
Last updated on 20th Mar 2025| 6015
- Introduction to Amazon EMR
- How Amazon EMR Works
- Use Cases of Amazon EMR
- Key Components of Amazon EMR (Hadoop, Spark, Presto, etc.)
- AWS EMR vs Traditional Hadoop Clusters
- Pricing and Cost Optimization for AWS EMR
- Security and Compliance in AWS EMR
- Scaling and Performance Optimization
- Best Practices for Running Big Data Workloads on AWS EMR
- Conclusion
Introduction to Amazon EMR
Amazon EMR (Elastic MapReduce) is an AWS-managed big data processing service. It simplifies running distributed data processing frameworks, such as Apache Hadoop, Apache Spark, Apache HBase, Apache Flink, Presto, and other popular open-source frameworks. Amazon EMR Performance allows businesses to process vast amounts of data efficiently without managing complex infrastructure. EMR provides a highly scalable, cost-effective environment for running big data workloads, with deep integration into AWS’s suite of tools. This enables users to seamlessly connect their processing cluster with other services like Amazon S3, Amazon DynamoDB, and Amazon Redshift, making it a go-to choice for companies that need to process, analyze, and extract value from their big data sets.
How Amazon EMR Works
Amazon EMR works by providing a scalable environment where users can run applications and frameworks for big data processing. Here’s how it operates:
- Cluster Setup: You can set up an EMR cluster with just a few clicks or through the AWS CLI. The cluster consists of a controller node and multiple core and task nodes. The controller node coordinates the job execution, and the core nodes store data (via HDFS) and run the tasks.
- Data Storage: Data is stored in Amazon S3 or other AWS storage solutions. When EMR runs a job, the data is pulled from S3, processed, and the results are stored back into S3 or other databases.
- Frameworks & Tools: EMR supports a range of AWS Solutions Architect big data processing frameworks, including Hadoop, Spark, Presto, and Hive. You can choose the framework that best suits your workload and use case.
- Job Execution: Once the cluster is configured and the data is available, you can submit jobs (e.g., Spark jobs, MapReduce jobs) to the cluster. The cluster then performs the necessary computation and data processing.
- Cluster Management: EMR automatically scales your cluster according to the workload. You can add or remove instances based on demand, ensuring that you pay only for the resources you need.
- Data Transfer: EMR integrates seamlessly with other AWS services, including Amazon RDS, Amazon Redshift, and Amazon DynamoDB. You can transfer data between these services and your EMR cluster as part of your data processing pipeline.
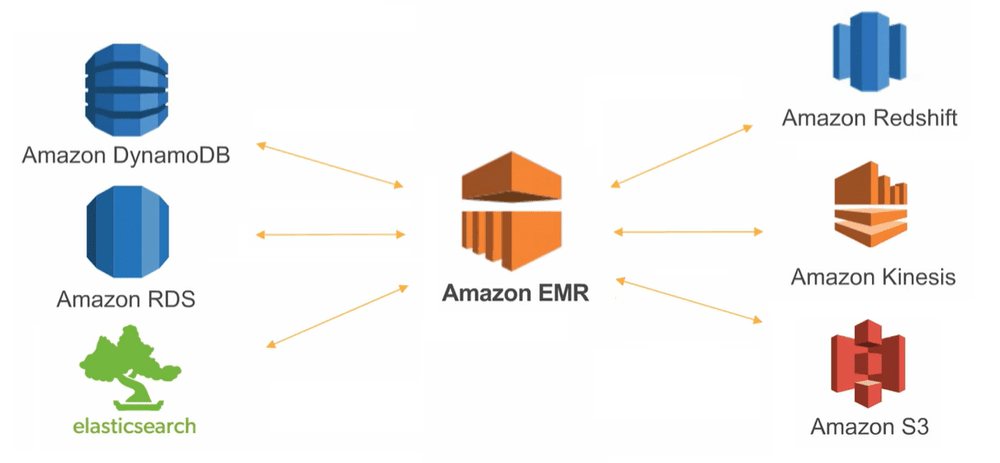
Use Cases of Amazon EMR
Amazon EMR is versatile and can be used for various big data applications. Some of the everyday use cases includes, EMR is often used to build data lakes on AWS by processing raw data in S3, transforming it, and storing it in structured formats in databases like Amazon Redshift or Amazon RDS. Many organizations use EMR to analyze large volumes of log files. Businesses can extract meaningful insights from large-scale log data by processing logs with Apache Spark or Hive. With frameworks like Apache Spark Streaming, AWS Course can process streaming data from various sources in real-time, providing insights and analytics in near real-time. EMR can be integrated with Apache Spark MLlib and other machine learning libraries to perform distributed machine learning at scale, making it suitable for tasks like model training and predictive analytics. EMR with Apache Hive creates a data warehouse-like structure on S3. This allows you to run SQL queries on large datasets and perform analytics. EMR can be used to build and train recommendation algorithms, typically using large datasets to make personalized recommendations in e-commerce or content platforms.
