
Last updated on 25th Feb 2025| 6484
- Introduction to AWS Neptune
- Understanding Graph Databases
- Characteristics of Graph Databases
- Advantages of Graph Databases
- AWS Neptune and Graph Models
- Use Cases for Graph Databases
- Neptune Architecture and Storage Model
- Querying Neptune with Gremlin and SPARQL
- Use Cases for AWS Neptune
- Performance Optimization and Best Practices
- Conclusion
Introduction to AWS Neptune
AWS Neptune is a fully managed graph database service provided by Amazon Web Services (AWS) that is designed to efficiently store and query graph data. It supports both property graph and RDF (Resource Description Framework) graph models, which are used to represent relationships between entities in various domains, including social networking, fraud detection, and knowledge graphs. With Neptune, you can build applications that require low-latency graph traversal and complex relationships between data points.
As a managed service, AWS Neptune handles tasks such as backups, patching, and scaling, allowing you to focus on your application development without worrying about the underlying infrastructure, a key topic covered in AWS Training to streamline cloud-based database management. It is highly scalable, reliable, and secure, making it an ideal choice for graph-based applications. Additionally, AWS Neptune integrates seamlessly with other AWS services, making it a powerful tool for building complex applications that leverage graph data.
Interested in Obtaining Your AWS Certificate? View The AWS Certification Training Offered By ACTE Right Now!
Understanding Graph Databases
Graph databases are specialized systems that excel in storing, processing, and analyzing highly interconnected data, a concept that can be integrated with a Guide to AWS SSO for managing user access and authentication in complex, data-driven environments. Unlike traditional relational databases, which use tables and rows to represent data, graph databases utilize a graph structure consisting of nodes (representing entities) and edges (representing the relationships between these entities).
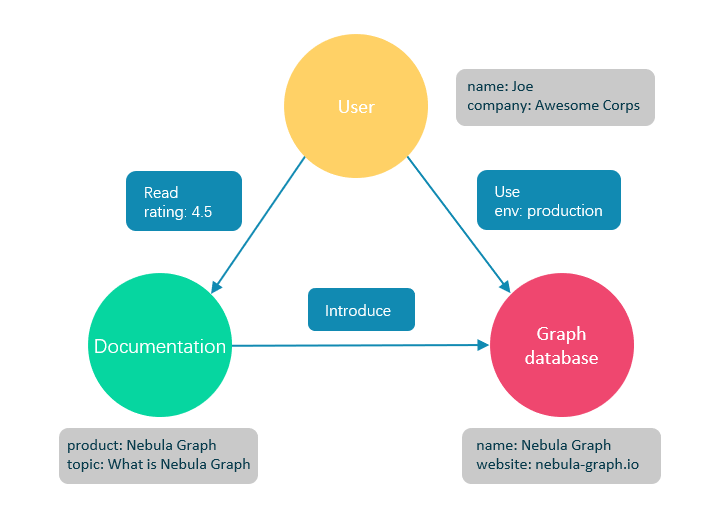
This structure makes graph databases uniquely suited for applications that need to navigate complex relationships and connections within the data. Unlike relational databases, graph databases do not require complex joins to traverse relationships, significantly improving query performance. They also provide a flexible schema, making it easier to adapt as the data model evolves over time. As the volume and complexity of connected data grow, graph databases offer a scalable solution for handling large datasets with intricate relationships.
Characteristics of Graph Databases
- Nodes: Nodes represent the entities or objects within the database. These could be people, places, things, or abstract concepts. For example, in a social network, a node might represent a user, while in a product catalog, a node could represent an item, similar to how AWS Transit Gateway – Simplifying Network Connectivity helps connect and manage different resources in a streamlined manner across cloud environments.
- Edges: Edges represent the relationships or connections between nodes. These edges are fundamental to graph databases, as they link different entities. For instance, in a social network, an edge could represent the relationship “friend of” between two users, or in an e-commerce platform, an edge might represent a “purchased” relationship between a customer and a product.
- Properties: Both nodes and edges can have properties or attributes that further describe the entities and relationships. For example, a node representing a person could have properties like name, age, and email, while an edge connecting two users could have a property like “friendship duration” to indicate how long they have been connected.
- Property Graphs: Neptune supports property graphs using the TinkerPop Gremlin API. In a property graph model, both nodes and edges can have properties, allowing for rich data representation and complex querying. The Gremlin query language facilitates traversal of the graph, making it a powerful tool for analyzing relationships between entities.
- RDF Graphs: Neptune also supports RDF graphs, which use the SPARQL query language. RDF is widely used for representing structured knowledge, especially in contexts where data is highly interconnected and needs to be queried semantically. RDF graphs are particularly suited for knowledge graphs, ontologies, and other systems that require linking data from different sources.
- Social Networks: Graph databases are perfect for modeling social networks, where users (nodes) are connected by relationships (edges) like “friends,” “followers,” or “likes.” Graph queries can uncover insights such as recommending new friends, identifying influencers, or analyzing communities.
- Recommendation Engines: In e-commerce or media streaming platforms, graph databases help make product or content recommendations by analyzing the relationships between users, items, and their interactions.
- Supply Chain Management: Graphs are effective in mapping out the relationships between suppliers, products, and logistics, which can help optimize supply chain management by identifying bottlenecks or improving routing.
- Knowledge Graphs and Semantic Data: Knowledge graphs are used to represent relationships between concepts in various domains, such as healthcare, finance, and education. Graph databases enable complex queries over interconnected data, facilitating AI-driven insights.
- Fraud Detection: In finance or banking, graph databases are used to detect fraudulent activities by analyzing transactions, accounts, and behaviors. By identifying patterns in user behavior and relationships, suspicious activities such as money laundering or credit card fraud can be flagged based on anomalous connections or behaviors.
- Telecommunications Networks: Graph databases can be used to model and optimize telecommunications networks, mapping out nodes like cell towers, users, and call connections. This can help in optimizing network traffic, detecting faults, or improving service quality by analyzing the connections between different network elements.
- Personalized Content Delivery: In online content platforms, graph databases can power personalized content delivery by analyzing the relationships between users, their viewing history, preferences, and interactions. It enables real-time recommendations and customized experiences based on interconnected data points.
- Enterprise IT Systems and Dependency Management: In large organizations, graph databases can model the relationships between IT infrastructure, applications, and services. This helps with understanding system dependencies, improving the detection of outages or vulnerabilities, and streamlining maintenance by identifying which systems are impacted by specific failures or updates.
- Gremlin is a query language used for property graphs, which is supported by the Apache TinkerPop graph computing framework. Gremlin queries are written as a series of steps that define how to traverse the graph.
- g.V().hasLabel(‘person’).has(‘name’, ‘Alice’).out(‘knows’).values(‘name’)
- SPARQL is used for querying RDF (Resource Description Framework) graphs. RDF is a standard model for representing data as triples, consisting of a subject, predicate, and object, a concept that can be integrated with AWS Control Tower for Secure Account Management to structure and query data securely across multiple AWS accounts. SPARQL queries are designed to retrieve and manipulate this data.
- SELECT ?name WHERE {
- ?person rdf:type ex:Person.
- ?person ex:name “Alice”.
- ?person ex:knows ?name.
- }
- This query retrieves the names of people that Alice knows, based on the RDF model.
- Indexing is essential for fast graph query execution. AWS Neptune automatically indexes properties for efficient querying. However, you can optimize performance by carefully planning your graph schema and choosing which properties to index.
- Complex graph queries can be resource-intensive. To optimize query performance, minimize the number of traversals and avoid unnecessary operations. Use filters early in the query to reduce the amount of data being processed.
- Proper graph data modeling is crucial for performance. Structure your graph in a way that makes queries efficient. For example, denormalizing some data or creating additional edges can speed up specific queries.
- AWS Neptune allows you to scale your database horizontally by adding read replicas to distribute read traffic. This is particularly useful for read-heavy applications where multiple users are querying the graph simultaneously.
- Use Amazon CloudWatch to monitor the performance of your Neptune instances. Track metrics such as CPU usage, memory usage, and disk I/O to identify potential performance bottlenecks.
- Regularly backup your Neptune database to prevent data loss. Neptune supports automated backups, but it’s also important to plan for disaster recovery scenarios, including cross-region backups for enhanced durability.
To Explore AWS in Depth, Check Out Our Comprehensive AWS Certification Training To Gain Insights From Our Experts!
Advantages of Graph Databases
The primary strength of graph databases lies in their ability to efficiently perform operations on highly interconnected data. They offer significant advantages over traditional relational databases in certain use cases, particularly when it comes to queries that require deep exploration of relationships. Finding the shortest path between two nodes, such as determining the most efficient route between two locations in a map, or identifying the closest relationship between two people in a social network, is a fundamental concept explored in AWS Training to optimize data processing and analysis in graph databases. Graph databases allow for the exploration of intricate relationships between entities. This is useful in applications like recommendation engines, where relationships between products, users, and preferences can be dynamically analyzed to provide personalized recommendations. In industries like banking or insurance, graph databases can help identify fraudulent activity by examining patterns of relationships. Suspicious patterns, such as multiple accounts linked by unusual connections, can be easily detected by traversing the graph. Graph databases are ideal for representing knowledge graphs, where nodes represent concepts or entities, and edges represent relationships or context. This structure is useful for applications that rely on semantic data and the relationships between concepts, such as in search engines or AI systems.
AWS Neptune and Graph Models
AWS Neptune is a fully managed graph database service provided by Amazon Web Services. It supports both property graphs and RDF (Resource Description Framework) graphs, giving you the flexibility to choose the model that best fits your use case:
By supporting both models, AWS Neptune allows you to leverage the most appropriate graph model depending on the nature of your data and the complexity of your queries.

Use Cases for Graph Databases
Neptune Architecture and Storage Model
The architecture of AWS Neptune is designed to offer high performance, scalability, and availability for graph-based workloads. The underlying infrastructure is based on the AWS cloud and is optimized for graph database operations. Here’s a breakdown of Neptune’s key components and storage model:
Cluster Architecture:AWS Neptune operates in a cluster-based architecture, where each Neptune cluster consists of a primary instance and one or more replica instances. The primary instance handles both read and write operations, while replica instances can handle read requests to distribute the load and improve performance, in line with the AWS Shared Responsibility Model, where AWS manages the infrastructure, and customers manage their application and data security. Neptune automatically replicates data across multiple Availability Zones to ensure high availability and durability. If a primary instance fails, a replica can be promoted to ensure minimal downtime.
Storage Model:Neptune uses a distributed storage architecture where data is stored in a log-structured format, which is optimized for fast reads and writes. This enables Neptune to scale horizontally as your data grows. Data is divided into multiple shards, and each shard is replicated for fault tolerance. This ensures that Neptune can handle large datasets while maintaining high performance for graph queries.
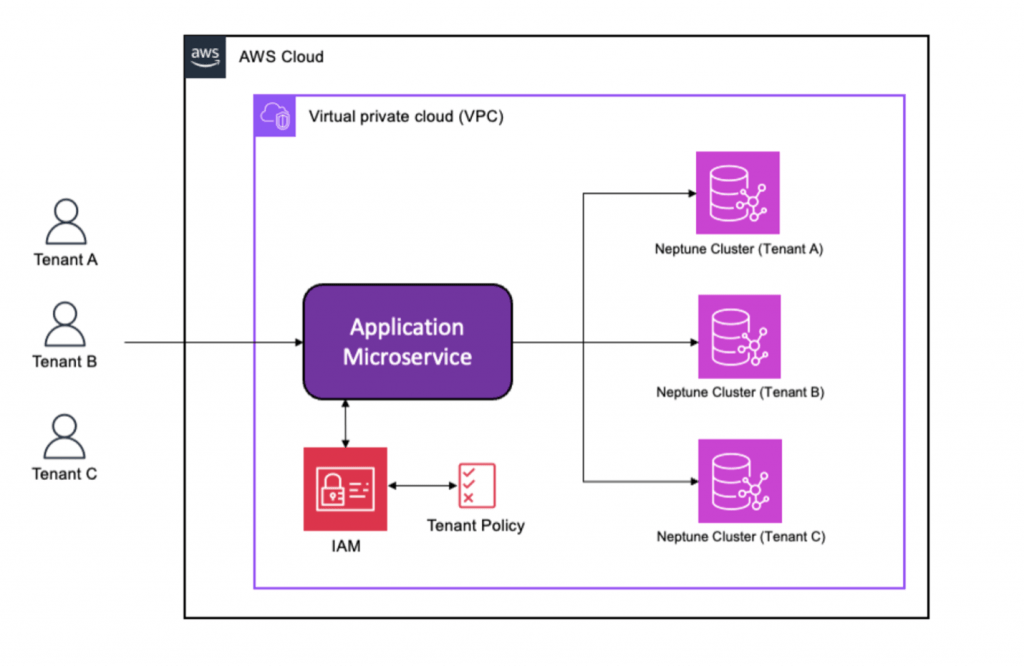
To further optimize query performance, AWS Neptune incorporates an in-memory caching layer. Frequently accessed data is cached, reducing the need to read from disk and improving response times for commonly queried data. The caching layer also helps reduce the load on the underlying storage system, making queries faster and more efficient.
Secure Data Storage:AWS Neptune offers encryption at rest using AWS KMS (Key Management Service) and encryption in transit using SSL/TLS protocols. This ensures that your graph data is stored securely and protected during data transmission.
Are You Considering Pursuing a Master’s Degree in Cloud Computing? Enroll in the Cloud Computing Masters Course Today!
Querying Neptune with Gremlin and SPARQL
AWS Neptune supports two popular graph query languages, Gremlin and SPARQL, each designed for different graph models:
- Gremlin:
This query finds a person named “Alice” and returns the names of the people she knows.
- SPARQL:
Neptune supports both query languages, so you can choose the one that best fits your application’s data model. The service is optimized for fast graph traversals, allowing for complex queries over large datasets with low latency.
Use Cases for AWS Neptune
AWS Neptune is ideal for managing complex relationships and connections in various use cases. In social networks, it models relationships between users, posts, and interactions. For recommendation engines, Neptune helps suggest products or content based on user behavior. It aids in fraud detection by analyzing patterns between users and transactions. Neptune also supports knowledge graphs for efficient information management in search engines or enterprise systems. Additionally, it’s used in IT operations to monitor network topologies and in supply chain management to optimize processes and identify inefficiencies. Its ability to handle large-scale graph data makes it a powerful tool for machine learning and artificial intelligence applications. Neptune also ensures scalability and reliability for real-time query processing, which can be further enhanced when integrated with AWS ECR Secure Container Storage for managing containerized applications and their data securely. The flexibility to integrate with other AWS services further enhances its utility. It’s a cost-effective solution for businesses needing to process and analyze interconnected data.
Performance Optimization and Best Practices
To maximize the performance of AWS Neptune, several best practices should be followed:
- Indexing:
- Optimizing Queries:
- Data Modeling:
- Scaling:
- Monitoring and Metrics:
- Backup and Recovery:
Preparing for a AWS Job Interview? Check Out Our Blog on AWS Interview Questions and Answers
Conclusion
AWS Neptune is a powerful, fully managed graph database service that enables organizations to efficiently store and query highly interconnected data. With support for both property graph and RDF graph models, Neptune offers flexibility for diverse use cases, including social networks, recommendation engines, fraud detection, knowledge graphs, and more. By leveraging Neptune’s distributed architecture, in-memory caching, and seamless integration with other AWS services, businesses can build scalable, high-performance applications that require complex graph traversals and relationship analysis. Graph databases, such as Neptune, provide significant advantages over traditional relational databases when dealing with interconnected data, a concept that is thoroughly explored in AWS Training to enhance the understanding of modern data management techniques in cloud environments. They eliminate the need for complex joins, enabling faster query performance and flexible schema evolution. With Neptune’s managed infrastructure, users can focus on application development while AWS handles tasks such as backups, scaling, and security. To maximize performance, adopting best practices like indexing, query optimization, and proper data modeling is essential. By scaling horizontally and utilizing monitoring tools like Amazon CloudWatch, organizations can ensure the continued efficiency of their graph database as data grows. Additionally, leveraging Neptune’s security features, such as encryption at rest and in transit, helps protect sensitive information. Overall, AWS Neptune is an ideal solution for organizations that need to manage complex graph data, providing high scalability, low-latency query performance, and the reliability that AWS is known for. Its ability to integrate with other AWS services and support for real-time, AI-driven insights make it a valuable tool for many industries and use cases.




