
Last updated on 07th Mar 2025| 6622
- Introduction to AWS Data Pipeline
- Key Features and Benefits
- Setting Up an AWS Data Pipeline
- Integrating AWS Data Pipeline with S3, RDS, and Redshift
- Scheduling and Automating Workflows
- Security and Access Management
- Monitoring and Debugging Pipelines
- Real-World Use Cases
- Conclusion
Introduction to AWS Data Pipeline
AWS Data Pipeline is a cloud-based data management service offered by Amazon Web Services (AWS). It allows users to move and process data across AWS services and on-premises storage in a highly reliable, scalable, and cost-effective manner. AWS Data Pipeline automates data movement and transformation, enabling complex workflows to run on a scheduled basis with minimal human intervention. Designed to handle the complexities of data integration and ETL (Extract, Transform, Load) processes, AWS Training Data Pipeline allows organizations to automate data workflows, reduce the need for manual intervention, and improve operational efficiency. Whether you’re moving data from Amazon S3 to Amazon Redshift for analysis or integrating with on-premises data sources, AWS Data Pipeline provides a reliable solution for managing complex data workflows in the cloud.
Key Features and Benefits
- Data Movement and Transformation: AWS Data Pipeline is designed to help users quickly move data between different AWS services, including Amazon S3, Amazon RDS, Amazon Redshift, Amazon DynamoDB, and others. An Introduction to AWS Amplify can also integrate with on-premises databases or external data sources to facilitate end-to-end data workflows. In addition to moving data, AWS Data Pipeline allows users to perform data transformations. This includes data format conversion, filtering, aggregation, and more. The transformation process is customizable, making it suitable for different use cases, from data cleansing to enriching data before loading it into target databases.
- Workflow Automation: With AWS Data Pipeline, users can automate data workflows on a scheduled basis. This helps businesses automate data movement from one service to another, such as moving data from S3 to Redshift or running periodic backups. Automation significantly reduces the manual effort required to run complex data processing workflows, freeing up resources for more critical tasks.
- Reliability and Fault Tolerance: AWS Data Pipeline is designed with reliability and fault tolerance in mind. The service automatically retries failed tasks, ensuring that workflows are executed reliably. Furthermore, if an error occurs during the pipeline’s execution, AWS Data Pipeline can automatically trigger alerts to notify users about the issue. The service supports error handling, retries, and monitoring, which helps ensure that pipelines continue to function correctly even under failure conditions.
- Scalability: AWS Data Pipeline is built on AWS’s scalable infrastructure, which allows it to handle both small and large-scale data workflows. Whether you’re processing a few gigabytes of data or petabytes, AWS Data Pipeline can scale as needed, automatically adjusting resources to handle growing workloads without manual intervention.
- Customizable and Flexible: The service offers great flexibility for users. It allows the definition of complex data workflows with Secure AWS Glue ETL Jobs with Best Practices tasks and customized logic. You can specify when and how tasks are executed and define retries and success conditions. AWS Data Pipeline gives users fine-grained control over how data is processed, moved, and transformed across different services.
- Cost-Effective: AWS Data Pipeline operates on a pay-as-you-go pricing model, where users are billed based on the resources they consume. The cost is determined by the number of pipeline activities executed, the data processed, and the frequency of task execution. This model ensures that organizations only pay for what they use, making it a cost-effective solution for automating data workflows without significant upfront costs.
- Log into the AWS Management Console First, log into the AWS Management Console and navigate to the Data Pipeline service. You’ll be greeted with a simple interface for creating and managing data pipelines.
- Define the Pipeline When setting up a pipeline, you need to define its basic parameters, such as the pipeline name, description, and unique identifier. AWS Web Application Firewall WAF also need to choose the region in which the pipeline will run.
- Select a Template AWS Data Pipeline provides several predefined templates for common use cases, such as transferring data between S3 and Redshift or running daily data ETL jobs. These templates help simplify the pipeline creation process. Alternatively, you can create a custom pipeline by manually defining tasks, resources, and data flow.
- Add Data Nodes and Activities Once the basic pipeline structure is defined, you can specify the data nodes (sources and destinations) involved in the pipeline. For example, you can configure Amazon S3 as a source and Amazon Redshift as a destination. You’ll also define activities like copying, transforming, or loading data. You can define various parameters for each activity, such as the data source location, the transformation logic, and the frequency of execution. You can also set up dependencies between tasks to control the execution order.
- Schedule the Pipeline Next, you need to schedule when and how often the pipeline runs. AWS Data Pipeline allows you to specify a start time, recurring intervals, and an end time for the pipeline. You can also choose between different scheduling options, such as running the pipeline once, daily, or at specific intervals.
