
Last updated on 20th Mar 2025| 5717
- Introduction to AWS Glue
- How AWS Glue Works
- Components of AWS Glue
- AWS Glue vs. AWS Athena vs. Amazon Redshif
- Use Cases of AWS Glue
- AWS Glue Pricing and Cost Considerations
- ETL Processes in AWS Glue
- Security Best Practices in AWS Glue
- Integrating AWS Glue with Other AWS Services
- Conclusion
Introduction to AWS Glue
AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that simplifies preparing, transforming, and loading data for analytics. It is designed to help data engineers, analysts, and scientists move and transform data from various sources, such as relational databases, NoSQL databases, and data lakes, into a format suitable for analysis and machine learning. AWS Glue automates much of the heavy lifting in data processing, including discovery, transformation, and loading (ETL). It integrates with a wide range of AWS services, providing a cohesive ecosystem for handling big data workflows and analytics in the cloud. With built-in support for schema discovery, data cataloging, and job scheduling, AWS Glue enables organizations to streamline data pipelines, reduce manual intervention, and enhance operational efficiency. Additionally, AWS Glue offers flexible execution options, supporting both batch and streaming data processing, which is often emphasized in Amazon Web Services Training . It provides built-in connectors for various AWS and third-party data sources, allowing seamless data movement across environments. Developers can use AWS Glue Studio for a visual, no-code ETL experience or write custom ETL scripts in Python or Scala for more complex transformations. Its serverless nature ensures automatic scaling, reducing infrastructure management overhead while optimizing cost and performance.
How AWS Glue Works
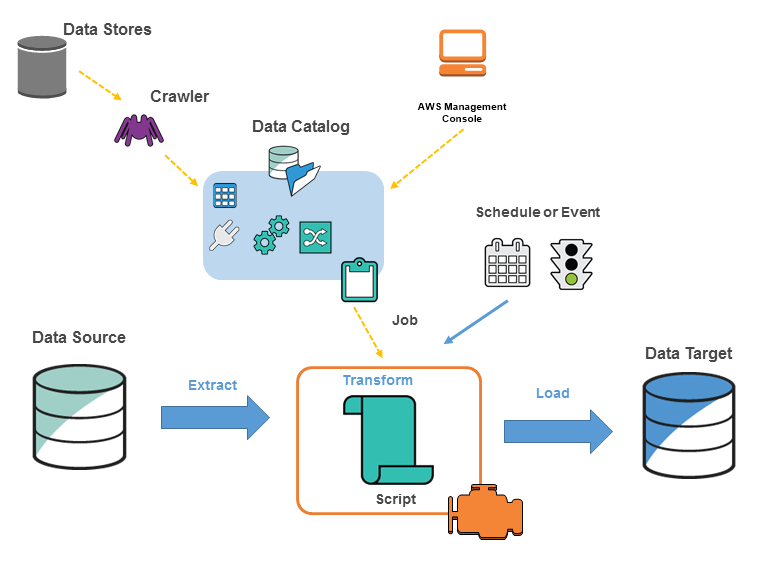
AWS Glue is designed to handle data extraction, transformation, and loading (ETL) tasks with minimal configuration. Here’s an overview of how it works:
- Data Crawlers: AWS Glue automatically discovers data in your data sources and organizes it using crawlers. Crawlers scan your data, identify the structure, and catalog metadata in the Glue Data Catalog. This allows for the automation of ETL jobs by creating tables that reference the underlying data.
- ETL Jobs: After discovering the data, AWS Glue can automatically generate ETL jobs that transform and load it. These jobs can be written in Python or Scala and triggered on demand or on a schedule.
- Data Catalog: The AWS Glue Data Catalog is a central repository that stores metadata information about your data. It makes it easier to manage, discover, and query your data from AWS services like Amazon Athena, Amazon Redshift, and AWS Lake Formation.
- Serverless Execution: AWS Glue is serverless, meaning it abstracts the infrastructure management away. You do not need to manage servers, and Glue scales automatically based on the size and complexity of the ETL jobs.
- Integration with AWS Services: AWS Glue seamlessly integrates with other AWS services like Amazon S3, Amazon RDS, Amazon Redshift, and Amazon Athena, allowing you to process data from various sources and formats.
Excited to Obtaining Your AWS Certificate? View The AWS Course Offered By ACTE Right Now!
