storage encryption.
- Access Control: Azure AD integration allows for role-based access control (RBAC), ensuring that only authorized users can manage and execute pipelines.
- Secure Data Movement: The Self-hosted Integration Runtime can be used to securely move data from on-premises sources without exposing sensitive information to the public internet.
- Parallel Processing: ADF supports parallel processing, enabling tasks such as copying data from source to sink across multiple threads, which significantly improves performance for large data volumes.
- Data Skipping: When copying data from Understanding Arns in AWS, ADF can use data partitioning to only move the necessary portions, optimizing performance.
- Data Movement Best Practices: Choose the right Integration Runtime for the task to ensure that the right resources are utilized for processing, especially when working with large datasets.
- Caching: For repeated transformations, consider using data caching to store intermediate results and avoid redundant computations.
- Azure Data Factory seamlessly integrates with machine learning and advanced analytics tools, enabling AI-driven data transformation and intelligent decision-making.
- It connects with Azure Machine Learning (AML) to automate model training and inference, allowing businesses to incorporate predictive analytics into their data pipelines.
- Azure Data bricks offers large-scale data transformation capabilities using Apache Spark, making it easier to process structured and unstructured data efficiently.
- ADF also supports real-time data processing by integrating with Azure Event Hubs and Azure Stream Analytics, enabling event-driven architectures that trigger data transformations as new data arrives.
- Additionally, organizations can leverage ADF’s integration with Power BI for real-time reporting and connect with AWS Security Token Service for scalable data warehousing and predictive modeling.
- These advanced analytics capabilities empower organizations to extract valuable insights and drive data-driven decision-making with minimal manual intervention.
Start your journey in Microsoft Azure by enrolling in this Microsoft Azure Training.
Optimizing Costs in Azure Data Factory
Managing costs effectively in Azure Data Factory is essential for efficient data processing without exceeding budget constraints. ADF follows a pay-as-you-go pricing model, where costs are influenced by pipeline execution, data movement, and data flow compute usage. Understanding Microsoft Azure Training pricing structure helps organizations make informed decisions about their data processing strategies. Cost optimization can be achieved by selecting the appropriate Integration Runtime (IR) tier based on workload requirements, leveraging reserved instances, and minimizing unnecessary data transfers. Performing data transformations closer to the source, utilizing SQL queries, and using cloud-based processing reduce overall expenses. Data compression and partitioning further optimize data movement costs. Azure Cost Management provides tools for tracking expenses, setting budget alerts, and analyzing spending patterns to identify cost-saving opportunities. Regular optimization of underperforming pipelines ensures a cost-efficient data integration strategy.
Integrating with On-Premises and Cloud Data Sources
Azure Data Factory supports integration with both on-premises and cloud-based data sources. Key integration capabilities include:
Strengthening Data Governance and Compliance
Maintaining robust data governance in Azure Data Factory is crucial for ensuring data security, quality, and compliance with industry regulations. ADF integrates with Azure Active Directory (AAD) for role-based access control (RBAC), allowing organizations to restrict unauthorized access through custom role assignments. Data lineage tracking enables businesses to monitor data movement and transformations, which can be further enhanced using Azure Purview for metadata tracking and compliance enforcement. Regulatory compliance with standards like GDPR, HIPAA, and SOC 2 is supported through encryption, access controls, and data masking. Azure Policy can be leveraged to enforce governance rules across data workflows, ensuring compliance is maintained at all levels. Implementing data validation checks and schema drift detection helps maintain data integrity and prevents errors caused by unexpected changes in source data structures.

Security and Performance Optimization
To ensure that data is processed securely and efficiently in Azure Data Factory, consider the following:
-
Security:
Aspiring to lead in Cloud Computing? Enroll in ACTE’s Cloud Computing Master Program Training Course and start your path to success!
Best Practices for Data Transformation
When transforming data, especially for complex operations like aggregation, filtering, and joining, consider using Azure Data Flow. It provides a visually rich design environment for crafting detailed transformations, and it integrates seamlessly with other ADF activities.To improve the performance of data transformations, use broadcasting for smaller datasets and partitioning for large datasets. Partitioning allows you to process data in parallel, reducing overall execution time.Keep data movement to a minimum by performing transformations close to the data source (e.g., using Azure SQL Database’s Stored Procedures or Azure Databricks for more intensive transformations).Implement proper error handling within pipelines to catch any failures during data transformation. This may include retry policies, error logs, and alerts to notify stakeholders of issues.Continuously monitor the execution of data pipelines and optimize based on the data load and transformation complexity. Azure Data Factory provides tools like Data Factory Monitoring to help track pipeline performance and success rates.Azure Data Factory offers a comprehensive platform for orchestrating and automating data workflows. By leveraging its integration capabilities, robust security features, and performance optimization techniques, organizations can efficiently manage and process large datasets for a wide range of analytics, business intelligence, and data management needs.
Preparing for Microsoft Azure interviews? Visit our blog for the best Azure Interview Questions and Answers!
Enhancing Analytics with Machine Learning and AI
Conclusion
Azure Data Factory is a powerful cloud-based data integration service that enables seamless data movement, transformation, and orchestration across diverse sources. By leveraging ADF’s capabilities, organizations can efficiently manage large-scale data workflows for analytics, business intelligence, and Microsoft Azure Training . Effective debugging, monitoring, and troubleshooting ensure smooth pipeline execution, reducing errors and optimizing performance. Strong governance and compliance measures safeguard data security while adhering to industry regulations. Cost management strategies, including optimized resource utilization and efficient data movement, help maintain budget control. Integrating ADF with advanced analytics and machine learning enhances predictive capabilities and real-time insights. By following best practices for data transformation and performance optimization, businesses can streamline data processing. ADF’s scalability and flexibility make it suitable for handling both on-premises and cloud-based data. With automation, monitoring, and intelligent integrations, organizations can drive data-driven decision-making efficiently. Azure Data Factory remains a crucial tool for modern enterprises aiming for efficient, secure, and cost-effective data management.