Are You Interested in Learning More About AWS ? Sign Up For Our AWS Online Training Today!
Key Components of Amazon EMR (Hadoop, Spark, Presto, etc.)
- Hadoop: Hadoop is a framework for storing and processing large datasets in a distributed environment. In EMR, it is commonly used to run MapReduce jobs and store data in the HDFS (Hadoop Distributed File System).
- Spark: Apache Spark is an open-source, distributed computing framework faster and more flexible than Hadoop’s MapReduce. It can be used for batch processing, interactive querying, machine learning, and real-time data processing.
- Presto: Presto is a distributed SQL query engine that runs fast analytic queries over large data sets. It’s often used for querying data stored in data lakes (like S3) in a distributed manner.
- Hive: Apache Hive is a data warehouse system built on top of Cloud Architect Pay Hadoop. It allows you to query large datasets using SQL-like queries. It is often used in EMR for data warehousing and querying structured data.
- HBase: Apache HBase is a NoSQL database built on top of Hadoop. It is designed for high scalability and low-latency access to large datasets, making it useful for real-time analytics on large, distributed datasets.
- Flume: Flume is a tool for efficiently collecting, aggregating, and moving large amounts of log data from many sources to a centralized data store.
- Oozie: Oozie is a workflow scheduler that allows users to define complex data processing workflows with Hadoop jobs (MapReduce, Pig, Hive, etc.).
- Zookeeper: Apache Zookeeper is a distributed coordination service used to manage configurations and synchronize tasks in distributed systems. It is often used with Hadoop and Spark.

AWS EMR vs Traditional Hadoop Clusters
| Feature | AWS EMR | Traditional Hadoop Clusters |
|---|---|---|
| Management | Fully managed, automated cluster management. | Requires manual setup and maintenance. |
| Scalability | Automatically scalable based on demand. | Requires manual scaling by adding/removing nodes. |
| Cost | Pay-as-you-go model; only pay for what you use. | Requires upfront investment in hardware and resources. |
| Infrastructure | Serverless model, abstracts infrastructure management. | Requires managing hardware, software, and infrastructure. |
| Integration | Seamless integration with AWS services (S3, DynamoDB, Redshift). | Requires manual integration with other systems. |
| Ease of Use | Simplified setup and management via AWS Console. | More complex setup and configuration. |
In summary, AWS EMR simplifies the process of managing and running big data clusters, whereas traditional Hadoop clusters require more manual effort, from setup to scaling.
To Earn Your End to End Encryption Certification, Gain Insights From Leading End to End Encryption Experts And Advance Your Career With ACTE’s AWS Online Training Today!
Pricing and Cost Optimization for AWS EMR
Amazon EMR pricing is based on the EC2 instances you use for your cluster, the Amazon S3 storage consumed, and the data transfer costs. The pricing model is:
- On-Demand Pricing: You pay for the resources (EC2 instances, S3 storage) as you use them. There’s no upfront cost or long-term commitment.
- Spot Instances: EC2 Spot Instances can reduce the cost of running clusters by up to 90%. They are ideal for non-critical, fault-tolerant workloads.
- Reserved Instances: For long-term projects, AWS Amplify you can purchase EC2 Reserved Instances for a one- or three-year term, which offers savings over on-demand pricing.
- Cost Optimization Tips: Use S3 for storage and compress data to reduce the cost of data transfer and storage. Scale clusters based on demand shrink clusters when not in use. Leverage Spot Instances for temporary compute needs. Auto Scaling automatically scales the number of EC2 instances in the cluster.
- Leverage Data Partitioning: Partition your data in S3 for faster querying and processing.