Components of AWS Glue
AWS Glue consists of several key components that work together to make data integration, and ETL processes more straightforward to manage. Crawlers discover data sources, extract metadata, and populate the Glue Data Catalog. Crawlers automatically infer the schema and types of the data, ensuring that the metadata is up to date. Crawlers can be configured to run on a schedule or be triggered manually. The Data Catalog is a central repository that stores metadata information about your data. It tracks the schema, location, and format of the data and makes it easy to access from different services. It is integrated with other AWS services like Amazon Athena, Amazon Redshift Spectrum, and Amazon EMR. ETL (Extract, Transform, Load) jobs are the core of the AWS Glue service. These jobs extract data from the source, perform transformations, and load the processed data into a destination (e.g., Amazon S3, Amazon Redshift, or RDS). AWS Glue provides a visual interface (Glue Studio) for building these jobs without writing code or enables custom code to be written in Python or Scala for more advanced transformations. Triggers are used to start ETL jobs based on specific events or schedules. You can set up triggers to run your ETL jobs at certain times or in response to particular events, such as data arriving in an S3 bucket or changes in a database. Development endpoints allow developers to interact with AWS Glue through an interactive environment (e.g., Jupyter notebooks). This is useful for testing and debugging ETL jobs before deploying them in production. Job bookmarks help track the state of data processed in a previous ETL run, allowing AWS Glue to process only new or changed data in subsequent runs. This prevents redundant processing and ensures that ETL jobs are efficient.
AWS Glue vs. AWS Athena vs. Amazon Redshift
AWS Glue
Primary Use: Data integration and ETL.
Key Features: Serverless, manages data pipelines, discovers data via crawlers, supports batch and real-time ETL jobs.
It is Best For Moving, transforming, and loading data into data lakes or analytics platforms like Redshift, S3, or Athena.
Amazon Redshift
Primary Use: A data warehouse for running complex queries on large datasets.
Key Features: Scalable, columnar storage, integrates with various AWS Web Services.
It is Best For Storing and analyzing structured data at scale with complex queries and fast performance.
Key Difference
- Glue is for managing ETL workflows.
- Athena is for querying data in S3 using SQL, ideal for ad-hoc analysis.
- Redshift is for structured, high-performance analytics supporting SQL queries on large datasets.

Use Cases of AWS Glue
AWS Glue is commonly used for a variety of data processing and integration tasks, AWS Glue can transform data from various sources (databases, files, and applications) into a data warehouse like Amazon Redshift for reporting and analytics. Glue can process data and load it into Amazon S3 to create a data lake. It can ingest semi-structured data from sources like JSON, CSV, or XML and convert it into a standardized format. AWS Glue can process streaming data, allowing real-time ETL jobs to handle data as it flows in. This is useful for real-time analytics, fraud detection, or log monitoring scenarios. You can use Glue to migrate data from on-premises databases or legacy systems to AWS services such as S3, Redshift, or RDS. AWS Glue is ideal for transforming and cleaning data, such as removing duplicates, normalizing values, or reshaping data to match the destination format.
Excited to Obtaining Your AWS Certificate? View The AWS Training Offered By ACTE Right Now!
AWS Glue Pricing and Cost Considerations
AWS Glue pricing is based on the following components:
- Crawlers: Charged based on the number of data crawlers and their running duration. Crawlers are billed in minutes.
- ETL Jobs: You are billed based on the number of data processing units (DPU) used by the ETL jobs and the time they run. A DPU is a combination of CPU and memory resources used for processing.
- Data Catalog: There is a charge for storing and managing the metadata in the Glue Data Catalog. This cost is based on the number of tables stored and the number of partitions.
- Development Endpoints: Charges are based on the time the development endpoints are running and the resources consumed during development.
- Data Transfer: There may be additional data transfer charges if you transfer data between regions or out of AWS, as explained in AWS Training.
Optimizing resource use to avoid unnecessary costs is essential. Minimizing crawler runs, using bookmarks in ETL jobs, and deleting unused development endpoints can help reduce costs.
Are You Considering Pursuing an AWS Master’s Degree? Enroll For AWS Master Course Today!
ETL Processes in AWS Glue
AWS Glue simplifies ETL workflows by providing an automated environment to move, transform, and load data. The process typically follows these steps:
- Extract: AWS Glue extracts data from different sources, such as Amazon RDS, Amazon S3, or other databases. The data can be structured, semi-structured, or unstructured.
- Transform: Glue provides built-in functions and a Python/Scala-based environment to transform the data. This includes filtering, aggregation, joining tables, and formatting.
- Load:The transformed data is loaded into a destination like Amazon AWS S3 Bucket, Amazon Redshift, or a relational database for analysis.