- Configure Data Pipeline Resources Data Pipeline tasks often require specific resources, such as EC2 instances, Amazon RDS, or AWS Lambda functions. These resources are defined in the pipeline and automatically provisioned when it is executed. For example, if your pipeline involves data transformation, an EC2 instance may be required to run the transformation script.
- Set Permissions To ensure secure access, you must configure permissions for the AWS resources in your pipeline. This can be done through IAM roles that define what resources the pipeline can access, such as S3 buckets or RDS instances. Proper IAM configuration ensures that only authorized entities can interact with your data.
- Activate the Pipeline After defining the pipeline, you can review the configuration and activate the pipeline. Once activated, the pipeline will run according to the defined schedule and execute the tasks specified in the configuration.
- IAM Roles and Policies IAM roles are essential for defining permissions for the Protect your AWS Environment with Amazon Guardduty. Each task can be associated with a specific IAM role, which dictates the resources the pipeline can access, such as S3 buckets or EC2 instances.
- Encryption AWS Data Pipeline supports encryption at rest and in transit to ensure your data remains secure during processing and transfer. Data in Amazon S3, Redshift, and other services can be encrypted using AWS KMS (Key Management Service) or server-side encryption.
- Data Integrity AWS Data Pipeline provides several mechanisms to ensure data integrity. You can configure automatic retries for failed tasks and ensure that tasks are not skipped. Additionally, the service allows you to validate and transform data before loading it into the destination.
- ETL Workflows Many organizations use AWS Data Pipeline to automate ETL workflows. For instance, you can move raw log data from S3 into RDS or Redshift, transform it, and store the results in a data warehouse for analytics.
- Data Migration AWS Data Pipeline is also used for data migration between different AWS services. For example, you can migrate data from an on-premises database to Getting Started with AWS CDK or transfer large volumes of data between S3 buckets in other regions.
- Real -Time Data Processing In scenarios that require real-time data processing, AWS Data Pipeline can work with services like Amazon Kinesis and AWS Lambda to process incoming data streams and trigger transformations or notifications.
AWS Data Pipeline offers several key features that help streamline data workflows, enhance data management, and provide a highly scalable and secure platform for data processing. Below are some of the primary features and benefits of using AWS Data Pipeline:
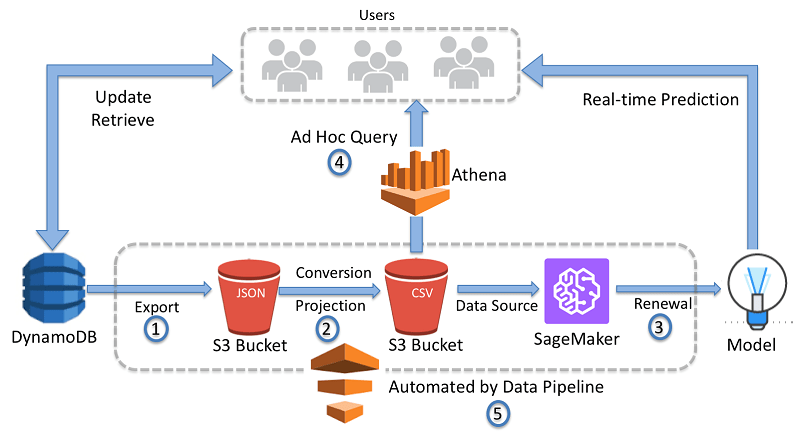
Master AWS skills by enrolling in this AWS Certification Training today.
Setting Up an AWS Data Pipeline
Setting up an AWS Data Pipeline is straightforward, but it requires careful planning to ensure that it is both efficient and reliable. Here’s a general overview of the steps involved in creating and configuring an AWS Data Pipeline.

Integrating AWS Data Pipeline with S3, RDS, and Redshift
AWS Data Pipeline integrates seamlessly with various AWS services like Amazon S3, Amazon RDS, and Amazon Redshift, enhancing its capabilities for data workflows. Amazon S3 serves as a key data source and destination, allowing for the automation of data movement between S3 and other services, making it ideal for ETL workflows. For example, you can schedule a pipeline to copy log files from an S3 bucket to an RDS database for processing or export processed data from RDS to S3 for backup or further analysis. Amazon RDS, a relational database service, integrates smoothly with AWS Data Pipeline to handle data processing tasks. AWS Batch Automate Optimize Job Processing can be used to load data from S3 into RDS for storage, perform ETL operations, and export results to S3 or Redshift. Amazon Redshift, AWS’s fully managed data warehousing service, is another powerful destination for large datasets. AWS Data Pipeline automates data loading into Redshift, facilitating easier analysis and reporting, such as moving data from S3 into Redshift or scheduling daily data loads from RDS or on-premises data sources.
