
Last updated on 12th Mar 2025| 6473
- What is a Data Lake?
- Key Characteristics of a Data Lake
- Common Use Cases
- Why build Data Lake on Amazon S3?
- AWS Data Lake Architecture
- AWS Data Lake best practices
- What is AWS Lake Formation?
- Conclusion
What is a Data Lake?
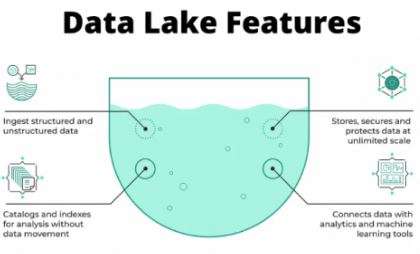
A Data Lake is a centralized repository that allows you to save full-size quantities of dependent, semi-dependent, and unstructured statistics at any scale. Unlike conventional databases or statistics warehouses, which save statistics in predefined schemas, a statistics lake keeps uncooked statistics in its local layout until they are needed. A statistics lake is a centralized place where both prepared and unstructured statistics are saved. It is a website where we can also save and control all forms of files, impartial in their source, scale, or layout, to do analysis, visualization, and processing in accordance with the organization’s goals. For example, Data Lake is applied for Big data analytics initiatives in numerous industries, from public fitness to R&D, and in many enterprise domain names, including marketplace segmentation, marketing, Sales, and HR, in which Business Analytics answers are critical. When using a statistics lake, all statistics are retained; none is deleted or filtered earlier than the garage. The statistics will be analyzed immediately, later, or in no way at all. It can also be reused several instances for a couple of purposes, instead of whilst statistics have been polished for a sure purpose, making it hard to reuse statistics in a brand new way. Organizations leveraging Amazon web service training can optimize their Data Lake implementations by utilizing AWS tools such as Amazon S3, AWS Glue, and AWS Lake Formation. These services help manage, organize, and analyze data efficiently, ensuring scalability and security while maintaining cost-effectiveness.
Key Characteristics of a Data Lake
- Stores All Types of Data—Supports dependent (databases), semi-dependent (JSON, XML, CSV), and unstructured (videos, images, PDFs, logs) data.
- Schema-on-Read – Data is saved in an uncooked layout and most effectively dependent whilst examined or processed.
- Scalability – Can deal with massive volumes of statistics efficiently.
- Cost-Effective—It often uses low-fee cloud storage services like AWS S3, Azure Data Lake Storage, or Google Cloud Storage.
- Supports Advanced Analytics – Enables AI, system learning, and massive statistics analytics.
- Data Flexibility – Accommodates a wide variety of data formats, making it easy to integrate data from multiple sources such as logs, IoT sensors, social media, and more.
- Real-Time Data Processing – Supports the ability to process and analyze data in real-time, enabling quick decision-making and insights.
- High Availability & Durability – Uses distributed storage and redundancy techniques, ensuring that the data is always available and protected from loss or downtime.
- Data Security – Provides robust data encryption, access control, and compliance features to ensure that sensitive data is protected and adheres to privacy regulations.
- Easily Integrated with Data Lakes and Warehouses – Seamlessly integrates with existing data lakes and data warehouses, offering a unified platform for storing and analyzing data.
Looking Forward to Getting Your AWS Certificate? View The AWS Course Presented by ACTE Right Now!
Common Use Cases
- Big Data Analytics: Big data analytics refers to the process of examining large and varied data sets to uncover hidden patterns, correlations, trends, and insights. With the volume, variety, and velocity of data growing exponentially, organizations leverage big data analytics to make more informed decisions, optimize operations, and predict future trends. The data analyzed can come from various sources such as customer interactions, sensors, social media, and transaction logs. Tools like Hadoop, Spark, and specialized databases help process and analyze big data effectively.
- Machine Learning & AI: Career in AI & Machine learning involve the use of algorithms and models to identify patterns and make predictions based on data. In the context of big data, these technologies allow systems to learn from vast amounts of information, automate decision-making, and improve over time with minimal human intervention. Machine learning models can be trained on historical data to recognize trends and patterns, while AI can extend this by using these insights to perform tasks like natural language processing, image recognition, and recommendation systems.
- IoT Data Storage: The Internet of Things (IoT) generates massive amounts of data from connected devices like sensors, wearables, machines, and smart appliances. IoT data storage solutions are designed to efficiently collect, store, and manage this data. The storage must be scalable, support real-time processing, and ensure that the data is accessible for analysis. Technologies like cloud storage and edge computing are commonly used to store IoT data, enabling devices to send information to centralized systems or process data locally at the edge of the network for faster decisions.