AWS Glue also supports batch and streaming ETL, enabling various workflows depending on the data’s real-time or batch needs.
Security Best Practices in AWS Glue
Security is essential in any data integration service. AWS Glue follows AWS security standards and provides several features to secure your data. Define fine-grained access control using AWS Identity and Access Management (IAM) roles and policies to restrict access to Glue resources. AWS Glue supports encryption at rest using (Aws Key Management ) and in transit (using SSL/TLS). Glue can run ETL jobs within a Virtual Private Cloud (VPC) to securely access data in private subnets and connect to other AWS services like RDS. AWS CloudTrail logs can be enabled to track activity and access to Glue resources, providing visibility into user actions. AWS Lake Formation allows you to define column-level and row-level security for your Glue Data Catalog tables, ensuring that users only access the data they are authorized to see. Use AWS Private Link to establish a secure, private connection between AWS Glue and other AWS services without exposing traffic to the public internet. Store sensitive information like database credentials in AWS Secrets Manager or AWS Systems Manager Parameter Store, and reference them securely in Glue jobs instead of hardcoding credentials.
Set to Ace Your AWS Job Interview? Check Out Our Blog on AWS Interview Questions & Answer
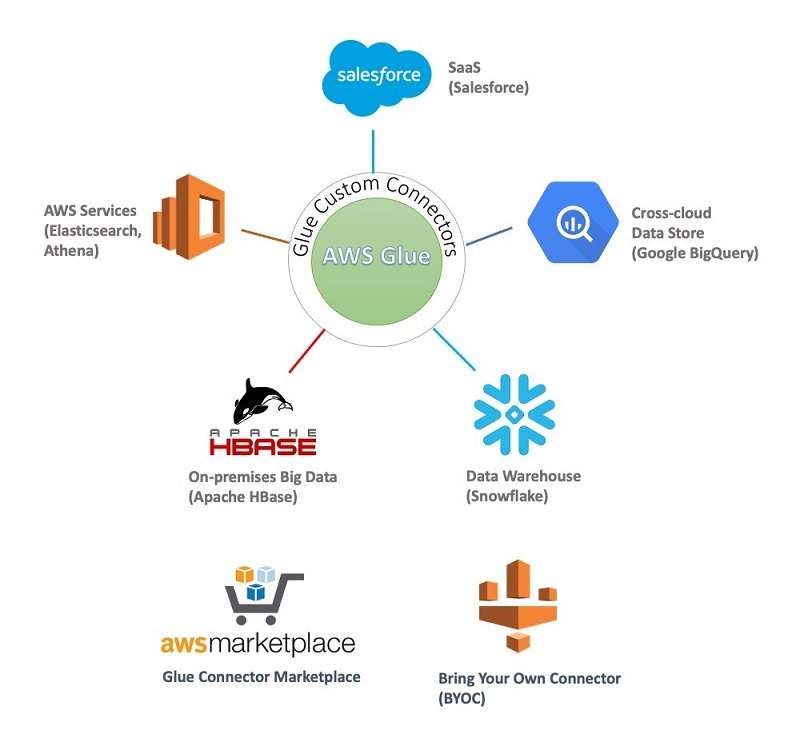
Integrating AWS Glue with Other AWS Services
- Amazon S3: Glue can read and write data to S3, making it the ideal choice for working with data lakes.
- Amazon Redshift: You can use Glue to move data from S3 or databases into Redshift for analytics.
- Amazon RDS and DynamoDB: Glue can extract and transform data from Amazon RDS and DynamoDB for analytics or storage in a data lake.
- Amazon Athena: Glue can populate the Data Catalog after ETL jobs, making it easy to query data with Athena using SQL.
- Amazon CloudWatch: For monitoring and logging ETL jobs, AWS Glue integrates with CloudWatch to provide insights into job success/failure, performance, and logs.
Conclusion
In conclusion, AWS Glue is a powerful, serverless ETL tool that simplifies data integration workflows in the cloud. By eliminating infrastructure management, it enables organizations to focus on extracting insights rather than provisioning resources. Its ease of use—featuring the Glue Data Catalog, Glue Studio, and broad data source support—makes it a versatile choice. Deep integration with AWS services like Lambda, Step Functions, and Athena further streamlines complex workflows. With automation, optimization techniques, AWS Training, and security best practices—including IAM-based access control and encryption AWS Glue ensures efficient, secure, and cost-effective data processing. As data volumes grow, its scalability and flexibility make it an essential tool for modern data engineering.




