
Last updated on 20th Mar 2025| 5707
- Introduction to Azure Data Lake
- Key Features of Azure Data Lake
- How Azure Data Lake Works
- Data Storage and Processing in Azure Data Lake
- Azure Data Lake vs Azure Blob Storage
- Security and Compliance in Azure Data Lake
- Integrating Azure Data Lake with Azure Analytics Services
- Pricing and Cost Optimization
- Conclusion
Introduction to Azure Data Lake
Azure Data Lake is a highly scalable and secure data storage and analytics service provided by Microsoft Azure. It is designed to store massive amounts of structured, semi-structured, and unstructured data, making it ideal for big data analytics and machine learning workloads. Azure Data Lake is built on top of Azure Blob Storage, with enhancements to support large-scale analytics and data processing, making it a critical component in modern data architecture. With Azure Data Lake, organizations can store petabytes of data without worrying about data structure limitations. This allows them to analyze vast amounts of information and scale as needed. Its integration with other Azure services like Azure Synapse Analytics, Azure Databricks, and Azure HDInsight makes it an essential tool for enterprises that require comprehensive big data processing and analytics.
Key Features of Azure Data Lake
Azure Data Lake comes with several key features that make it a powerful tool for big data storage and analytics:
- Scalability: It supports massive volumes of data, scaling to handle petabytes of structured, semi-structured, and unstructured data. The scale is virtually limitless, with the ability to grow as data needs increase.
- High Throughput and Low Latency: Azure Data Lake is designed to deliver high throughput, allowing data to be ingested and processed quickly. This is critical for real-time and batch-processing scenarios.
- Hierarchical Namespace: It provides a hierarchical namespace for organizing data into directories and subdirectories, making it easier to manage large datasets.
- Optimized for Analytics: Data stored in Azure Data Lake can be used seamlessly with Azure’s analytics services, such as Azure Databricks, Azure Synapse Analytics, and HDInsight, providing a comprehensive solution for big data processing.
- Integration with Big Data Frameworks: Azure Data Lake integrates with popular big data frameworks like Apache Hadoop, Apache Spark, and Apache Hive, allowing for efficient data processing using familiar tools.
- Security: It provides built-in security features, including Azure Active Directory (Azure AD) authentication and role-based access control (RBAC) to restrict access at both the file and directory levels.
- Cost-Effective Storage: Azure Data Lake offers cost-effective storage for large datasets, providing different pricing tiers based on storage volume and usage.
- Data Lifecycle Management: Azure Data Lake includes tools for data lifecycle management, allowing users to automatically move data to different storage tiers based on usage patterns.
- Storage: Data can be stored in raw form, including text, logs, images, videos, sensor data, and more. Azure Data Lake’s hierarchical file system makes it easier to organize and manage large volumes of data. It also supports various file formats such as Parquet, JSON, CSV, and Avro, making it versatile for different use cases.
- Processing: The data stored in Azure Data Lake can be processed using various Azure services and frameworks:
- Azure Databricks: A unified analytics platform for big data and machine learning that integrates seamlessly with Azure Data Lake.
- Azure HDInsight: A fully managed cloud service that allows the Hadoop ecosystem to process large datasets.
- Azure Synapse Analytics: An analytics service that combines big data and data warehousing capabilities to query data stored in Data Lake.
- Apache Spark: A fast, in-memory data processing engine that can be used with Azure Data Lake for data transformation and analysis.
The ability to process data at scale, combined with storage capabilities, makes Azure Data Lake an ideal platform for modern data engineering and analytics workloads.

Azure Data Lake vs Azure Blob Storage
Feature Azure Blob Storage Azure Data Lake Storage Purpose General-purpose storage for unstructured data Optimized for big data analytics and processing Data Storage Stores large binary objects (images, videos, backups) Stores massive datasets for analytics workloads Hierarchical Namespace Not supported (flat namespace) Supported (directories & subdirectories) Performance Designed for simple storage & retrieval Optimized for high-speed analytics & processing security & Access Control Azure AD, RBAC, but less granular control Azure AD, RBAC with fine-grained access control Integration Works well for general storage use cases Integrates with Azure Synapse, Databricks, HDInsight Use Case Backup, archiving, and media storage Big data analytics, transformation, and processing Security and Compliance in Azure Data Lake
Security is critical to Azure Data Lake, as it handles large volumes of potentially sensitive data. Some key security features include:
- Azure Active Directory (AAD): Authentication and authorization are managed using Azure AD, which allows administrators to control access to data based on user identity.
- Role-Based Access Control (RBAC): With RBAC, you can define specific roles for users and groups to control what data they can access in the data lake. This ensures that only authorized personnel can read, write, or modify the stored data.
- Data Encryption: Azure Data Lake uses encryption at rest and in transit, ensuring your data is protected against unauthorized access.
- Azure Policy: Azure Data Lake integrates with Azure Policy to enforce data governance policies and ensure compliance with industry regulations.
- Monitoring and Auditing: Azure Monitor and Azure Security Center can track access and activity in your Data Lake, allowing you to detect anomalies and maintain compliance.
- Data Classification: Azure Data Lake allows you to classify data and apply appropriate security controls based on sensitivity, which helps in meeting compliance requirements such as GDPR or HIPAA.
