Last updated on 11th Apr 2025| 6450
- Introduction to AWS Redshift
- Key Features of AWS Redshift
- How AWS Redshift Works
- Benefits of AWS Redshift
- Use Cases of AWS Redshift
- AWS Redshift vs. Other Data Warehouses
- Pricing of AWS Redshift
- Setting Up AWS Redshift
- Best practices of using AWS Redshift
- Conclusion
Excited to Achieve Your AWS Certification? View The AWS Online course Offered By ACTE Right Now!
Introduction to AWS Redshift
Amazon Redshift is a fully managed cloud data warehouse service provided by AWS (Amazon Web Services). It enables businesses and developers to run complex queries and perform real-time analytics on large datasets. Redshift is designed to handle petabyte-scale data warehousing, offering high performance, scalability, and ease of use. Unlike traditional relational databases, Redshift stores data in a columnar format optimized for read-heavy analytic workloads. As part of Amazon Web Services Training, it leverages massively parallel processing (MPP), distributing the processing load across multiple nodes to accelerate queries. Redshift integrates seamlessly with various AWS services, such as Amazon S3, Amazon DynamoDB, and AWS Glue, which makes it easier to build end-to-end data workflows. AWS Redshift is often used in scenarios where businesses need to efficiently analyze and report on large volumes of data, such as running SQL queries on data from operational databases, processing large datasets for business intelligence, or conducting log analysis.
Key Features of AWS Redshift
AWS Redshift provides a range of features designed to make managing large-scale data workloads easier and more efficient:
- Columnar Storage: Redshift stores data in a columnar format, which improves query performance for analytics workloads. This allows quicker data retrieval by reading only the relevant columns instead of entire rows, reducing the amount of data scanned.
- Massively Parallel Processing (MPP): Amazon Redshift distributes queries across multiple nodes in a cluster, enabling it to process queries in parallel and handle large datasets quickly.
- Scalability: Redshift allows users to scale their data warehouse from a single-node setup to a petabyte-scale environment. You can scale vertically (by increasing node resources) or horizontally (by adding more nodes).
- High Availability and Fault Tolerance: Redshift provides automatic backups, snapshots, and replication across multiple availability zones to ensure high availability and fault tolerance.
- Data Security: Redshift encrypts data both in transit and at rest. Additionally, it supports VPC (Virtual Private Cloud) for network isolation and integrates with AWS Identity and Access Management (IAM) for access control.
- Integration with AWS Services: Redshift integrates with other AWS services, such as AWS Glue for ETL processes, Amazon S3 for data storage, and Amazon Kinesis for real-time data streaming, making it a powerful part of a broader AWS ecosystem.
- High Performance: Redshift’s MPP architecture and columnar storage help execute complex queries quickly, even on massive datasets, making it ideal for data analytics and business intelligence workloads.
- Cost-Effective: Redshift is a cost-effective solution because it offers on-demand pricing based on the resources you use. It can scale up or down based on demand, so you only pay for what you use, making it a flexible and budget-friendly option.
- Fully Managed: AWS Redshift is a fully managed service that handles all administrative tasks like patching, backups, and scaling, freeing up time for users to focus on analytics instead of infrastructure management. Similarly, AWS Workspaces offers a fully managed, secure Desktop-as-a-Service (DaaS) solution, allowing users to provision cloud-based desktops and eliminate the complexity of traditional desktop management.
- Scalable: Whether you’re running a small data warehouse or need to scale to a petabyte of data, Redshift can accommodate your growth by allowing you to add more nodes as required.
- Security and Compliance: Redshift offers built-in security features like encryption and fine-grained access control. It also complies with various industry standards, making it suitable for organizations in regulated industries.
- Seamless Integration: Redshift integrates well with other AWS services, such as Amazon S3 for storage, AWS Lambda for serverless computing, and AWS Glue for ETL tasks, making it easier to set up a complete data pipeline.
- Data Warehousing: Redshift is primarily used to store large volumes of structured data that can be queried for reporting, analysis, and business intelligence purposes.
- Business Intelligence and Analytics: Organizations widely use Redshift to run queries and generate insights from data to drive decision-making. It works well with BI tools like Tableau, Power BI, and Looker.
- Big Data Analytics: Redshift is designed to handle massive datasets. It is commonly used for big data processing, where large amounts must be analyzed to uncover patterns or trends.
- Machine Learning: Data scientists use Redshift as a data source for machine learning models. It allows quick access to large datasets, which is essential for training machine learning algorithms.
- Log and Event Analysis:With AWS Training, users can leverage Redshift to handle large amounts of log data from web applications, servers, or network devices, enabling organizations to analyze trends and detect anomalies.
- On-Demand Pricing: With on-demand pricing, you pay for the compute capacity by the hour, based on the node type and number of nodes. This flexible model allows you to pay only for what you use.
- Reserved Instances:For long-term workloads, you can reserve 1- or 3-year instances to save up to 75% over on-demand pricing. This is ideal for customers with predictable usage patterns and who prioritize AWS Security best practices.
- Redshift Spectrum: You pay for the amount of data scanned by Redshift Spectrum, which allows you to query data stored in Amazon S3 without moving it into the data warehouse.
- Storage Costs: Redshift charges for data storage vary based on the storage type (standard or managed) and the total storage capacity.
Excited to Obtaining Your AWS Certificate? View The AWS Training Offered By ACTE Right Now!
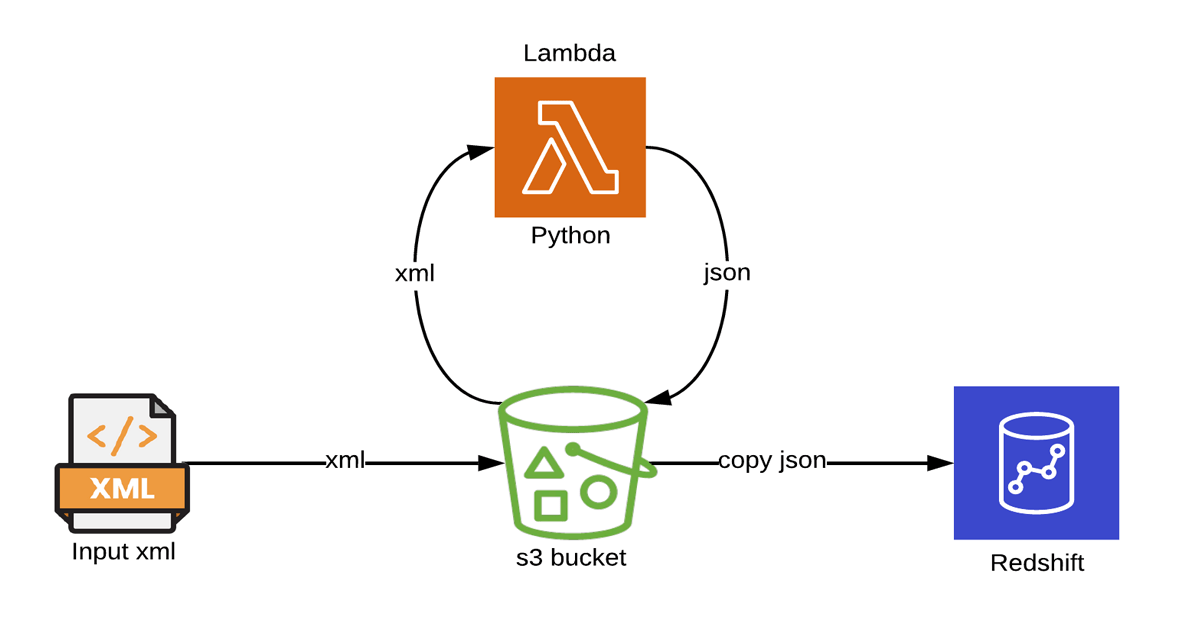
How AWS Redshift Works
AWS Redshift operates as a cloud-based data warehouse service, enabling users to efficiently store and query large volumes of data. Data loading is facilitated by various sources such as Amazon S3, AWS DynamoDB, or on-premises databases, with the COPY command allowing bulk data transfers from S3. Once the data is loaded, Query Execution uses SQL queries, leveraging Redshift’s Massively Parallel Processing (MPP) architecture—a hallmark of Modern Data Warehousing to distribute queries across multiple nodes for faster execution. Columnar Storage enhances analytical performance by storing data in columns, allowing quick retrieval of specific data fields and improving query efficiency. As data needs grow, scalability is easily managed by adding more nodes to scale horizontally for increased compute power or upgrading instance types to scale vertically for enhanced performance. Additionally, Query Optimization is supported through techniques like distribution and sort keys, which help reduce query times by efficiently organizing and distributing data across the cluster.
Benefits of AWS Redshift
AWS Redshift provides a variety of benefits that make it an attractive choice for organizations looking to perform large-scale data analytics:
Thinking About Earning a Master’s Degree in AWS? Enroll For AWS Masters Program by Microsoft Today!
Use Cases of AWS Redshift
AWS Redshift can be applied to a variety of use cases, including:
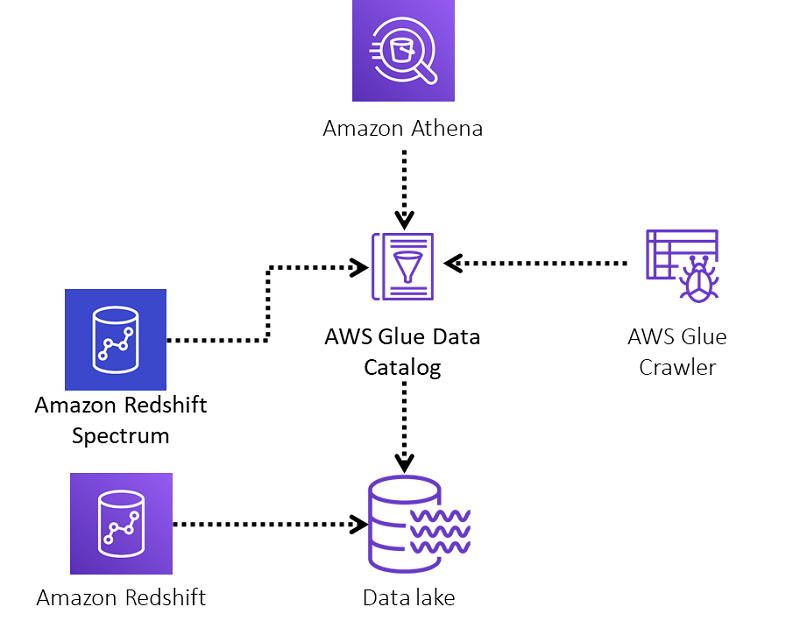
AWS Redshift vs. Other Data Warehouses
| Feature | AWS Redshift | Google BigQuery | Azure Synapse Analytics |
|---|---|---|---|
| Performance | Uses MPP architecture and columnar storage for optimized performance on large datasets. | Serverless; auto-scales but may have variable performance | Offers both provisioned and on-demand options; good for hybrid workloads. |
| Cost Efficiency | Flexible pricing (on-demand, reserved instances); cost-effective for varying business sizes | Pay-per-query model; can be cost-effective for sporadic usage. | Pay-as-you-go and reserved options; pricing can vary with usage patterns |
| Integration | Deep integration with AWS services like S3, Glue, Lambda, Kinesis. | Integrates well with Google Cloud services. | Integrates with Microsoft ecosystem, including Power BI and Azure ML. |
| Customization | Allows instance type selection and performance tuning for tailored environments | Limited customization due to serverless nature | Offers some control with dedicated SQL pools and scaling options. |

Pricing of AWS Redshift
AWS Redshift pricing is based on several factors, including the type of instance and the number of nodes in the cluster. The key pricing components include:
Selecting the appropriate instance type and pricing model can help you optimize your Redshift costs based on your business needs.
Preparing for Your AWS Interview? Check Out Our Blog on AWS Interview Questions & Answers
Best Practices for Using AWS Redshift
To get the most out of AWS Redshift, it’s important to follow a set of best practices that enhance performance, reduce costs, and ensure data security. When designing your tables, choosing the right distribution and sort keys is essential for minimizing data movement and improving query efficiency. Redshift also supports data compression, which not only reduces storage usage but also speeds up queries; analyzing your data and applying the appropriate compression encodings can lead to significant performance gains. Regular maintenance tasks like running the VACUUM and ANALYZE commands help keep your data sorted and statistics updated, enabling the query optimizer to make better decisions. Monitoring your cluster using AWS Cloud Watch, the Redshift Console, and built-in tools like the Redshift Advisor can provide insights into performance bottlenecks and help identify opportunities for optimization. To reduce costs and increase flexibility, you can use Redshift Spectrum to run queries directly on data stored in Amazon S3, which is particularly useful for less frequently accessed datasets. Security is also a key aspect—implementing encryption, using Amazon VPC for network isolation, setting up IAM policies for access control, and enabling audit logs are all critical for protecting sensitive data. Finally, integrating Redshift with AWS services like AWS Glue, Lambda, and Step Functions allows you to automate data ingestion, transformation, and orchestration workflows, making your analytics pipeline more efficient and scalable.
Conclusion
AWS Redshift is a robust, scalable, and cost-effective solution for handling large-scale data warehousing and analytics workloads in the cloud. With its high performance, seamless integration with AWS services, and fully managed nature, Redshift when complemented by AWS Training provides organizations with an efficient way to run complex queries and analyze data. Whether a small business or a large enterprise, AWS Redshift can help you gain valuable insights from your data while reducing infrastructure management overhead.




