
Last updated on 18th Apr 2025| 8776
- Introduction to Cloud Data Ingestion
- Types of Data Ingestion (Batch vs Streaming)
- How Data Ingestion Works in Big Data
- Data Ingestion Tools and Technologies
- Challenges in Data Ingestion and Processing
- Best Practices for Efficient Data Ingestion
- Role of Data Ingestion in Data Engineering
- Real-World Use Cases of Data Ingestion
- Data Ingestion in Cloud Environments (AWS, Azure, GCP)
- Securing Data During Ingestion
- Comparing Data Ingestion Frameworks (Kafka, Flume, NiFi)
- Future of Data Ingestion in Big Data and AI
Introduction to Cloud Data Ingestion
Cloud Data Ingestion refers to the process of collecting and importing data from various sources into a storage or processing system where it can be analyzed and utilized. This data can come from a wide range of sources, including databases, files, applications, sensors, and more. Data ingestion is a crucial first step in the data pipeline, as it serves as the foundation for further data processing, analytics, and decision-making. Data ingestion can be categorized based on how data is collected and moved into the system: batch processing or real-time streaming. Cloud Computing Course requirements of the use case, data ingestion systems may need to handle large volumes of data, process data at different speeds, or support different kinds of sources and formats. With the rise of big data, the importance of efficient and scalable data ingestion systems has grown tremendously, as organizations seek to process and analyze massive amounts of data at high speeds.
Types of Data Ingestion (Batch vs Streaming)
Data ingestion can broadly be divided into two categories based on how data is processed and transferred into a system:
- Batch Data Ingestion: Batch ingestion refers to the process of collecting data in batches and then loading it into a storage or processing system at scheduled intervals. This method works well when the data does not need to be processed in real-time and is typically used for less time-sensitive data processing tasks. Efficient for large volumes of data. Simplifies error handling, as data can be validated in batches. Less complex than real-time ingestion in terms of setup and resources. Not suitable for time-sensitive or real-time analytics. There may be a lag between the time data is generated and when it becomes available for analysis.
- Streaming Data Ingestion: Streaming ingestion, on the other hand, refers to the continuous flow of data into a system as Career in Cloud Computing is generated, typically in real-time. This approach is critical for scenarios where data needs to be processed as soon as it is created or where low-latency processing is required, such as in IoT, financial services, and social media analytics. Enables real-time analytics and decision-making. Suitable for applications requiring immediate feedback (e.g., fraud detection, real-time recommendations). More complex to implement and manage. Requires significant infrastructure and resources to handle high data throughput and low-latency requirements.
Learn how to manage and deploy cloud services by joining this Cloud Computing Online Course today.
How Data Ingestion Works in Big Data
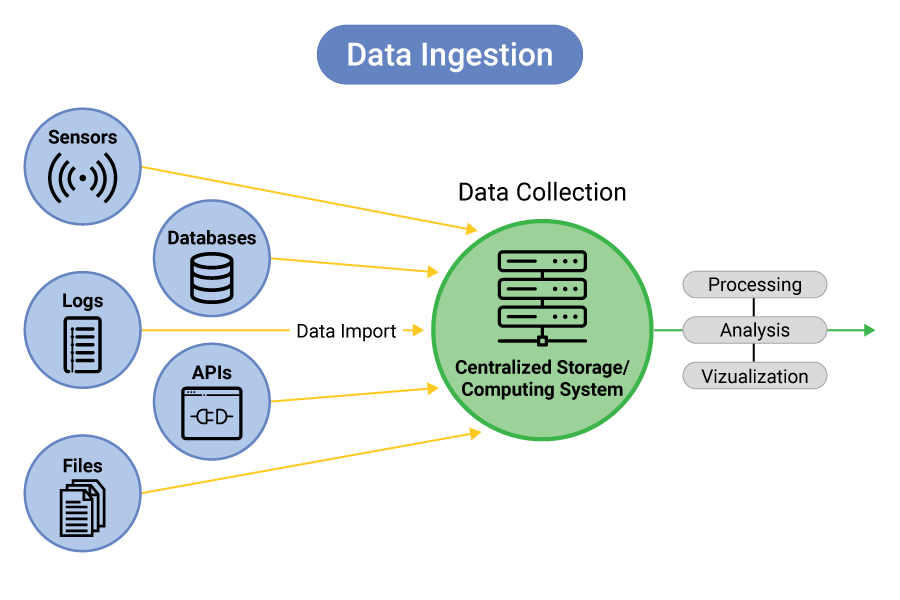
In the big data Cloud Environment , Data Ingestion Tools is a critical process that allows organizations to handle massive volumes of data generated from various sources. Big data ingestion frameworks need to scale and handle high-velocity data streams while ensuring that the integrity of the data is maintained throughout the process. The ingestion process in big data typically involves the following steps:
- Data Collection: This involves collecting data from a variety of sources such as databases, applications, logs, sensors, devices, and external data streams.
- Data Transformation: Once the data is collected, it may need to be transformed to fit the requirements of the Data Science and Cloud Computing (e.g., format conversion, aggregation, enrichment).
- Data Storage: After the data is ingested and processed, it is stored in a data storage system like Hadoop Distributed File System (HDFS), cloud storage, or a data warehouse.
- Data Access: Once the data is stored, it becomes accessible for further processing, analysis, and reporting by various analytics tools, dashboards, or machine learning models.
Data Ingestion Tools and Technologies
There are numerous tools and technologies available for handling data ingestion. Data Ingestion Tools can be broadly classified into batch and real-time ingestion frameworks, each with its own set of features. Some of the most popular tools include:
Batch Ingestion Tools:
- Apache Nifi: A powerful data integration tool that supports both batch and real-time Cloud Data Ingestion. Cloud Computing Course provides an easy-to-use interface for designing data flows and can be used to collect, process, and distribute data from multiple sources.
- Apache Sqoop: Used primarily for importing and exporting data between relational databases and Hadoop, Sqoop is a popular tool for batch ingestion.
- ETL Tools (Extract, Transform, Load): Various ETL tools, such as Talend, Informatica, and Microsoft SQL Server Integration Services (SSIS), offer batch ingestion functionality with transformation capabilities.
Streaming Ingestion Tools:
- Apache Kafka: Kafka is one of the most widely used distributed event streaming platforms. It provides high-throughput, low-latency Data Ingestion Tools and supports stream processing for real-time analytics.
- Apache Flume: Primarily used for log and event data ingestion, Flume is designed for large-scale, distributed data collection.
- Amazon Kinesis: A fully managed streaming platform provided by AWS, Kinesis can handle real-time Cloud Data Ingestion for applications such as analytics, monitoring, and machine learning.
- Google Cloud Pub/Sub: A real-time messaging service that allows data ingestion and messaging in a cloud environment. It enables the delivery of events between systems in real time.

Challenges in Data Ingestion and Processing
While data ingestion is an essential part of big data ecosystems, several challenges need to be addressed for efficient and effective processing:
- Data Quality: Ensuring that the ingested data is clean, accurate, and formatted correctly is crucial. Inconsistent, missing, or erroneous data can impact downstream analytics and decision-making.
- Scalability: As data volumes grow, the ingestion system must scale to handle large datasets and high-throughput streams. Scalability challenges can arise when dealing with massive amounts of data generated by IoT devices, logs, and transactional systems.
- Latency: In real-time data ingestion, managing low latency is a challenge, especially when dealing with high-velocity data streams. It requires powerful infrastructure and effective stream processing techniques.
- Data Integration: Data often comes from multiple sources, and ensuring that it is properly integrated and harmonized can be complex, especially when dealing with unstructured data.
- Security and Compliance: Protecting data during ingestion is critical. Sensitive data must be encrypted during transmission and Introduction to Cloud Computing , and compliance with data protection regulations (e.g., GDPR, HIPAA) must be ensured.
- Data Consistency: Ensuring that the ingested data is consistent and follows the right schema is a challenge, especially when integrating data from different systems with varying formats.
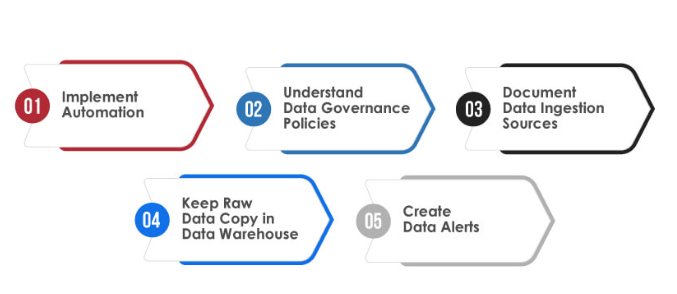
- Automate Data Ingestion: Automating the data ingestion process reduces human error, improves consistency, and ensures that data is ingested on time. Tools like Apache Nifi or AWS Glue can automate this process.
- Use Proper Data Formats: When ingesting data, using appropriate formats (e.g., JSON, Parquet, Avro) can improve efficiency and reduce the complexity of processing.
- Use Data Validation Techniques: Implement data validation techniques to ensure that only clean, accurate, and formatted data is ingested. This reduces issues downstream in analytics and reporting.
- Optimize Data Pipelines: Design data pipelines with scalability in mind. Use parallelism and partitioning where possible to Google Cloud Platform GCP the efficiency of batch and streaming ingestion.
- Monitor Data Ingestion: Continuously monitor the data ingestion process to identify issues and resolve them before they affect data quality or performance.
- Data Encryption: Encrypt sensitive data during ingestion to ensure its security and comply with regulatory standards.
- AWS: AWS provides services like Amazon Kinesis for real-time streaming, AWS Data Pipeline for batch processing, and AWS Glue for data transformation and orchestration.
- Azure: Azure Stream Analytics, Azure Event Hubs, and Azure Data Engineering Factory are commonly used services for real-time and batch AWS Cloudwatch .
- Google Cloud: Google Cloud Pub/Sub and Google Cloud Dataflow provide real-time messaging and data ingestion capabilities, while Google Cloud Dataproc handles batch processing.
- Apache Flume: Flume is best suited for collecting and aggregating log data and event data streams. It is ideal for unstructured data and integrates well with Hadoop.
- Apache NiFi: NiFi provides an easy-to-use interface for designing data flows. It supports both batch and streaming data and can integrate with a variety of sources and destinations.
Unlock your potential in Cloud Computing with this Cloud Computing Online Course .
Best Practices for Efficient Data Ingestion
Efficient data ingestion is critical for ensuring that big data ecosystems run smoothly and provide timely insights. Some best practices for ensuring efficient data ingestion include:
Role of Data Ingestion in Data Engineering
Data ingestion is a core function within data engineering, which involves preparing and processing data for analytics, machine learning, and decision-making. Data engineers design and implement the data pipelines that ingest, clean, and store data. In this context, efficient data ingestion plays a significant role in ensuring that high-quality data is available for downstream processing. Scalable Cloud Data Warehousing with AWS Redshift also ensure that data ingestion systems are scalable, maintainable, and capable of handling the large volumes and variety of data typical in big data Cloud Environment.
Real-World Use Cases of Data Ingestion
Data ingestion is used in a variety of industries and applications, In an Internet of Things (IoT) environment, devices and sensors generate massive data streams that need to be ingested and processed in real-time for applications like predictive maintenance and monitoring. E-commerce platforms use Cloud Data Ingestion to collect customer activity data, product inventory, and transaction data. This data can then be used for real-time personalization, recommendations, and analytics. Social media platforms generate large volumes of unstructured data that needs to be ingested and processed for sentiment analysis, trend tracking, and user behavior analysis. In finance, data ingestion is used for real-time stock market data collection, fraud detection, and risk analysis.
Looking to master Cloud Computing? Sign up for ACTE’s Cloud Computing Master Program Training Course and begin your journey today!
Data Ingestion in Cloud Environments (AWS, Azure, GCP)
Cloud platforms such as AWS, Azure, and Google Cloud offer native services for data ingestion, each with its own set of tools and features:
Securing Data During Ingestion
Data security during ingestion is essential to prevent unauthorized access and ensure compliance with Data engineers . Best practices for securing data during ingestion include, Encrypt data both in transit and at rest to protect sensitive information from unauthorized access. Implement role-based access control (RBAC) to restrict who can access and ingest data. Continuously monitor the data ingestion process for unusual activity or security breaches.
Comparing Data Ingestion Frameworks (Kafka, Flume, NiFi)
When comparing data ingestion frameworks, the following factors should be considered: Apache Kafka: Kafka is widely used for real-time data streaming and is known for its scalability and reliability. It excels in handling high-throughput, low-latency Data engineers.
Boost your chances in Cloud Computing interviews by checking out our blog on Cloud Computing Interview Questions and Answers!
Future of Data Ingestion in Big Data and AI
The future of Cloud Data Ingestion will be influenced by the increasing volume, variety, and velocity of data. Technologies such as artificial intelligence (AI), machine learning (ML), and edge computing are driving the need for more sophisticated and real-time data ingestion systems. Greater Automation The ingestion process will become more automated, leveraging AI and ML to detect data anomalies and ensure the quality of ingested data. Edge Ingestion With the proliferation of IoT devices, edge computing will allow Data Engineering to be ingested and processed closer to the source, reducing latency. Real-time Analytics More focus will be placed on Cloud Computing Course , which will require advanced streaming ingestion capabilities. As organizations continue to embrace big data and AI, data ingestion will remain a cornerstone of their data architecture, enabling them to collect, process, and derive insights from vast amounts of data.