Enhance your knowledge in AWS. Join this AWS Certification Training now.
Scheduling and Automating Workflows
One of the main advantages of AWS Data Pipeline is its ability to schedule and automate complex workflows. This feature is particularly useful for ETL processes, data integration, and periodic backups. AWS Data Pipeline allows you to configure tasks to run at fixed intervals, such as daily at midnight or every hour, or based on event-based triggers, like when a file is uploaded to an S3 bucket. This flexibility in scheduling helps optimize resource usage and reduces the need for constant monitoring. The automation ensures that tasks are executed on time and consistently, without the need for manual intervention. AWS Training helps eliminate errors, improve efficiency, and reduce operational overhead. Additionally, it ensures that data workflows are streamlined, reducing delays and making processes more reliable across the organization. As a result, teams can focus more on value-added activities while relying on Data Pipeline to handle repetitive tasks efficiently.
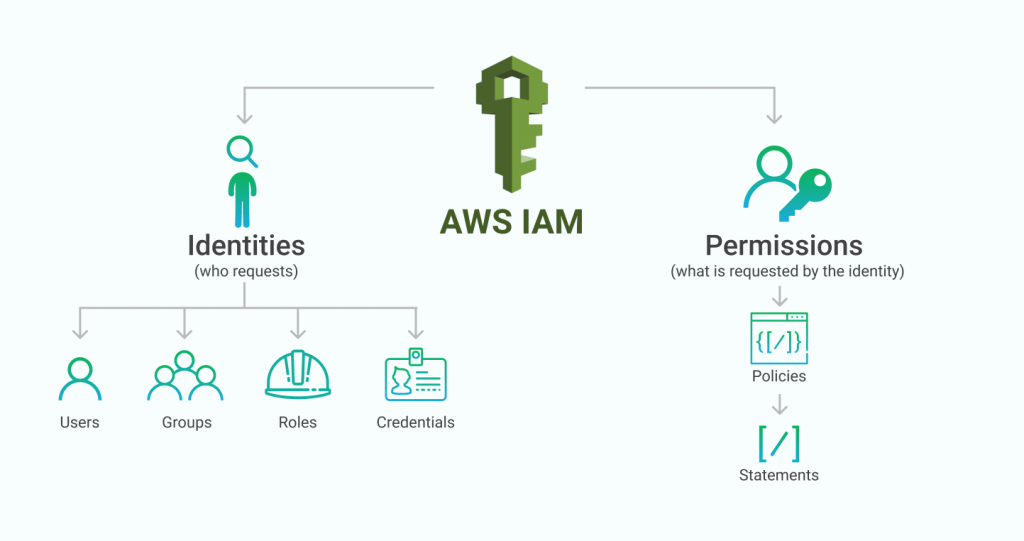
Security and Access Management
AWS Data Pipeline offers robust security features crucial for managing sensitive data. Access to pipeline resources is controlled using AWS Identity and Access Management (IAM) roles and policies. Here are the primary security features:
Want to lead in AWS? Enroll in ACTE’s AWS Master Program Training Course and start your journey today!
Monitoring and Debugging Pipelines
Monitoring and debugging are essential to ensure that AWS Data Pipelines run smoothly. AWS offers several tools to help users monitor pipeline performance and debug issues. AWS Data Pipeline integrates with Amazon CloudWatch, enabling users to track pipeline activity and view logs for debugging. CloudWatch provides metrics related to pipeline execution, task status, and resource utilization, allowing users to monitor the health of their data pipelines. Additionally, AWS Data Pipeline can be configured to send error notifications, enabling quick resolution of issues. By using Simple Notification Service (SNS), users can receive alerts when a task fails or when specific events occur. Furthermore, AWS Data Pipeline includes an automatic retry mechanism, which ensures that tasks are retried if they fail, preventing incomplete functions due to temporary issues and enhancing the overall reliability of data workflows.
Preparing for a job interview? Explore our blog on AWS Interview Questions and Answers!
Real-World Use Cases
Here are some real-world use cases where AWS Data Pipeline adds value:
Conclusion
AWS Data Pipeline is an essential service for automating and managing data workflows across AWS. With features like integration with S3, RDS, and Redshift, automated scheduling, flexible workflow management, and strong security, it simplifies the process of moving and transforming data at scale. By using AWS Training , organizations can reduce manual efforts, improve data accuracy, and ensure reliable, scalable data processing for a wide range of use cases. Additionally, it enhances operational efficiency by automating complex data tasks. Its seamless integration with other AWS services makes it an ideal choice for diverse data pipeline requirements. Ultimately, AWS Data Pipeline provides businesses with a robust solution for handling large-scale data operations.