- Automate Cluster Management: Use CloudFormation or AWS Course SDKs to automate cluster provisioning and decommissioning.
- Optimize Resource Utilization: Regularly monitor and scale your clusters based on workload needs.
- Utilize Spot Instances for Cost Savings: Use Spot Instances for non-critical workloads to reduce overall costs.
Looking to Master AWS? Discover the AWS Cloud Architect Master training Program Available at ACTE!
Security and Compliance in AWS EMR
Amazon EMR has built-in security features that integrate with AWS security services. Use IAM roles and policies to control resource access. Fine-grained access control allows you to specify which actions users can perform. Data in S3 can be encrypted using AWS KMS (Key Management Service) or Server-Side Encryption (SSE). Data within the EMR cluster can be encrypted in transit and at rest. AWS Security EMR can be launched within an Amazon VPC, providing additional network security by controlling inbound and outbound traffic. Amazon EMR integrates with AWS CloudTrail and Amazon CloudWatch for audit logging and monitoring. This allows you to track cluster usage and job execution. EMR supports compliance with standards such as HIPAA, SOC, PCI DSS, and GDPR.
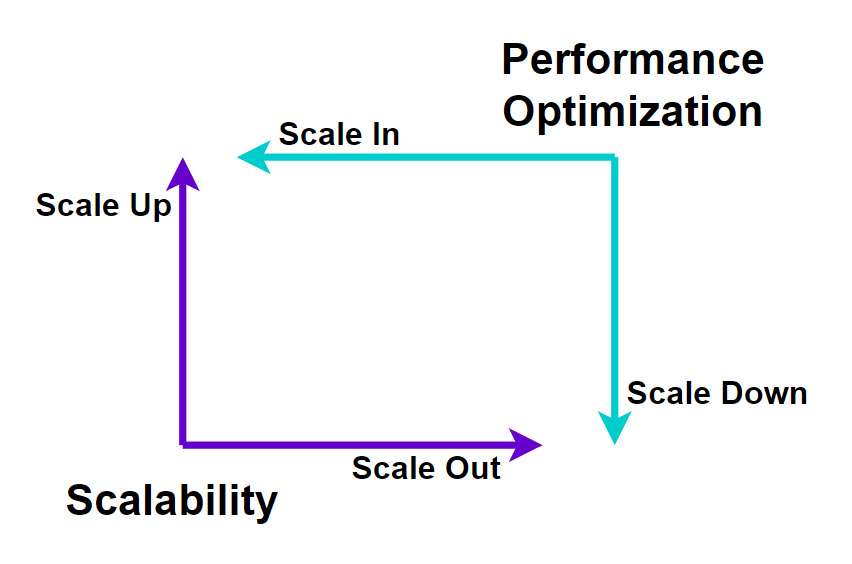
Scaling and Performance Optimization
Auto Scaling, Configure auto-scaling to add/remove instances based on CPU usage or other metrics. This ensures that the cluster is optimally sized at any given time. Spot Instances, Use AWS Training EC2 Spot Instances for tasks that can tolerate interruptions, reducing the cluster’s cost. Partitioning and Bucketing, In Hive and Spark, partitioning and bucketing data optimizes performance by reducing the amount of data read during queries. Cluster Sizing, Choose the right EC2 instance types and sizes based on your workload’s resource requirements (memory, CPU, storage).
Best Practices for Running Big Data Workloads on AWS EMR
Want to Learn About Cloud Computing? Explore Our AWS Interview Questions and Answers Featuring the Most Frequently Asked Questions in Job Interviews.
Conclusion
In conclusion, Amazon EMR (Elastic MapReduce) provides a robust, scalable, and cost-effective platform for processing large datasets, making it an excellent choice for big data analytics. By leveraging its powerful suite of tools, including Hadoop, Spark, and Hive, businesses can efficiently analyze vast amounts of data without worrying about managing complex infrastructure. Understanding how Amazon EMR works, its key components (such as clusters, nodes, and storage options), and applying best practices like optimizing cluster performance, using spot instances, and properly configuring security can significantly enhance the efficiency and cost-effectiveness of big data projects. With Amazon EMR, businesses can unlock the full potential of their data, gaining valuable insights and driving better decision-making while minimizing the overhead associated with managing on-premises infrastructure.