- Data Archiving: Data archiving refers to the process of storing infrequently accessed or older data that no longer requires active use but still needs to be retained for compliance, legal, or business purposes. Archiving ensures that this data is preserved securely and can be accessed when needed without taking up valuable space in active storage systems. This is often achieved through cost-effective and scalable storage solutions, such as cloud-based archives, where data is compressed, encrypted, and stored in a manner that allows for efficient retrieval when required.
- Real-time Streaming Data Processing: Real-time streaming data processing involves the continuous collection and analysis of data as it is generated, allowing businesses to act on the insights almost immediately. Examples of this include monitoring social media feeds, financial market transactions, or sensor data from industrial equipment. Tools like Apache Kafka, Apache Flink, and Amazon Kinesis process data streams in real-time, helping organizations make faster decisions, optimize operations, and detect issues or opportunities as they happen. This capability is crucial for applications requiring low-latency processing, such as fraud detection, predictive maintenance, and live customer support.

Develop Your Skills with AWS Certification Online Training
Weekday / Weekend BatchesSee Batch DetailsWhy build Data Lake on Amazon S3?
AWS S3 is constructed for facts sturdiness of 99.999999999%. With that degree of sturdiness, you need to anticipate the best to lose one item every 10,000 years in case you store 10,000,000 gadgets in Amazon S3. All uploaded S3 objects are routinely copied and saved throughout many structures via means of the carrier. This guarantees that your facts will constantly be had and secure from failures, faults, and threats. In addition to this remarkable durability, Amazon S3 also provides robust data availability, ensuring that objects are accessible whenever needed. The service automatically handles replication of data across multiple geographically dispersed data centers, offering resilience against regional failures. S3’s design also includes features like versioning and lifecycle management to help with data retention and recovery. Furthermore, AWS provides detailed monitoring and logging tools to keep track of data access and usage. With these safeguards in place, S3 ensures that your critical data remains secure and reliable for years to come.
Other capabilities include:- Security via way means of design
- Scalability on demand
- Durable
- Integration with third birthday celebration carrier companies
- Vast facts control capabilities
- Stores datasets of their unique form, irrespective of size, on Amazon S3
- Ad hoc changes and analyses are completed using AWS Glue and Amazon Athena. With AWS Training , organizations can learn to efficiently manage, process, and analyze data in a Data Lake, ensuring optimized performance and cost-effectiveness.
- In Amazon DynamoDB, user-described tags are saved to contextualize datasets, allowing governance regulations to be carried out and datasets to be accessed primarily based totally on their metadata.
- A data lake with pre-incorporated SAML companies like Okta or Active Directory is created using federated templates.
- Landing zone— In the AWS touchdown zone, raw data is ingested from many sources, both outside and inside the company. Data modeling and transformation are absent.
- Curation zone— At this step, you carry out extract-transform-load (ETL), move facts slowly to discover their shape and value, upload metadata, and use modeling techniques.
- Production zone— includes processed data prepared for utilization via enterprise apps, analysts, data scientists directly, or each.
- For deployment of infrastructure components, AWS CloudFormation is used.
- API Gateway and Lambda features are used to grow facts packages, ingest facts, grow manifest, and perform administrative duties.
- The center microservices store, manage and audit facts using Amazon S3, Glue, Athena, DynamoDB, Elasticsearch Service, and CloudWatch.
- With Amazon CloudFront appearing because of the get right of entry to the point, the CloudFormation template builds a facts lake console in an Amazon S3 bucket. It then creates an administrator account and sends you an invite via email.
- Collecting records
- Moving records to the Records-Lake
- Organizing records
- Cleansing records
- Making certain records is secure
- Your statistics are registered for S3 routes and buckets.
- Create statistics catalogs with metadata about your statistics sources.
- Makes statistics flows to absorb and manage uncooked statistics as necessary.
- Data entry to controls is installed through a rights/revocation approach for each metadata and actual statistics.
Excited to Achieve Your AWS Certification? View The AWS Online Course Offered Today by ACTE!
AWS Data Lake Architecture
A facts lake is a structured pattern, no longer a particular platform. It is built around a vast facts shop that employs a schema-on-study approach. In Amazon Facts Lake, you store substantial quantities of unstructured facts in item storage, along with Amazon S3, without pre-structuring the facts, but with the choice to do destiny ETL and ELT at the facts. As a result, it’s miles ideal for businesses that require the evaluation of continuously converting facts or very massive datasets. Even though there are numerous astonishing facts about lake architectures.
Amazon gives a popular structure with the subsequent components:
The structure consists of three essential components:
Steps for deploying reference structure
Exploring Options for AWS Master’s Degree?Enroll For AWS Specialist Course Today!
AWS Data Lake best practices
Amazon advises preserving records in their original layout after ingestion. Any record transformation should be stored in a separate S3 bucket to allow for reprocessing and fresh analysis of the original data. While this is a smart practice, S3 may accumulate outdated information. To manage this, use object lifecycle policies to transfer older records to archive storage tiers like Amazon Glacier, enabling cost savings while maintaining access as needed. Proper organization is crucial from the start of an AWS Data Lake Benefits & Features project. Data should be partitioned across multiple S3 buckets, with unique keys generated for each partition to facilitate common queries. If no predefined structure exists, organizing partitions in a day/month/year format is recommended. Different data types require tailored processing approaches—use Redshift or Apache HBase for dynamic transformations, while immutable records can be stored in S3 for analysis. For real-time data processing, use Kinesis for data streaming, Apache Flink for processing, and S3 for storing the output to ensure quick ingestion and analysis.
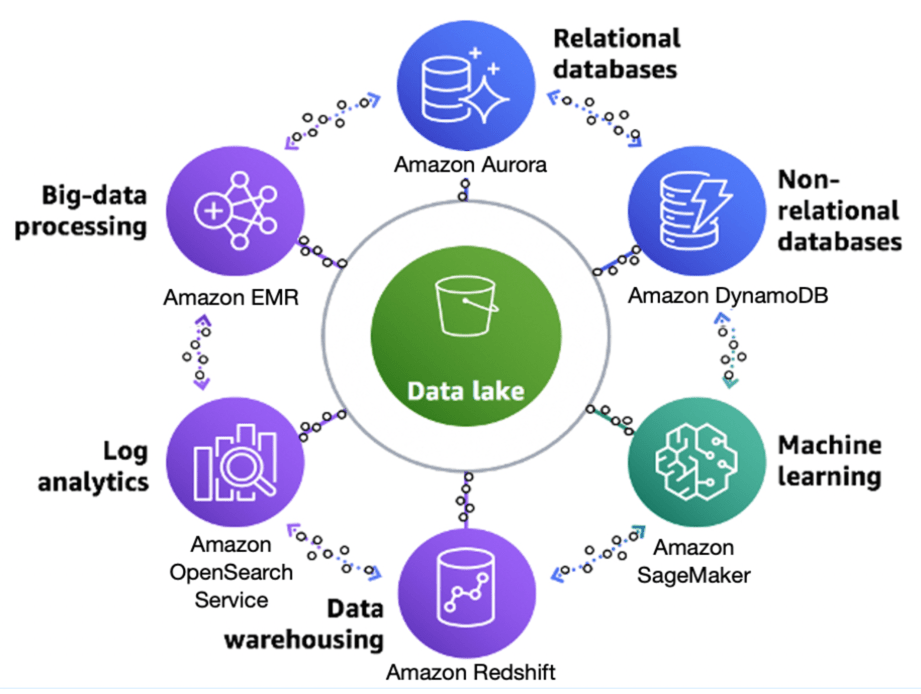
What is AWS Lake Formation?
To let you personalize your deployment and permit non-stop records control, Amazon gives AWS Lake Formation. The development, security, and control of your records lake are less demanding with Lake Formation, a controlled service. It simplifies the challenging guide sports, which might be frequently vital to creating a records lake, including:
To construct a records lake, Lake Formation scans, reasserts, and mechanically places records into Amazon Simple Storage Service (Amazon S3).
Set to Ace Your AWS Job Interview? Check Out Our Blog on AWS Interview Questions & Answer
How is Lake Formation Related to Other AWS Services?
Lake Formation handles the subsequent functions, both immediately or circuitously, through different AWS offerings along with AWS Glue, S3, and AWS database offerings:
After saving the data within the statistics lake, customers can access and engage with it using their favorite analytics tools, such as Amazon Athena, Redshift, or EMR.
Conclusion
A Data Lake is a centralized repository that stores structured, semi-structured, and unstructured data at any scale. Unlike traditional databases, it retains raw data in its native format until needed. AWS offers scalable and cost-effective solutions for managing Data Lakes, such as Amazon S3, AWS Glue, and AWS Lake Formation. With AWS training , organizations can optimize Data Lakes for analytics, AI, and real-time processing. With Amazon Web Sevice Certification, professionals can validate their expertise in designing, implementing, and managing Data Lakes using AWS best practices. However, without proper governance and security, a Data Lake can become a “Data Swamp,” making insights harder to retrieve.