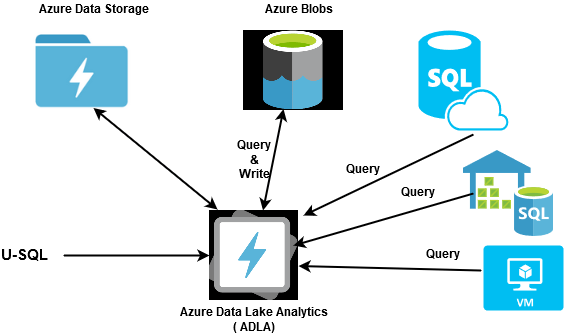
Integrating Azure Data Lake with Azure Analytics Services
Azure Data Lake seamlessly integrates with a variety of Azure analytics services, allowing you to build end-to-end data analytics and machine learning workflows. Azure Data bricks is an Apache Spark-based analytics platform that allows you to perform data processing, transformation, and machine learning on data stored in Data Lake. Formerly known as Azure SQL Data Warehouse, this service integrates with Azure Data Lake for big data and data warehousing capabilities, enabling batch and real-time analytics on large datasets. A fully-managed cloud service that provides a Hadoop-based framework for big data processing. You can use HDInsight to analyze data stored in Data Lake using popular big data tools like Spark, Hive, and Hadoop. Power BI can visualize data stored in Azure Data Lake, providing insights and interactive dashboards for business users. You can train machine learning models on data stored in Data Lake, creating a complete data science workflow within the Azure ecosystem.
Azure Data Lake Online course Sample Resumes! Download & Edit, Get Noticed by Top Employers! DownloadPricing and Cost Optimization
Azure Data Lake offers flexible pricing options depending on the amount of data you store and the frequency of access. Some key cost factors include:
- Storage Costs: You are charged based on the amount of data stored in Azure Data Lake. Pricing is typically based on the volume of data stored, with tiered pricing for different storage classes.
- Data Access: Accessing the data involves costs, depending on the frequency of data retrieval and operations performed.
- Data Processing: While Azure Data Lake itself is focused on storage, the costs for processing and analyzing the data using services like Azure Databricks, HDInsight, and Synapse Analytics may add to your overall costs.
Cost Optimization Tips:
- Use Cool or Archive Tiers: To reduce storage costs for infrequently accessed data, consider using the Cool or Archive storage tiers.
- Data Lifecycle Management: Set up policies to automatically move data to lower-cost storage tiers as it ages.
- Optimize Processing: Optimize data processing performance to reduce costs related to computing resources.
Conclusion
Azure Data Lake is a powerful and scalable solution for storing and analyzing large volumes of structured, semi-structured, and unstructured data. Its deep integration with Azure analytics services, strong security features, and hierarchical namespace make it an ideal choice for big data processing and machine learning workloads. Organizations leveraging Azure Data Lake can benefit from improved data management, cost-effective storage, and high-performance analytics capabilities. However, challenges such as governance, cost optimization, and security management must be carefully addressed. By implementing best practices for data storage, processing, and security, businesses can maximize the value of Azure Data Lake and drive meaningful insights from their data.
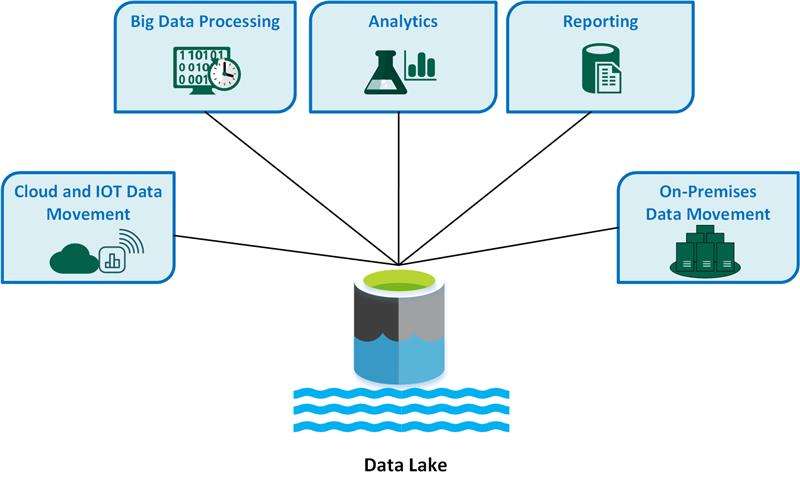
How Azure Data Lake Works
Azure Data Lake uses Azure Blob Storage as the foundational layer while providing additional capabilities to meet the demands of big data analytics. Here’s how it operates. Data is stored in a flat namespace within a hierarchical file system that supports directories and subdirectories. This allows organizations to store massive datasets and organize them efficiently. Depending on the requirements, data can be ingested into Azure Data Lake in real-time or batch processes. Tools such as Azure Data Factory, Azure Databricks, and Azure Stream Analytics can be used to bring data from various sources into the data lake. Data can be accessed by various analytics engines and services. Users can use Azure Synapse Analytics, Azure Databricks, and HDInsight to process and analyze the data stored in Azure Data Lake. The data lake supports different types of data processing, from real-time stream processing to batch analytics. Big data frameworks like Hadoop and Spark can perform complex transformations and analyses on the data stored in the lake. Azure Data Lake uses Azure AD authentication for secure data access and supports RBAC to ensure that only authorized users can access specific datasets. After data is ingested and processed, the analytics results can be used to gain business insights. These insights can be visualized in tools like Power BI or further processed for machine learning models.
Data Storage and Processing in Azure Data Lake
Azure Data Lake provides robust storage and processing capabilities for data of all types, including structured, semi-structured, and unstructured data:




